上一篇提到一些基本的Feature Engineering概念與方法,這一篇則是會說明當要使用類別型的特徵來訓練機器學習模型時的技巧。
Categorical

如果遇到類別型的特徵又需要拿進來訓練模型,則可以用one-hot encoding來處理。例如當今天要對商品銷售預測建立模型時,想要把員工拿進來考量,也許不同員工對顧客的服務上會影響到商品銷售。雖然員工的編號是數值,但其並不存在實際上數值的意義,這時候就可以透過one-hot來處理,並以多個欄位變數表示來將每個值轉成0/1表示的稀疏向量。

有時候在某些資料則可以當作連續型處理,也可以使用one-hot來處理。例如顧客的評分,如果你認為4分和2分是差距很大的,這時也可以依個人考量當作類別型處理。要特別注意的是,如果今天顧客沒有提供評分資料,在處理missing value上,第一種數值型的處理方法是使用另一個欄位來紀錄是否有收到評分(1/0),並維持評分值為0;第二種類別型處理方法則將所有one-hot變數設為0,並一樣透過另一欄位紀錄是否有評分,注意不要使用自己的特別編碼(magic number)來處理。
Feature Cross
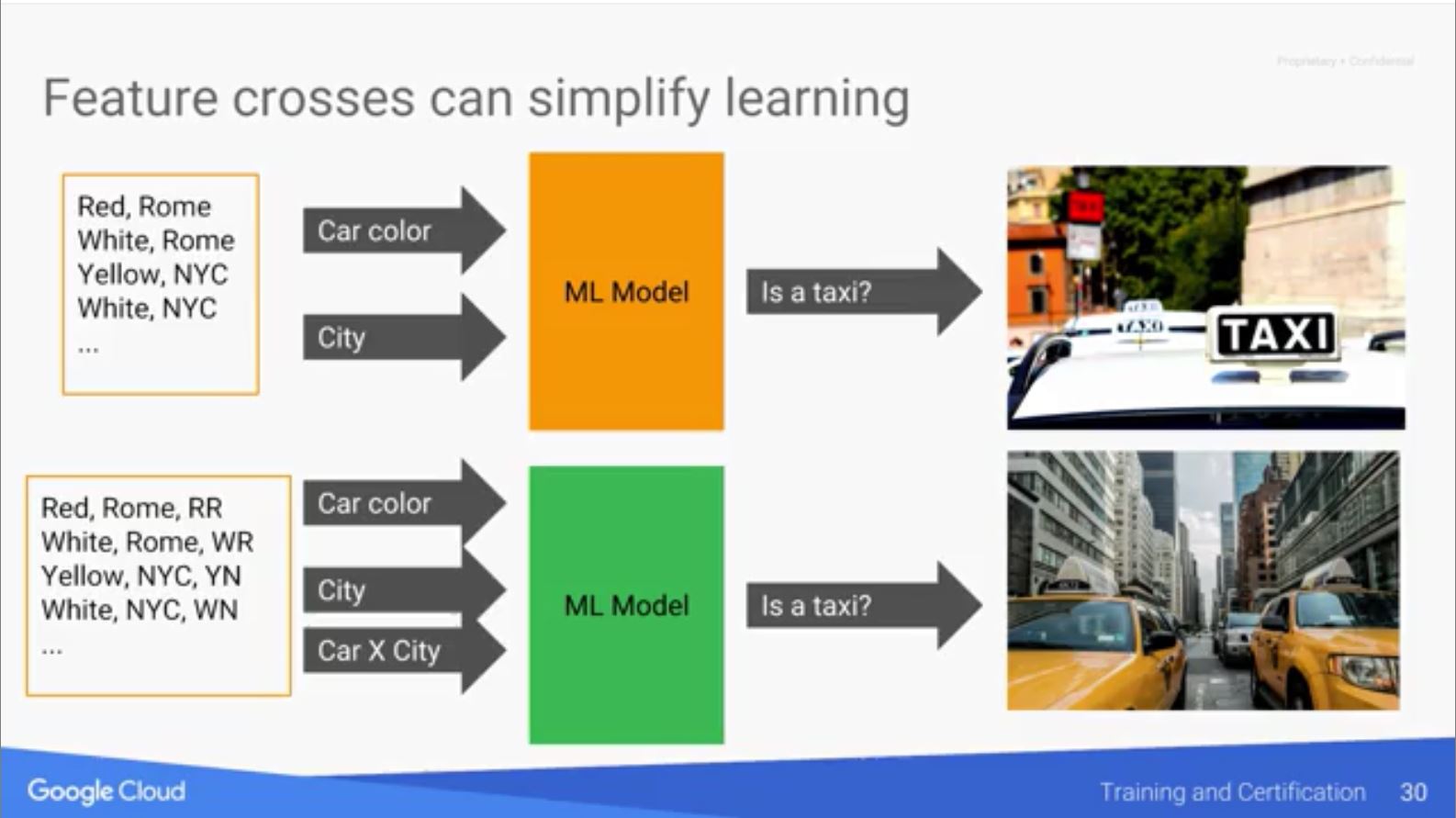
假設今天要建立模型來判斷車輛是否為計程車,而使用的特徵只有兩個,分別為車倆的顏色和車輛所屬城市。假設透過簡單的線性模型來作訓練,在調整權重的過程中,都沒辦法有好的辨識效果。因為模型在調整黃色和白色的權重時,當它看到黃色在紐約是計程車,提高了黃色的權重,但這反而造成所有黃色車倆比較容易判斷成計程車,這是不對的;相同的如果模型提高了紐約的權重,這也會造成所有紐約的車倆都容易判斷成計程車,這一樣是不對的。
這時候則可以嘗試將兩個變數結合變成第三個變數,並透過one-hot encoding來處理,而在訓練過程中就會將黃色X紐約的組合單獨調整權重,可以避開原本的問題。例如在預測計程車車資問題中,雖然知道在上下班時間的旅程時間會比較長,車資也可能比較高,但是這時可以不特別作新增rule的處理(例如標注某天的某時段為上下班時間),而是直接將Day of Week和24小時作feature cross建立組合。
Bucketize
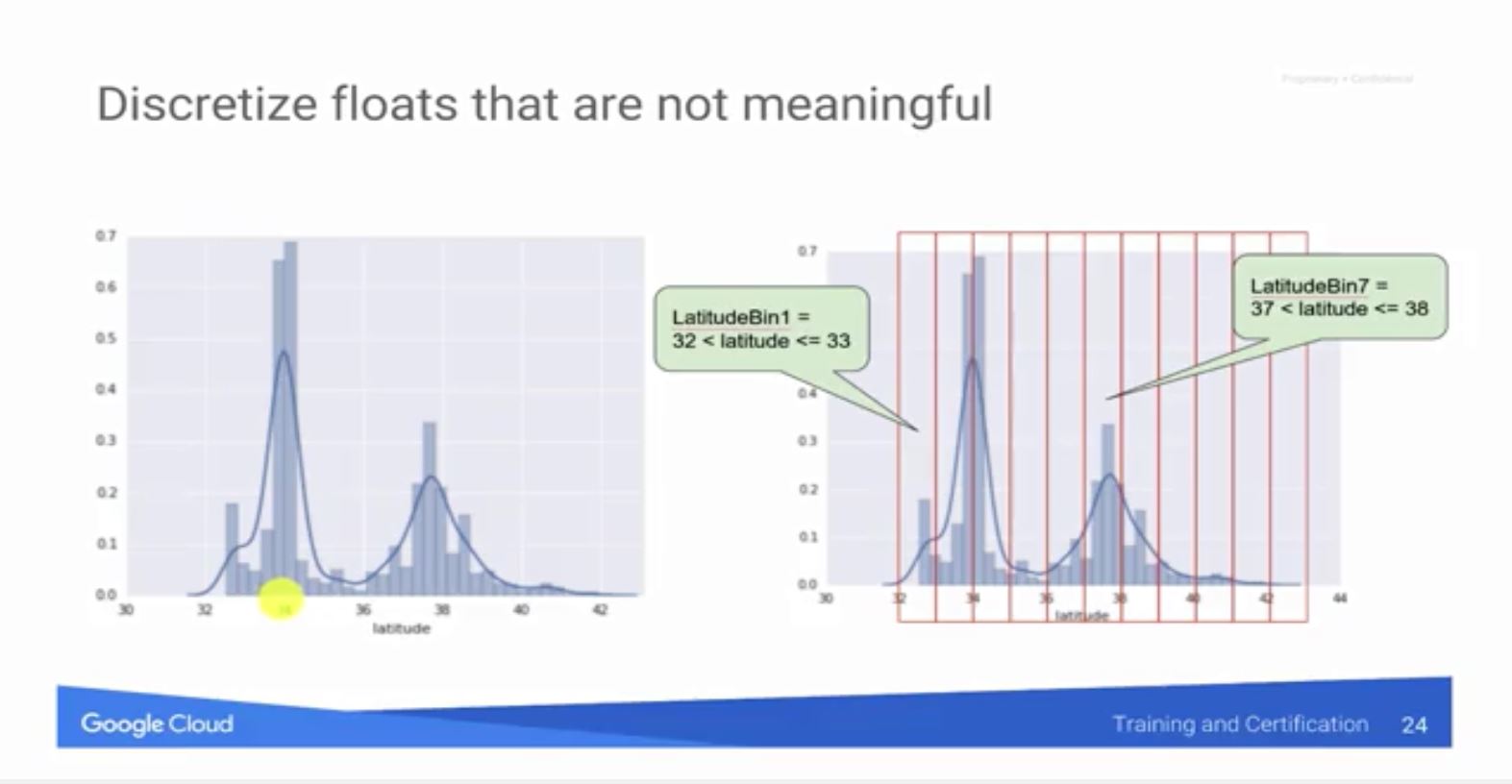
以加州的房價預測來說,如果觀察緯度這個特徵會發現有兩個高峰,一個是舊金山灣區,另一個則是洛杉磯大都市,這時就可以透過資料分群(bin)來拆成100個bucket,轉成類別型資料來訓練模型。注意在預測時也要透過資料前處理來將資料作bucketize。
Wide and Deep

到這邊就會遇到一個問題,在銷售遇到時會有價格和員工兩種不同特性的變數,價格是密集的(Dense)的連續型變數,而員工編號是透過one-hot產生稀疏(Sparse)的類別型變數。而在使用類神經網路訓練模型時,因為在0在乘上權重還是為0,所以稀疏的矩陣可能造成訓練過程中收斂在區域最佳解跳不出來。但是以上面說的計程車例子,其實線性模型是比較容處理的。
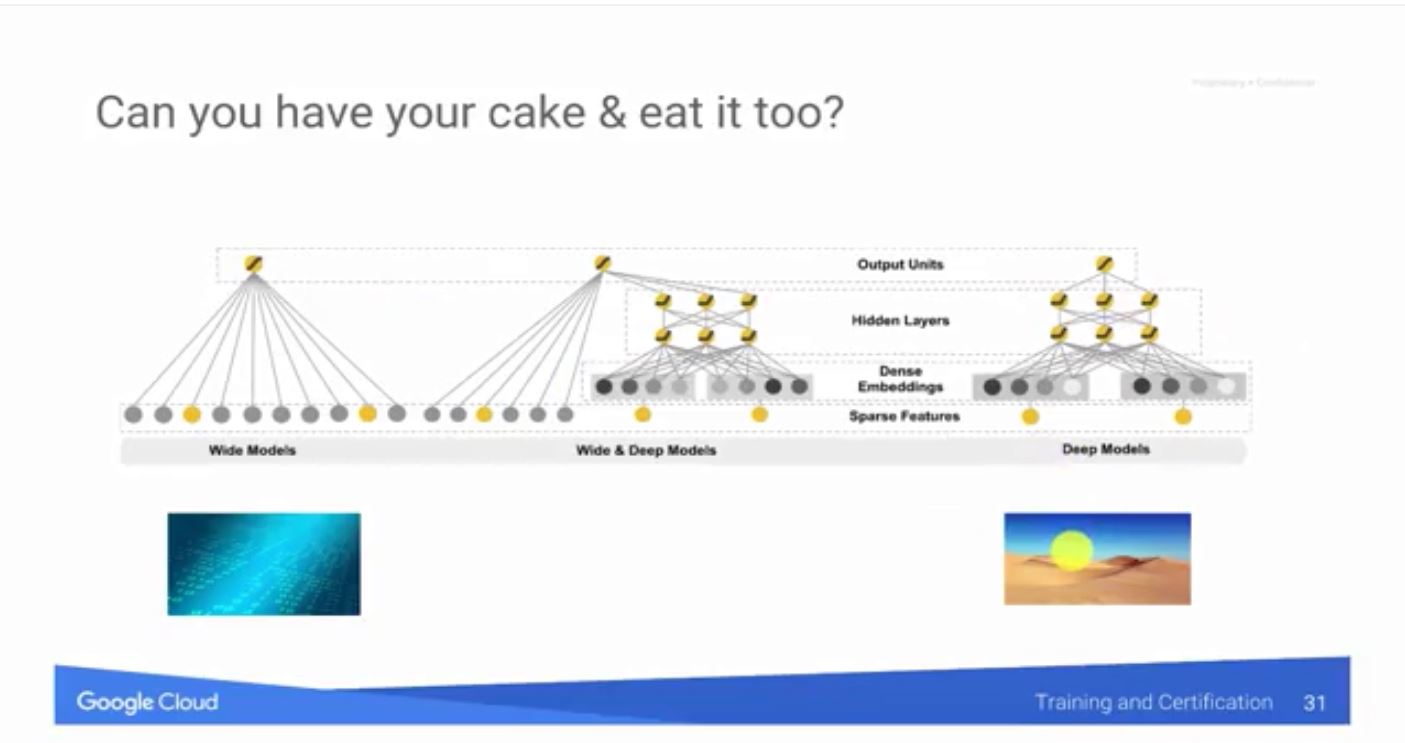
因此在訓練模型時,可以嘗試合併兩種方法,透過類神經網路來使用連續型變數訓練深度(Deep)結果,再和類別型變數透過線性方式串聯(Wide),這即是一個wid-and-deep架構的神經網路模型。