前陣子在上Coursera的Data Engineering on Google Cloud Platform這個系列課程,其中在Serverless Machine Learning with Tensorflow on Google Cloud Platform這週內有一個Feature Engineering單元,裡面展示了如何透過Feature Engineering來提升模型的表現。上完後覺得裡面提到一些關於Feature Engineering的技巧,決定還是找時間把筆記寫下來。

好的特徵必須要和預測目標值是有相關的,對於特徵和預測值之間,需要有合理的假設,而不是隨意丟任意的資料進來,就希望特徵和預測值間具有關聯性,否則會落入Data Dredge的問題。Data Dredge意指可能會從大量資料中找到另人意外的相關性,這並不是我們想要的結果。(例如荷蘭的研究中指出一個地方送子鳥被看到的數量,和9個月後嬰兒出生的數量相關)
Causality

好的特徵特性是要使用預測當下能夠掌握的資料當作特徵,例如當你要使用每日的銷售資料當作特徵值,但是這些資料可能需要一個月的資料才會產生,而不是及時會被收集到資料倉儲。像這種可能因為資料延遲造成在預測時無法取得完整的資料將可能造成模型失效。所以在訓練模型時,請確保這些特徵在預測時是可以完整取得的,否則不要使用在模型中。
Numeric & Magnitude
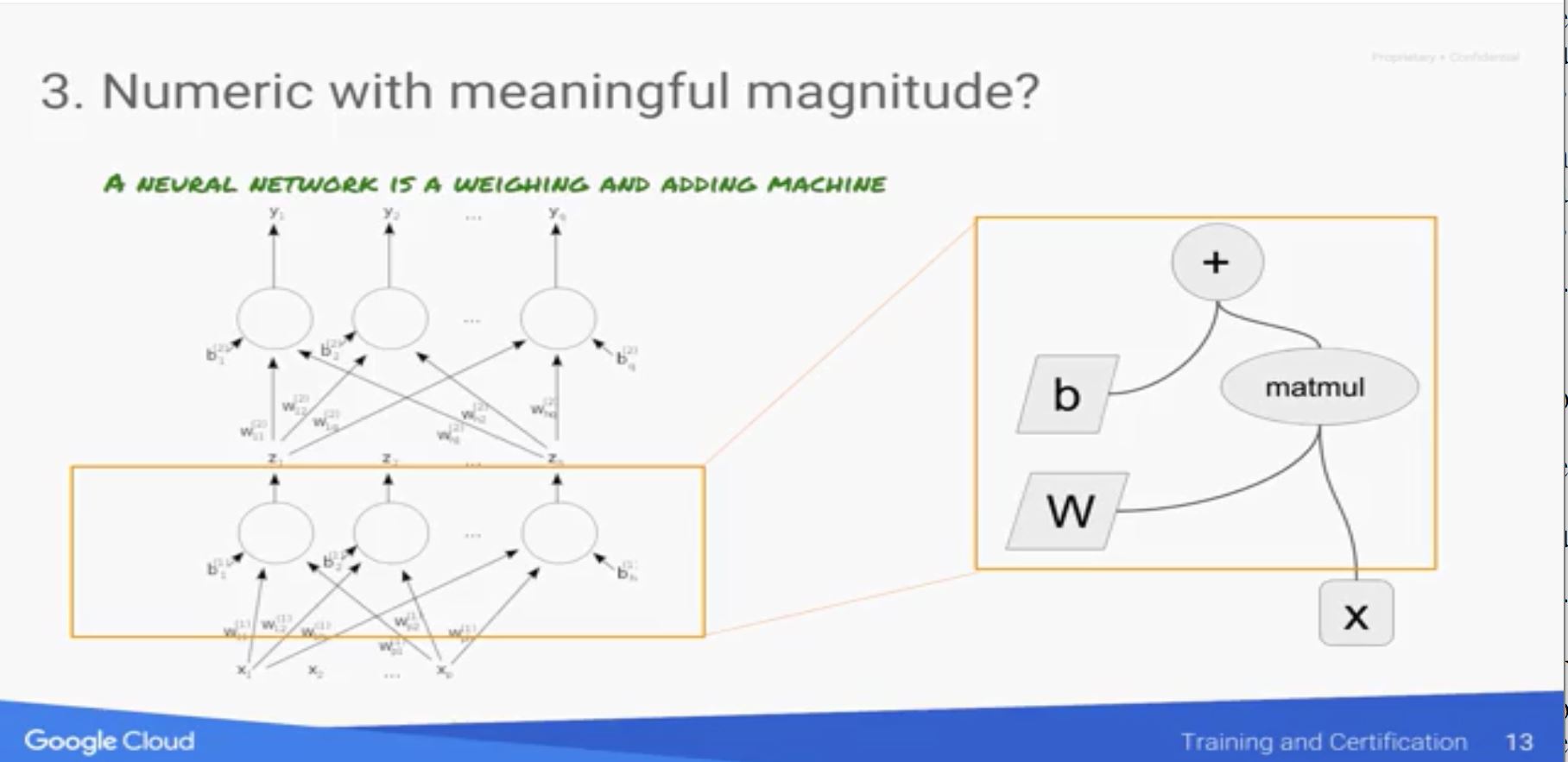
因為在機器學習的過程中,會對輸入的資料作許多的運算,因此使用的特徵必須要為數值形態,且其數值是有大小意義的(例如coupon提供的打折數20%和10%存在折數大小關係)。
Enough examples

好的特徵需要有足夠的資料,以講者的個人經驗來說,如果一個特徵中每個值出現至少5筆,才會將這個特徵用來訓練模型。舉例來說,有一個類別為自動交易,需要有足夠的詐欺/非詐欺資料才有辦法訓練出有效的機器學習模型。如果今天只有3筆自動交易資料,且3筆都是非詐欺,這樣數量的資料可能就無法訓練出可用的機器學習模型。我想這裡的用意是指一個特徵如果相似度太高,可能造成沒有鑑別度;例如在分類問題中,特徵在每個類別的值都一樣或相似,那麼這樣的特徵可能對分類問題沒辦法貢獻太多資訊,使用決策樹來切分也會找不到好的切點。