機器學習技法是林軒田老師的開的機器學習後半堂課,主要在延續前面機器學習的基礎理論,並延申出不同的機器學習模型介紹。

而這堂課主要圍繞在特徵轉換上並分三個面向探討,分別為(1)如果處理大量且高複雜度的特徵轉換(2)找出具有預測性質的特徵來提升模型表現(3)找出資料中的隱藏特徵讓機器學習表現更好。
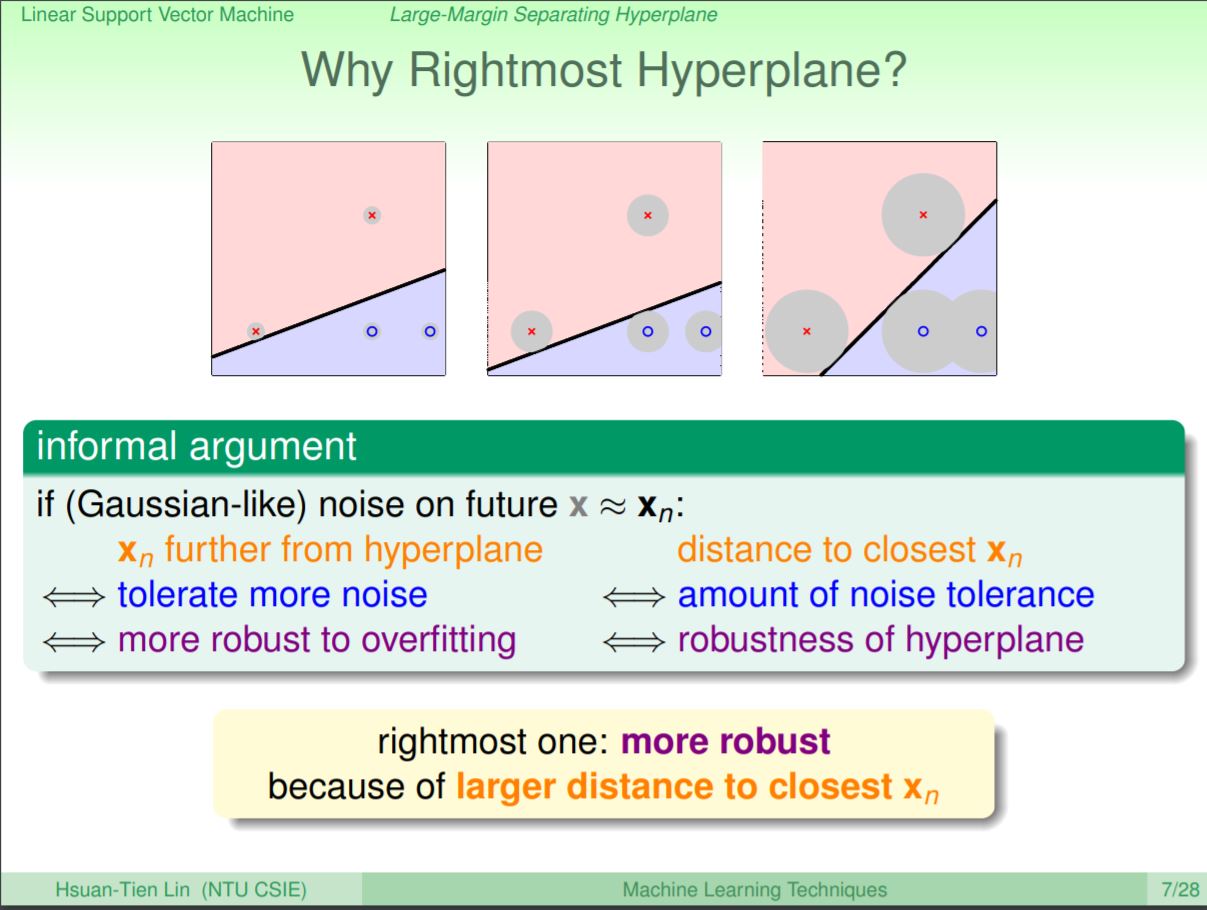
在線性可分的問題中,前面的課程有教過可以透過PLA或是POCKET來找到分開的超平面,但PLA在求解的過程中會得到很多種解,究竟怎麼樣的切線才會是比較好的切線呢?如果以雜訊的容忍度來看,當資料產生時可能會存在或多或少的雜訊(例如從實體感測器訊號收資料時,可能會有震盪或是偏移的現象),而雜訊是模型過擬合的因素之一。因此如果要讓模型對雜訊的容忍度最大,那麼就要讓超平面能夠離點越遠越好。例如最右邊的超平面能離點最遠,雜訊的容忍度(灰色區域)也最大。
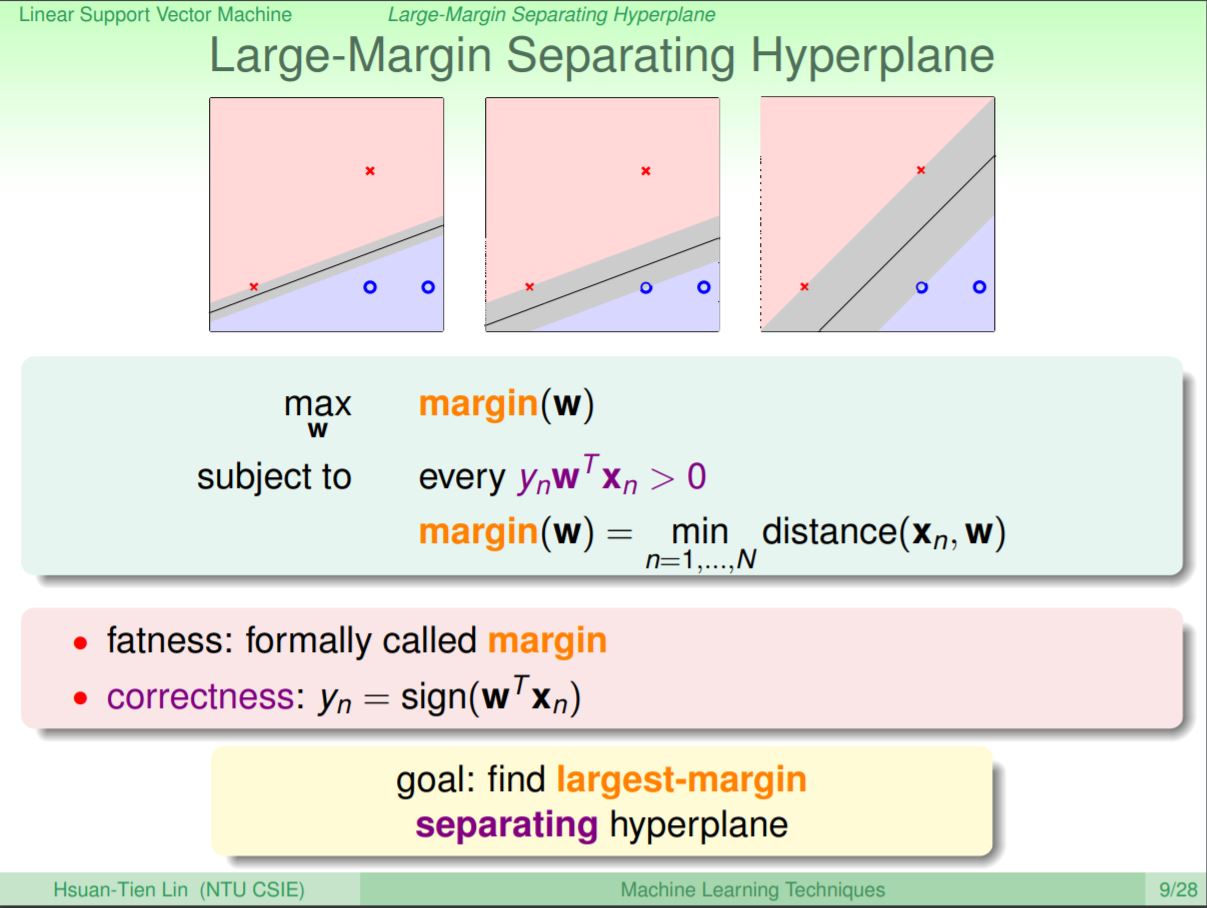
換個方式來,這會是一個最佳化問題,而最好的線須要滿足兩大條件: (1)能作出最大邊界(Margin) (2)可以把不同的類別分對。其中灰色區域的算法,是把每個點和超平面計算距離後取最小距離。
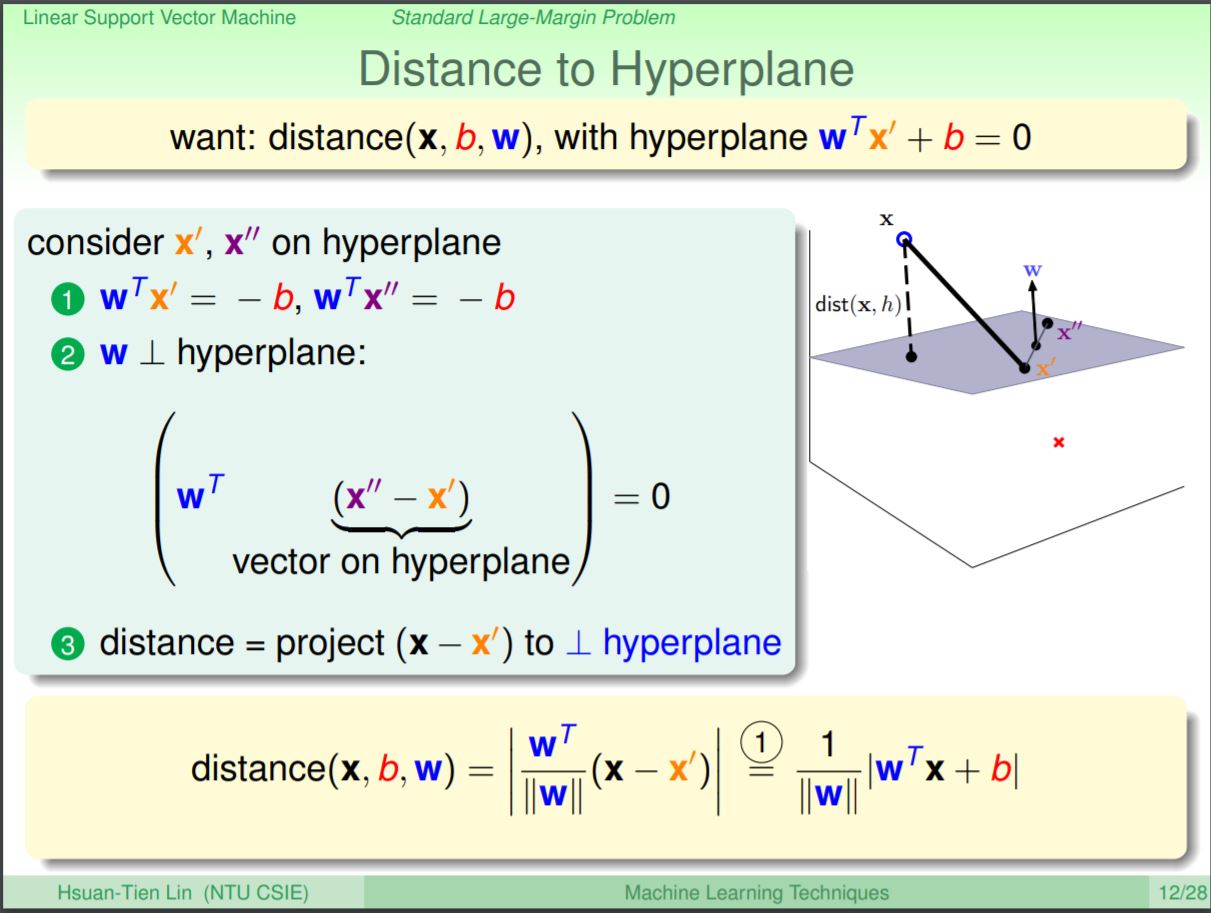
距離的計算方法,可以想像在平面上有兩個點構成的向量,而w乘上平面上的向量為0,所以w為垂直於平面上的法向量。當有一個x要計算x和平面的距離,即為x和平面上任一個點構成的向量,並對垂直於平面的向量作投影,即為對w方向的投影。

因為要找的是一個可以區分出正確類別的分割超平面,所以可以拆掉距離的絕對值,變成乘上y大於0(即為分割正確時值皆會大於0,如果類別分錯乘上y會小於0)

為了簡化式子,假設將式子放縮到最小值會等於1,那margin就會簡化為成1/|w|,並從求margin的最小值,變成分數乘上y的最小值要等於1。而且因為其條件已經滿足大於0,所以可以再拿掉一條分數乘上y要大於0的限制式。

為了再簡化限制式條件,限制式條件可以再從最小值為1,放寬為分數乘上y大於等於1,而且這個放寬並不會違反原本的限制式。老師這裡舉了一個例子,假設找出來的解為大於等於1.126並且不滿足等於1的條件,這時候如果把b和w除上1.126作放縮讓他滿足原本的條件,會因為w變小而使得目標式變大。這個證明在說如果找出來的解不滿於原本等於1的條件下,就不會是最佳解,因此可以對限制式條件作放寬。最後再將最大化的問題轉為求最小值(倒數),得到最後的簡化的最佳化問題。
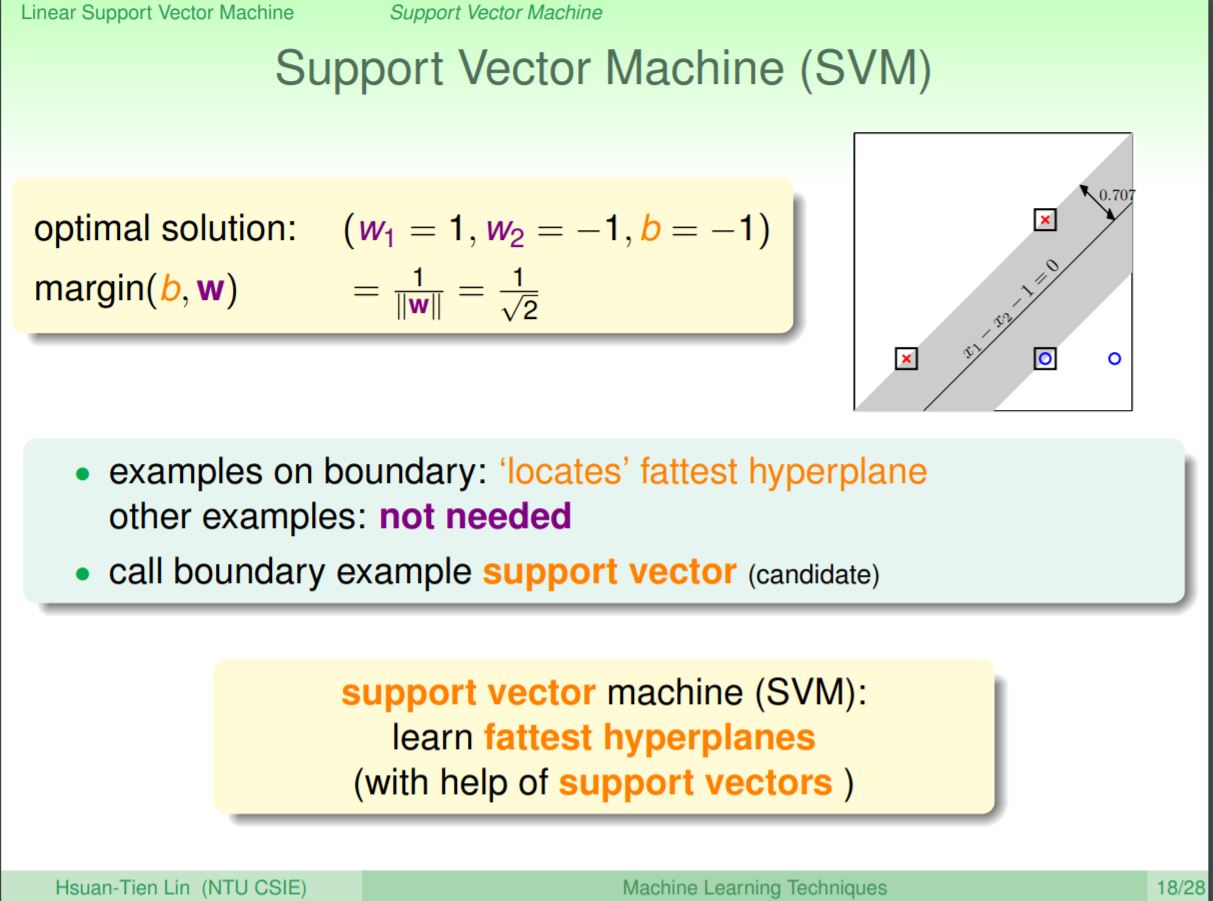
如果要找到最佳的平面,只要找到最靠近平面的點就行了,而這些點被稱為支撐向量(support vector),就像是這個超平面是由最靠近的點所支撐起來般,這也是SVM的概念。

因為svm要找到的最佳值是w的兩次函數,且限制式為b和w的一次式,有這樣的限制非常適合使用二次規畫作最佳化。

但為什麼svm可以作的好呢,老師這邊以兩個面向來說明使用svm會讓Ein和Eout越接近,且不容易overfit泛化性更佳。
之前在提到regularization的時候講到,為了讓Ein越小但又不希望造成overfit,於是加上w的限制條件限制其範圍。而svm剛好對調,svm是要讓w的長度越小且限制讓所有的類別的資料分對,所以svm和regularization是一體兩面,svm找出來的灰色區域讓為了容忍雜訊對模型的干擾。
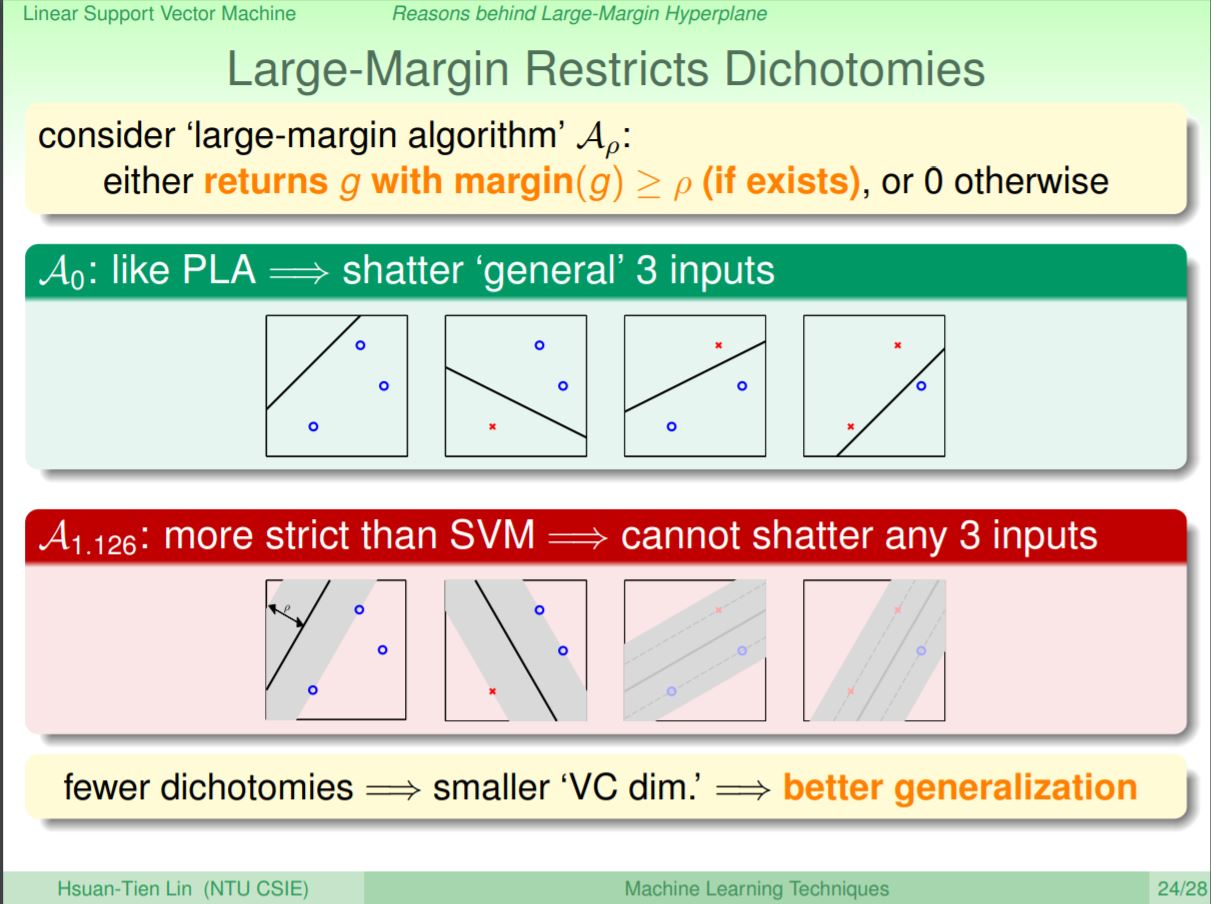
假設平面上有三個點,如果是原本的pla,在任意切線上可以找到所有的類別組合(共八種)。但使用svm考量到需要維持最大特定margin區域情況,所以沒有辦法作出所有的類別排列組合。在vc維的介紹有講到,如果能作出的dichotomies越少,vc維就越小,Ein和Eout就會越接近,即泛化能力越好。
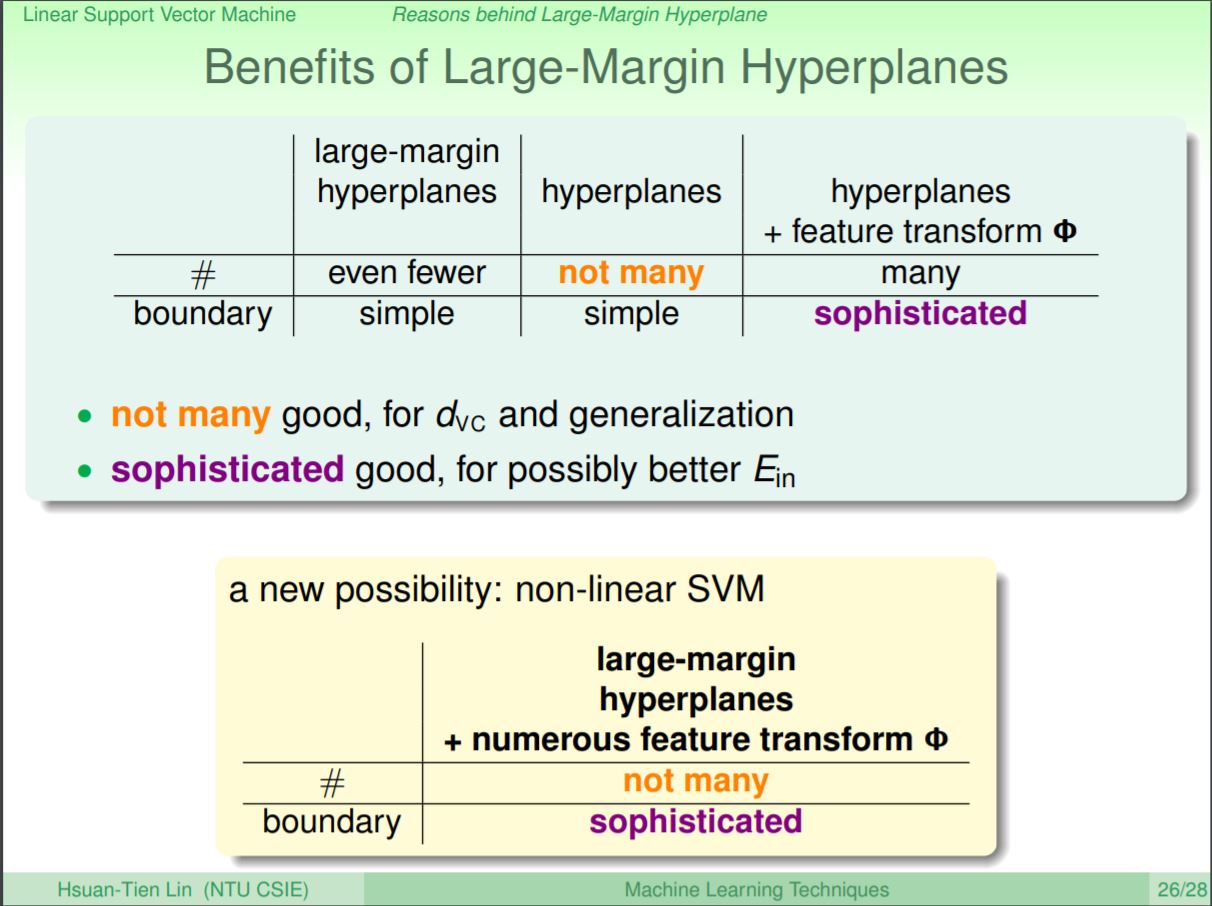
從上面兩個面向來看,svm可以帶來本質上泛化性更佳的好處,並且在加上特徵轉換的方法後,non-linear的svm可以同時辦到將Ein(即分對不同類別)與Eout(泛化能力)作好。

這一講主要在說明如何從邊界分類問題延申出最大margin提供更強健的方法來容忍雜訊,並作svm最大margin的最佳化式子推導,最後提到最大margin帶來本值上的好處在於可以提高更佳的泛化能力。