前面第一堂課在介紹線性的SVM,透過二次規畫找到最大margin的支撐向量來建立更強健的模型。這堂課將會延讀svm並加上非線性轉換的方式,讓SVM不止可以控制模型複雜度,也能結合特微轉換來提高模型效果。

假設透過特徵轉換的方法將SVM轉為非線性,原本的x會被轉換到z空間,但又希望可以在解SVM最佳化問題時,能夠擺脫轉換到z空間高維度的依賴。即將非線性轉換轉成另一個對等問題,不管轉到幾維的空間,都只會有N個變數,變數數量不會和要轉換的維度的有關,這稱為原本SVM的對偶問題(dual problem)。
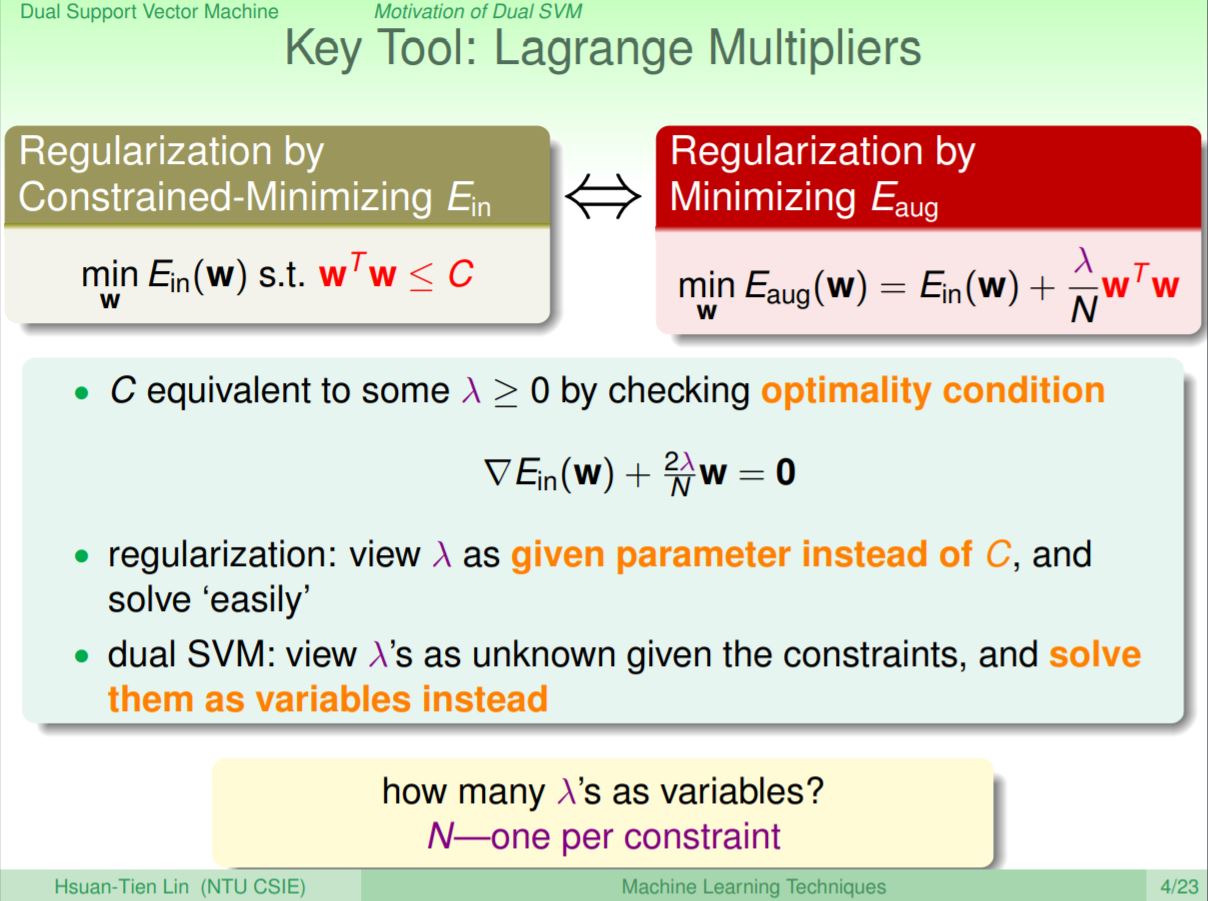
之前篇章在介紹regularization時,引入了Lagrange Multipliers的概念,將原本帶有W長度小於C的限制式,轉成加上Eaug後求最小值,其中λ會被乘上每個系數加進最佳化式子中。因為SVM也是一個有條件的最佳化問題,但是在引入λ時有別於regularization中被當作給定值,在SVM中會被當作未知的值來解最佳化問題。

為了把原本有限制式的SVM最佳化問題,在引入Lagrange Multiplier後轉成沒有限制式的問題,會將限制式移項乘上α(即λ在SVM文獻為α)後相加。但是將有限制式的最佳化的問題,轉成沒有限制式的最佳化的問題,是否能夠得到一樣的結果?老師在這裡舉了兩種例子來說明其實會得到一樣的結果。假設選到一組會違反原本限制式的B,W(即α乘上的項次會是正值),這種最終會在解最小值SVM問題時被逃汰;相反的,如果選到一組符合原本限制式的B,W(即α乘上的項次會負值),這種解反而在最後會被留下來。因此將限制式轉益沒有限制式的最佳化問題,其實只是把限制藏進求最大值的最佳化中。

在轉成無限制式的最佳化問題後,會發現假設在固定α之下,整個最佳化得出來的值會比任一的Lagrange值還要大,甚至取完最大值右邊的不等式也一樣成立,這個min和max互相交換稱為lagrange dual problem。

對於二次規畫,這個duel problem因為滿足強對偶關係,因此求出來的b,w,α值對於左右兩邊的式子都是最佳值,因此可以將原本左邊的最佳化問題,直接轉成解右邊的對偶問題來求最佳值。

再進一步化解最佳化問題,如果要得到內部式子的最佳值,因為其為無限制的最佳化問題,因此最佳解會產生在梯度為0,即內部式子微分為0。首先對b微分後加進原本的式子,因為加進去的條件值為0時為最佳解,所以不止不會影響原本求出的最佳解,也可以同時去掉b這個項次。

再來對w微分後加進原本的式子,可以將w轉換成α.y.z相乘,在去掉w項次後,也不需要對原本的w取最小值,並轉成一個只有對α作最佳化的問題,得到簡化版的對偶問題。

前面有提到如果要滿足對偶問題,即b,w,α的解對於左右兩邊的最佳化問題都是最佳值,需要滿足特定條件,這稱為KKT最佳化條件,再會來透過這些條件來解最佳的b,w。

再來先乘上-1先將最大值問題轉成最小值問題,再把平方向解開後,就可以將每個條件丟進QP來解出最佳值。

如果今天在滿足KKT條件下要找到b,w的最佳值,首先要找到最佳的w,因為只有一條條件和w相關所以很容易找到最佳值。在找最佳的b時,共有2個條件和b相關,在第2個條件可以發現如果在α大於0的情況下,y(W.z + b)即需要等於1才能滿足條件,而這個值就是原本要找的最佳解,因此在解對偶問題時,可以同時找到SVM的支稱向量。

既然證明在α大於0的情況下,可以找到支撐向量,相反的回到原本的SVM概念,其意義在於如果可以知道有哪些支稱向量,就可以找到最大的margin,其他的點皆可以不管。

SVM和PLA其實很相似都會找出區分不同類別資料的超平面,差別在於兩者著重的點是不同的,SVM是著重在使用支稱向量表現出來,而PLA是使用分類錯誤(犯錯)的點表現出來。

上一講介紹的原始SVM為Hard-Margin SVM,透過求特定放縮後的b,w最佳值,他和要轉換的空間維度有關,適合維度較小的問題;而這一講的SVM是引入Lagrange的SVM,透過找最佳的支稱向量和α來重構邊界,並且和資料量的大小有關,適合資料量小的問題。

但到目前為止仍然沒辦法完全擺脫處理高度空間維度轉換的問題,因為在QP求Q矩陣時,仍會碰到z向量內積的問題,z向量的維度等同於目前要解的維度。

這一講提到透過對偶問題來移除對d維度的依賴,並引入Lagrange與KKT條件,透過QP來解出最佳值,並發現解出的最佳值就是支稱向量,並可以用來建立最大margin。下一講將會說明如何真正擺脫和d維度相關的計算。