
上一講說明了dual SVM,好像可以讓SVM與高維度的z空間兩者可以脫鉤,但以計算的角度,仔細看會發現在整個求解過程中的Q矩陣還是會在z空間作內積。而在z空間的內積在運算可以拆成兩個部份,一個是先透過某個函式φ轉換到z空間,第二再進行轉換後的內積。但這樣的運算方法就會變成z空間的維度作內積。

透過這個polynomial transform可以發現,其實是能先在x維度作完內積,再作函式φ的轉換,這樣就可避免產生在z空間作內積的情況,透過這個簡化的方式計算內積稱為kernel function。

回到svm不管是在計算b和最佳的超平面gsvm時,都可以將kernel function應用在計算中。這種合併函式轉換和內積計算,來避免在在高級度空間進行內積計算的方法,又稱為kernel trick。

延續前面的Poly-2 kernel例子,在每項前面再加上不同的係數,就能再對計算進一步簡化。雖然不同的函式都是轉換到相同的維度,但是會計算出不一樣的內積得到不同的距離,所以得到的幾合意義和算出來的SVM margin也會不同。其中最常使用的kernel為加上根號2與γ值的General Poly-2 kernel。
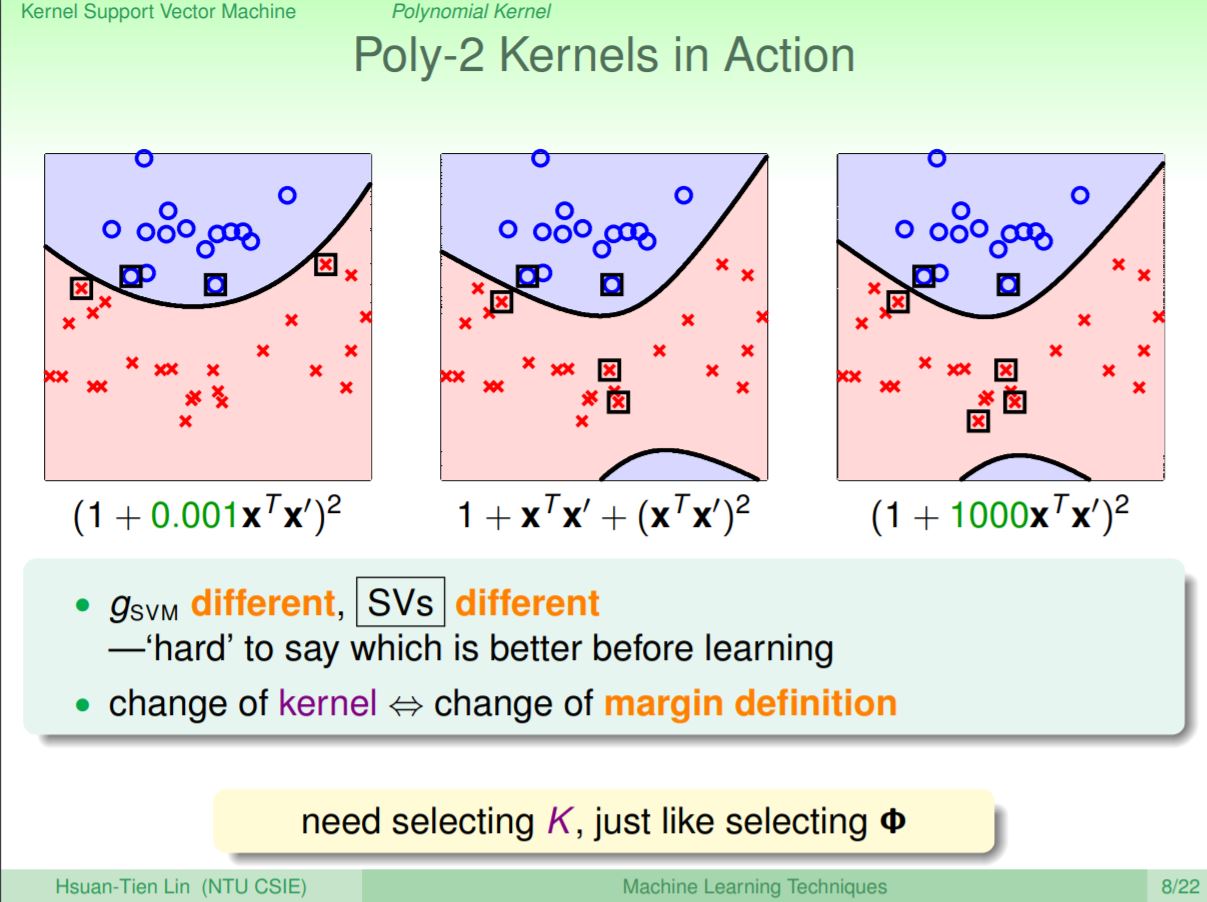
舉例來說,中間為原本的Poly-2 kernel,而左右兩個為General Poly-2 kernel但代入不同的γ值,左邊帶很小的γ右邊帶很大的γ。可以看到得出的邊界是不同的,所以得出的支撐向量也不同(方框的點)。雖然三個kernel的邊界不同,margin的定義也不同,但這邊沒辦法說哪個邊界會比較好,因為三個kernel都可以把點分開。

前面提到的Poly-2可以再加入ζ參數,就會形成一個包含3個參數的一般型態Polynomial Kernel,包含了(1)γ控制x內積算完後的放縮程度,和(2)ζ控制常數項與乘上轉換係數如何對應(3)Q代表poly作幾次方的轉換。而且不管作了幾次方的轉換,都是透遇kernel而不會在高維空間計算。使用高次方的轉換仍然可能會有overfit的風險,但SVM會透過找到最大margin來避免overfit,所以透過kernel可以讓SVM達到避免ovefit,又可以使用較複雜的模型,同時不需要高度的計算複雜度。SVM結合polynomial kernel又稱為Polynomial kernel。

Polynomial kernel如果設定成1次轉換,γ設成1,ζ設成0的話,就等於是原本的linear kernel SVM。老師建議大家在使用SVM時,可以從linear SVM開始,如果linear就可以解決問題,就不需要作高次方的nonlinear轉換。

既然可以透過kernel trick來達成高維度轉換的運算,那是否有可能作到無限多維轉換呢?老師這裡透過證明可以發現,即使在無限多維的情況,使用高斯函數作轉換是可以辦到的。

所以高斯函數也是一種kernel trick的方法,讓資料映射到無限多維的空間後找到支撐向量和超平面。但其實際上的意義為他會產生以支撐向量為中心的高斯函數的線性組合,也常被稱為RBF(Radial Basis Function) kernel。
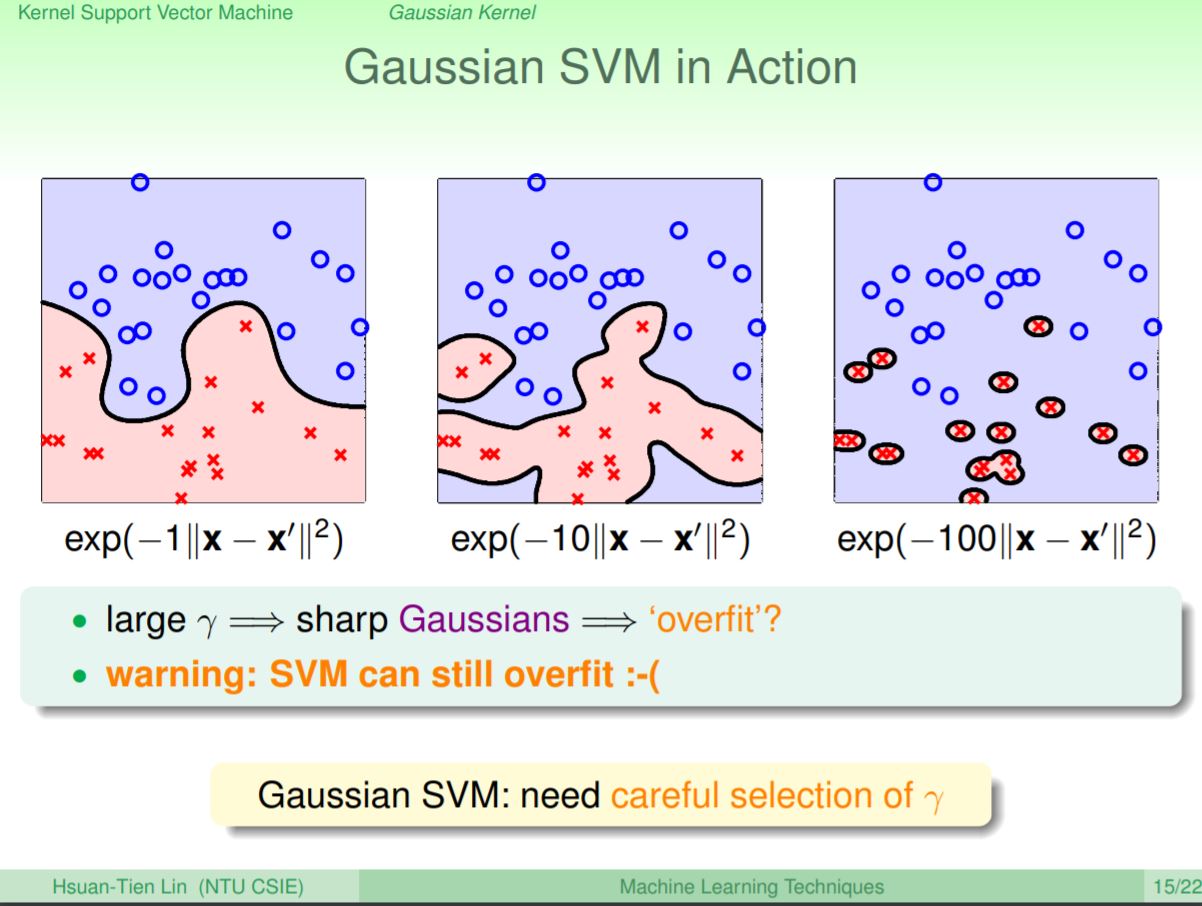
到目前為止,SVM可以辦到使用kernel trick作無限多維的轉換後,再透過最大margin找到超平面,而SVM裡面的最大margin計算,可以對無限多維的轉換有一定程度的保護。但要注意SVM仍然會有overfit的問題,當γ越調越大時會使原本Gaussan裡面的σ變小Gaussian就會變尖(γ=1/2σ^2),所以還是要小心γ參數的選用會決定SVM的表現,通常不建議使用太大的γ值。
前面介紹到許多的kernel,不同的kernel也有其好處和壞處
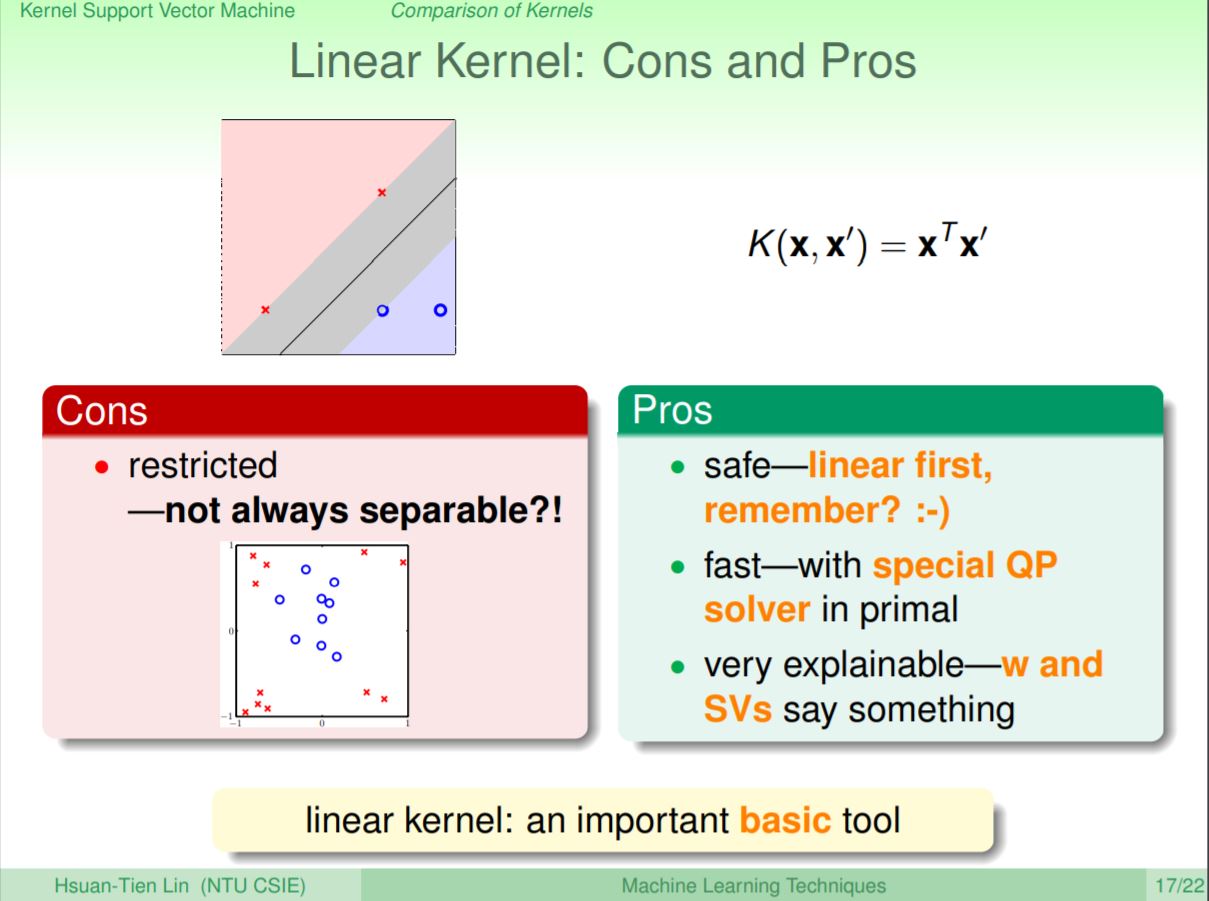
- Linear Kernel
最簡單的kernel,就是不作任何的維度轉換,其好處就是最簡單安全。除了QP好解之外也具有可解釋性,因為是線性所以可以透過每個特徵的權重來看出特徵的重要性,應該是遇到問題時要先被拿來嘗試使用的kernel。但其壞處在於問題如果是非線性的,那只靠線性沒辦法很好的解決問題。

- Polynomial Kernel
Polynomial的好處在經過非線性轉換後,會比linear限制還要少,而且可以透過設定Q來限制模型的維度。缺點在於Polynomial有3個要給定的參數較難選定,而且在計算值時QP不容易解,尤其是γ過大的時候,因此Polynomial比較適合用在心裡有假設而且使用比較小的Q。

- Gaussian Kernel
Gaussian可以作到無限多維的轉換,所以會比Linear和Polynomial使用限制更少。而且Gaussian的數值會落在0到1之間,所以數值計算難度較低;又因為Gaussian只有一個參數要給定,比起Polynomial要選3個參數,Gaussian可以更容易作參數選擇。Gaussian的壞處在於被轉換到無限多維後,模型沒辦法容易的被解讀;另外他的速度會比單純使用線性還要慢,又因為轉換較複雜,因此使用的不好會造成overfit。

Kernel表示一種特徵的相似度,但是不是任何相似度都能用來當作Kernel呢?這邊老師給出必須要滿足對稱性還有postive semi-definite兩種條件才能當作Kernel。

這一講提到了如何透過kerlnel trick快速計算轉換和內積,避開最複雜的計算,另外也比較了不同的kernel的優點和缺點。