
上一講教了透過kernel trick來處理dual SVM中的轉換與內積,並介紹了不同的kernel function,從線性到無限多維轉換的Gaussian,但SVM還是有可能會overfit。overfit有兩種可能的原因,第一種為使用了過度複雜的轉換,第二種則是堅持要把所有資料完全的切分開來。以上面這個例子來說,如果可以容忍有錯誤分類,但可以使用簡單的線性切分也可以得到不錯的邊界;相反的,如果使用比較複雜的轉換確實完美的將資料都區分正確,反而容易造成overfit。

但該如何解決這個問題呢?之前在講pocket演算法時,pocket會找到能分錯資料最少的超平面,但hard-margin SVM除了要求要全部分對之外,還要選w長度最小的超平面。所以如果可以讓SVM也能像pocket一樣容忍一些錯誤,即不管部份分錯的點,就能達到某種程度的條件放寬。這邊引入C參數來代表放寬條件的相對重要性,C較大時代表越重視不要犯錯越好,C越小時代表越重視w長度,即分對的資料的margin越寬越好。

但放寬後的新問題將會違反QP的條件(min為二次式,條件要為一次式),而且在允許犯錯的情況下,沒有辦法分辦到底犯錯的嚴重程度(小錯或是大錯)。為了解決這兩個問題,引入ξn來紀錄離想要的值(是否靠近1)有多近,即將犯了幾個錯誤轉成犯了多大的錯誤。除了可以解決無法分辨犯錯程度的問題,也可以讓問題符合QP。

如同前面說的,C可以用來控制large margin和margin violation,越大的C代表越重視分類的正確性,而越小的C代表margin可以比較大,但會造成某些資料分錯。
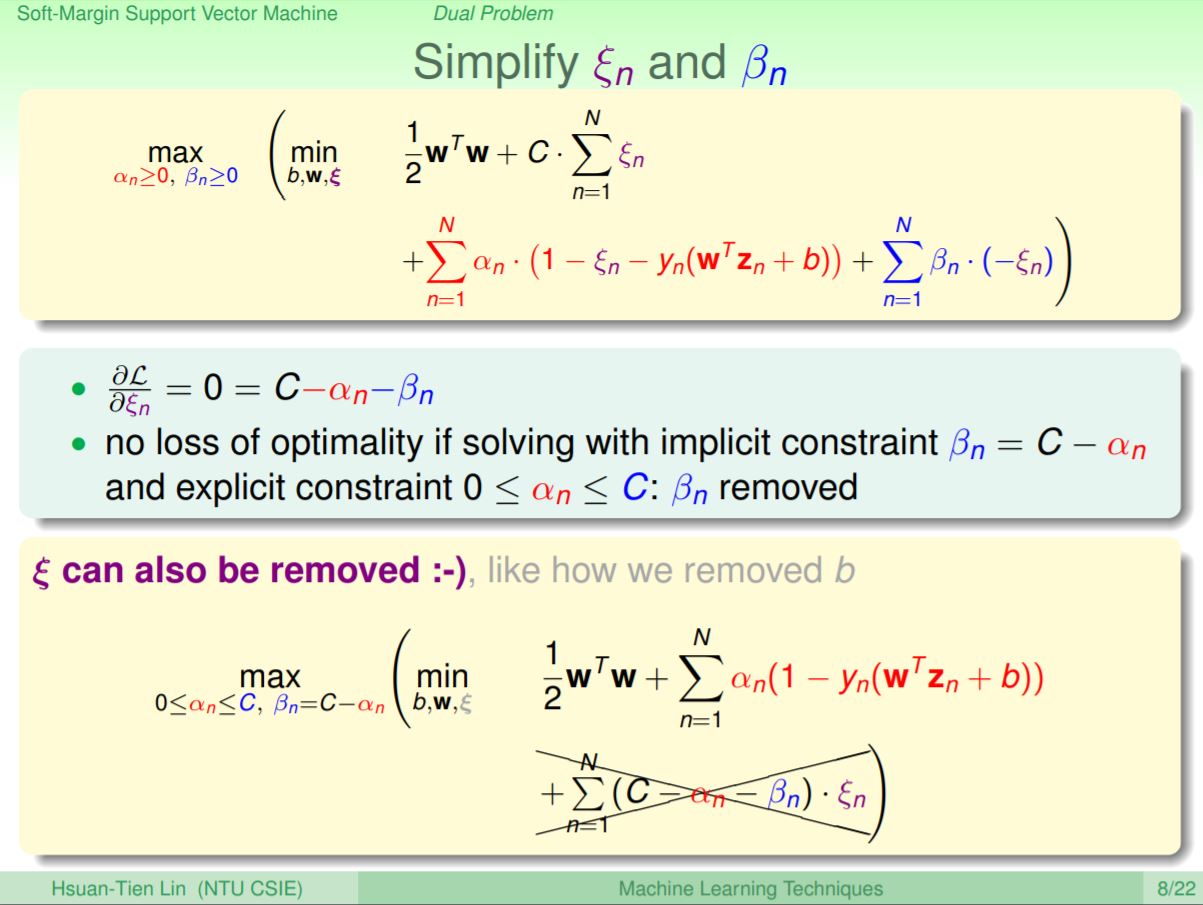
當我們將Hard-Margin轉成Soft-Margin後,再來就是將它轉成對偶問題,就可以如同Hard-Margin一樣引入不同不同維度轉換的kernel function。第一步就是帶入Lagrange,有別於原本的Hard-Margin只需要帶入一個α,因為這邊分成兩個部分,因此分別帶入α和β。再進一步將ξn作微分拿掉ξ,可以發現在最佳解的位置C會等於αn+βn,就可以將βn簡化成C-αn,又因前後兩項分別都有C-αn互相消掉,所以可以再將式子簡化。

到這邊可以發現內部要解的問題其實就和之前的Hard-Margin SVM相同,只差在外面的條件帶入了C的限制,所以這邊可以和之前一樣分別對b和w作微分來得到Soft-Margin SVM的對偶問題。

再仔細看一下Soft-Margin SVM的對偶問題,可以發現和Hard-Margin SVM的對偶問題幾乎一樣,只差在現在α會有一個上限值C,而這個C是來自引入β後得到的。
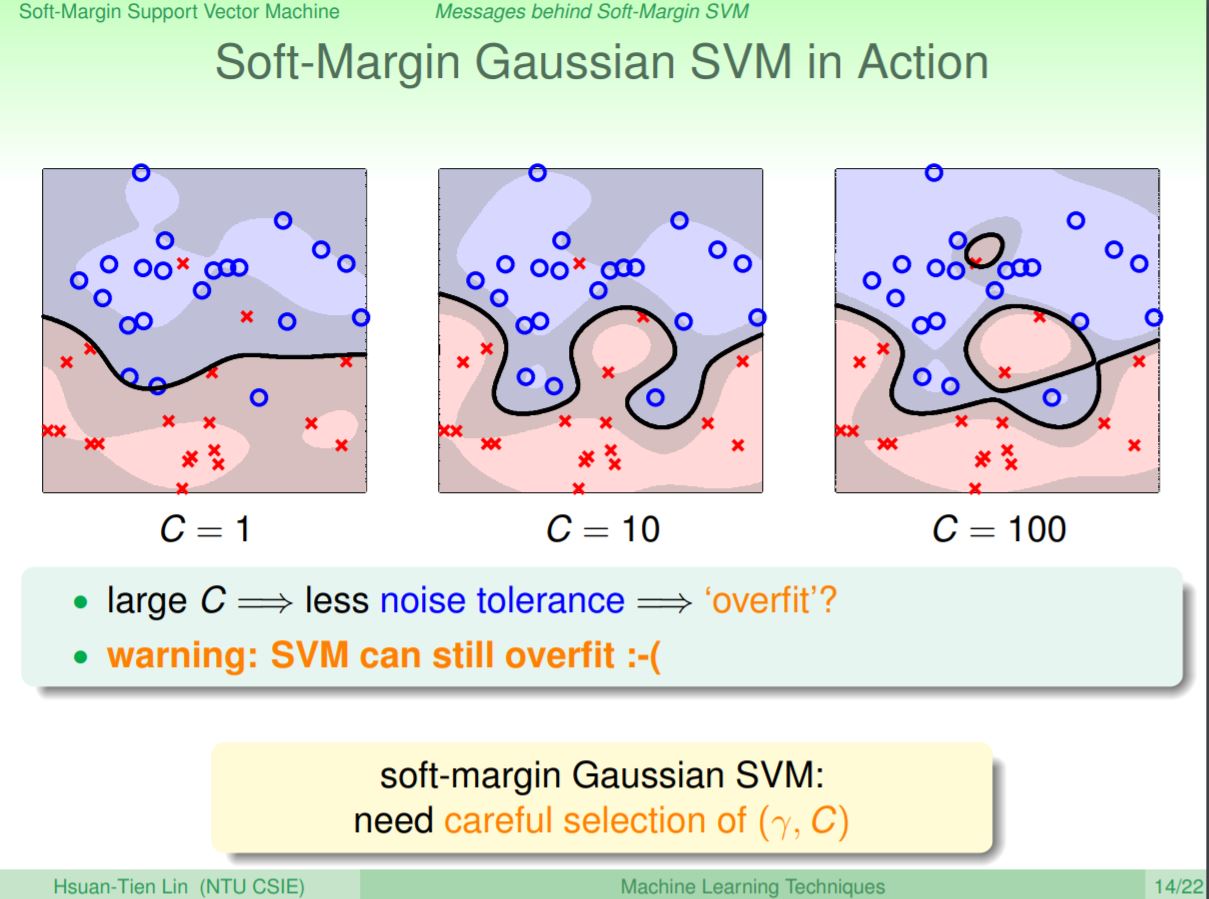
當我們把Gaussian SVM用在Soft-Margin上並調整不同的C值時,可以發現最左邊當C設成1的時候,會得到一個邊界但有部份的資料是分錯的;當C一直調到到100可以發現邊界會越來越複雜,但是分錯的資料會越來越少。其中最右邊的邊界雖然可以讓所有的資料分對,但也可以造成雜訊的容忍度下降,也就是容易造成overfit,因此C和γ值需要慎選。
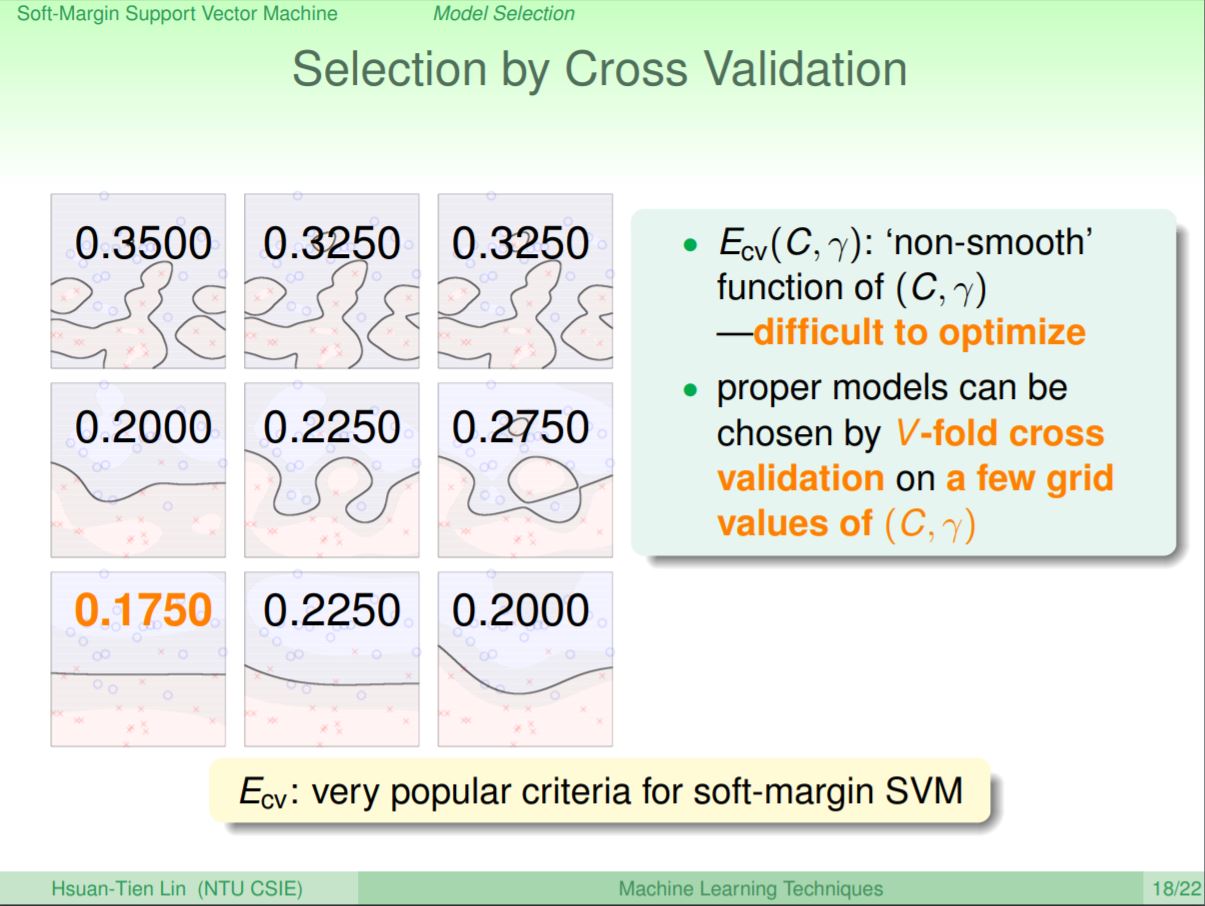
介紹完Soft-Margin和kernel,參數該怎麼選呢?第一個方法可以嘗試使用cross validation的方式,並帶入不同的C和γ值來找到比較好的參數組合。
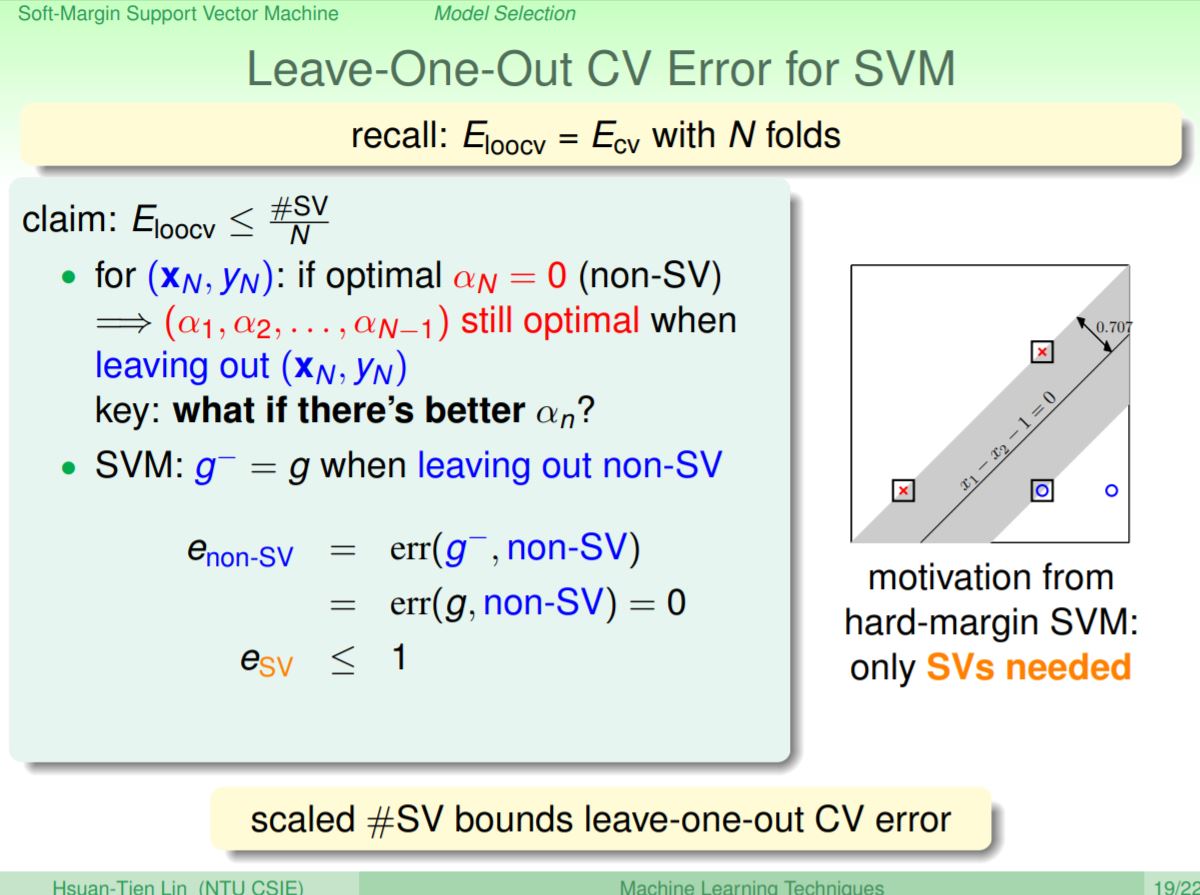
另一個有趣的方法則是使用Leave-One-Out CV,SVM在使用Leave-One-Out CV的error會小於等於support vector的比例(support vector的數量除上所有樣本數),其概念為即使少了non support vector(non-SV)的點,結果並不會影響到margin的計算。
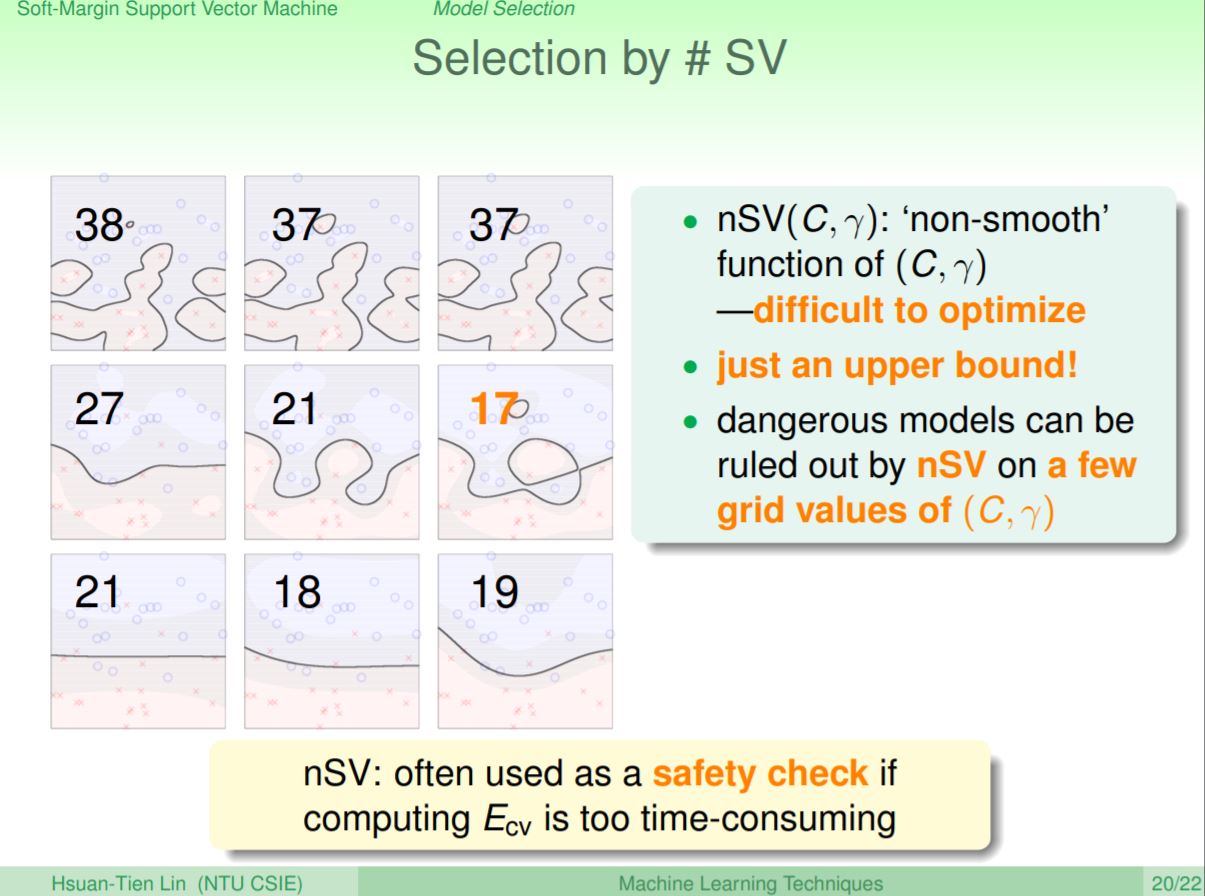
所以也可以嘗使用support vector的數量來選擇模型,因此在作cross validation前可以透過檢查support vector的數量,去掉support vector數量較多的組合作模型的安全檢查。

總結這堂課介紹了soft-margin SVM,其核心概念在於不強求把所有的類別都分對,並加上犯錯的程度大小的懲罰項。在推導的部份,Soft-Margin和Hard-Margin結果幾乎一樣,只差在Soft-Margin在αn會存在上限值C。而SVM可以將資料分成三種,分別為non-SV、存在邊界上的free-SV與可能違反邊界的SV。最後在model selection可以使用cross-validation或是參數SV的數量來作選擇。