前面第一堂課在介紹線性的SVM,透過二次規畫找到最大margin的支撐向量來建立更強健的模型。這堂課將會延讀svm並加上非線性轉換的方式,讓SVM不止可以控制模型複雜度,也能結合特微轉換來提高模型效果。

前面第一堂課在介紹線性的SVM,透過二次規畫找到最大margin的支撐向量來建立更強健的模型。這堂課將會延讀svm並加上非線性轉換的方式,讓SVM不止可以控制模型複雜度,也能結合特微轉換來提高模型效果。
機器學習技法是林軒田老師的開的機器學習後半堂課,主要在延續前面機器學習的基礎理論,並延申出不同的機器學習模型介紹。

上一篇提到一些基本的Feature Engineering概念與方法,這一篇則是會說明當要使用類別型的特徵來訓練機器學習模型時的技巧。

如果遇到類別型的特徵又需要拿進來訓練模型,則可以用one-hot encoding來處理。例如當今天要對商品銷售預測建立模型時,想要把員工拿進來考量,也許不同員工對顧客的服務上會影響到商品銷售。雖然員工的編號是數值,但其並不存在實際上數值的意義,這時候就可以透過one-hot來處理,並以多個欄位變數表示來將每個值轉成0/1表示的稀疏向量。
前陣子在上Coursera的Data Engineering on Google Cloud Platform這個系列課程,其中在Serverless Machine Learning with Tensorflow on Google Cloud Platform這週內有一個Feature Engineering單元,裡面展示了如何透過Feature Engineering來提升模型的表現。上完後覺得裡面提到一些關於Feature Engineering的技巧,決定還是找時間把筆記寫下來。

Python的collection模組裡面其實包含了許多非常實用的資料結構,比如之前介紹過的
namedtuple。今天要談的是Counter,Counter是一個dict的子類別,用來對hashable的物件作計算。
比如說我們今天要來幫公司裡面每個不同的team訂飲料好了,以下簡易一點不接受客製化調味,在建立Counter可以有以下幾種方法
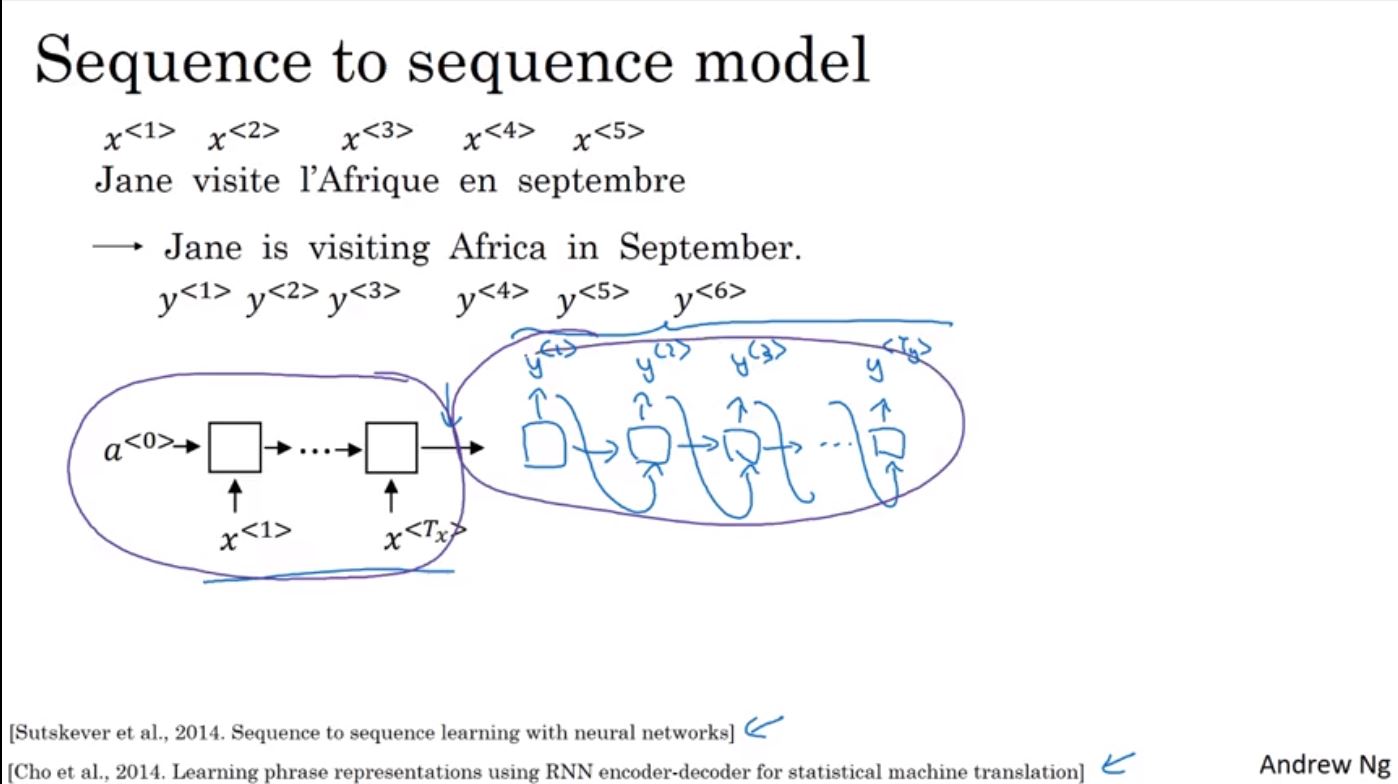
在RNN的應用中,有一種是sequence to sequence模型,像是在語言翻譯問題上,要把長度為5的法文翻譯成長度為6的英文。首先先透過一個encoder將每個法文字詞輸入進RNN模型,再透過decoder逐一輸出英文字詞直到結尾,這樣的模型被證實只要使用足夠大量的法文和英文句子就可以完成。
在上一週的課程中,我們使用了one-hot結合詞庫來將句子作量化處理。但是使用one-hot的缺點是每個詞被視為獨立的,也就是無法衡量出兩個詞之間的相似或與重要性(兩個one-hot vector內積都會為0)。所以當你想知道apple和orange之間的關係比起apple和king還接近,就無法單純的使用one-hot來作文字的量化。其中一個方法是可以用不同的特性來作量化,比如說使用性別、是否為食物等等的特性,這個時候便可以辯識出具有相同性質的詞。

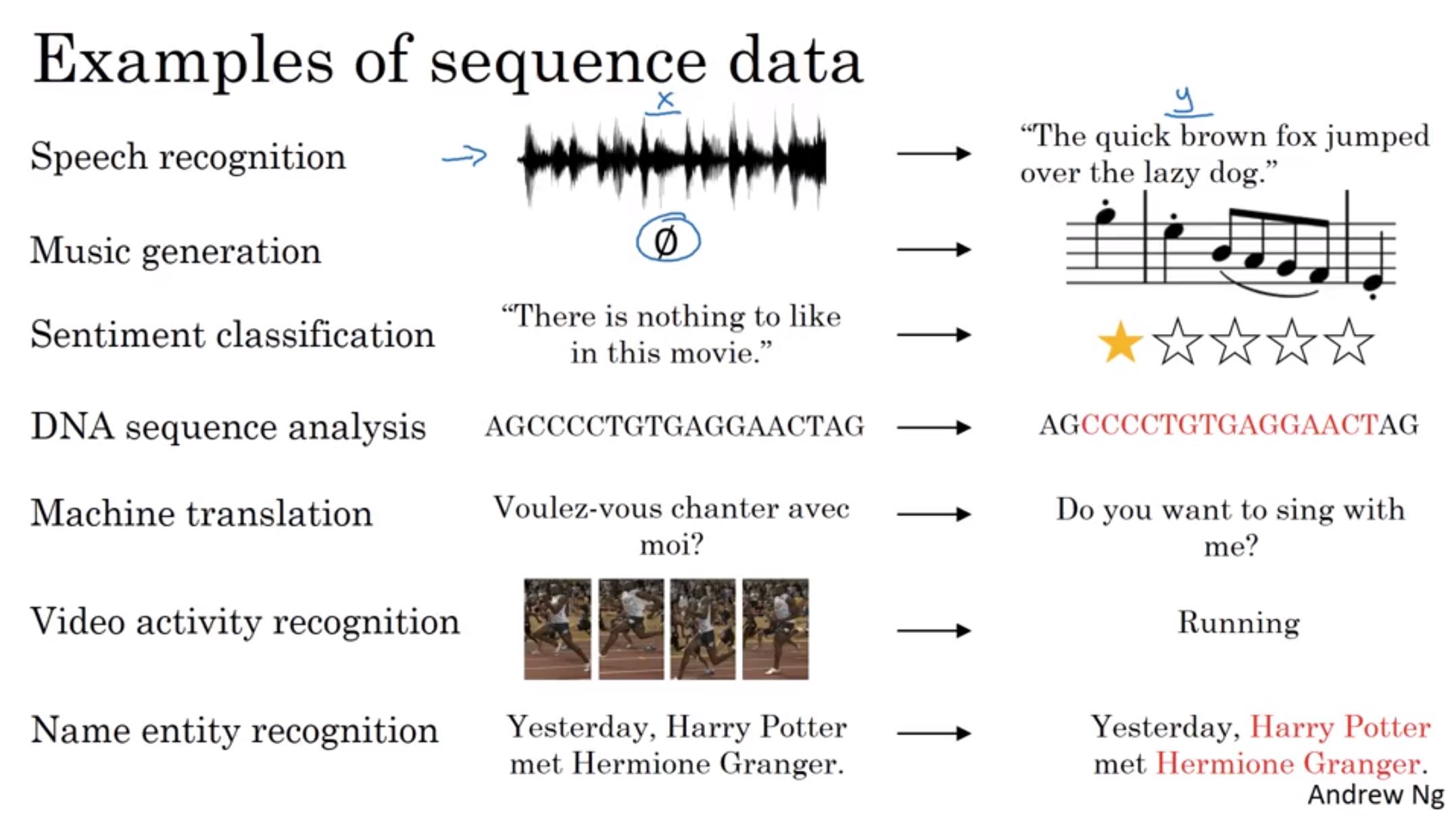
有序列性質的資料(sequence data)可以泛指輸入資料(X)是有序列的,或是輸出資料(Y)是有序列的。比如說在翻譯問題上,輸入和輸出都是有序列性的句子;但在情感分析問題上,輸入會是一個有序列性質的評論句子,但是輸出為情感的等級或是分數。
最近正在學習Andrea在Coursera上開的Deep Learning課程,之前工作關係有接觸到keras,而且使用起來還滿容易上手的,所以就嘗試拿了MNIST資料集來試玩看看
首先載入手寫辨識資料集mnist,這個資料集還滿廣泛被拿來使用的,而且在keras也可以直接載入,另外也會用到最基本的keras Sequential model。
上一堂提到validation的手法,透過留下用來驗證的資料模擬測試過程,並透過validation結果來選擇該使用什麼樣的模型。這一堂會提到三個在作機器學習時的小技巧。
