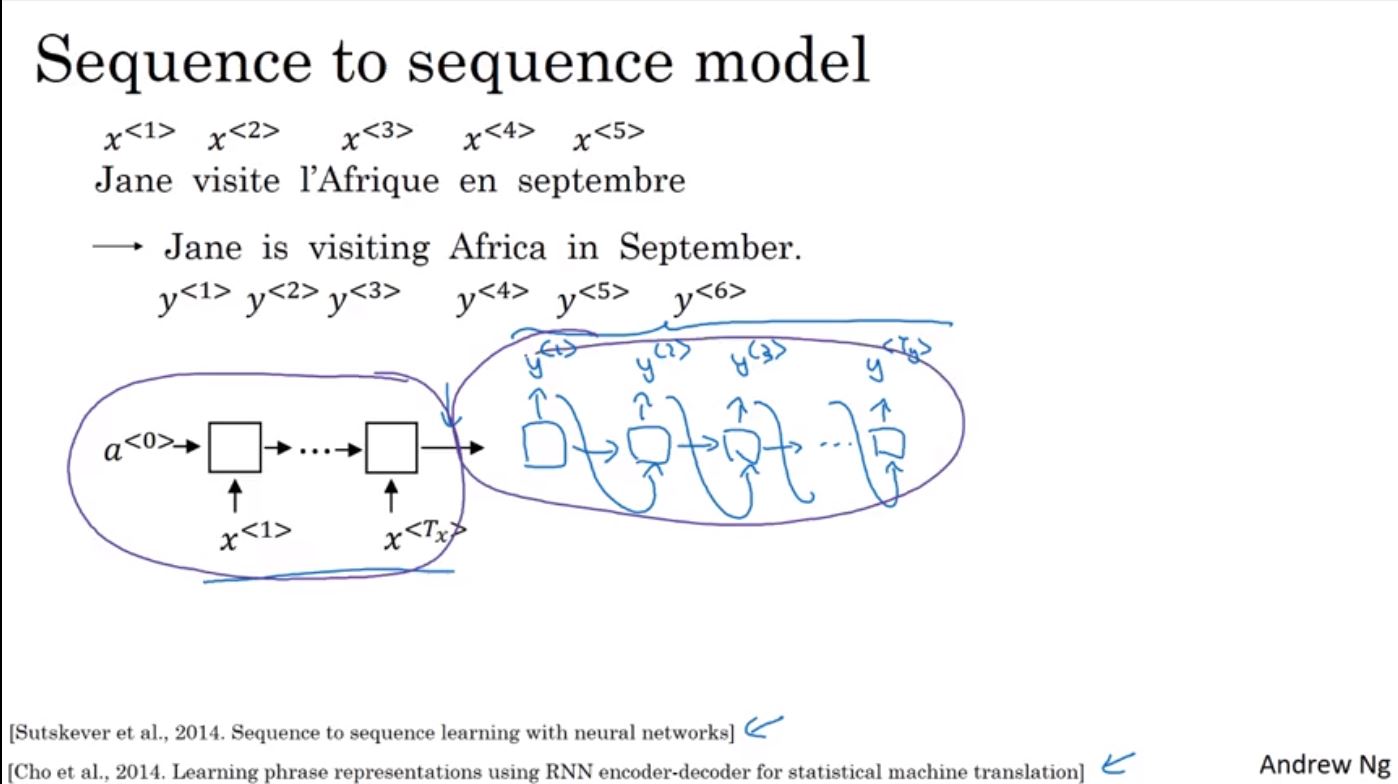
在RNN的應用中,有一種是sequence to sequence模型,像是在語言翻譯問題上,要把長度為5的法文翻譯成長度為6的英文。首先先透過一個encoder將每個法文字詞輸入進RNN模型,再透過decoder逐一輸出英文字詞直到結尾,這樣的模型被證實只要使用足夠大量的法文和英文句子就可以完成。
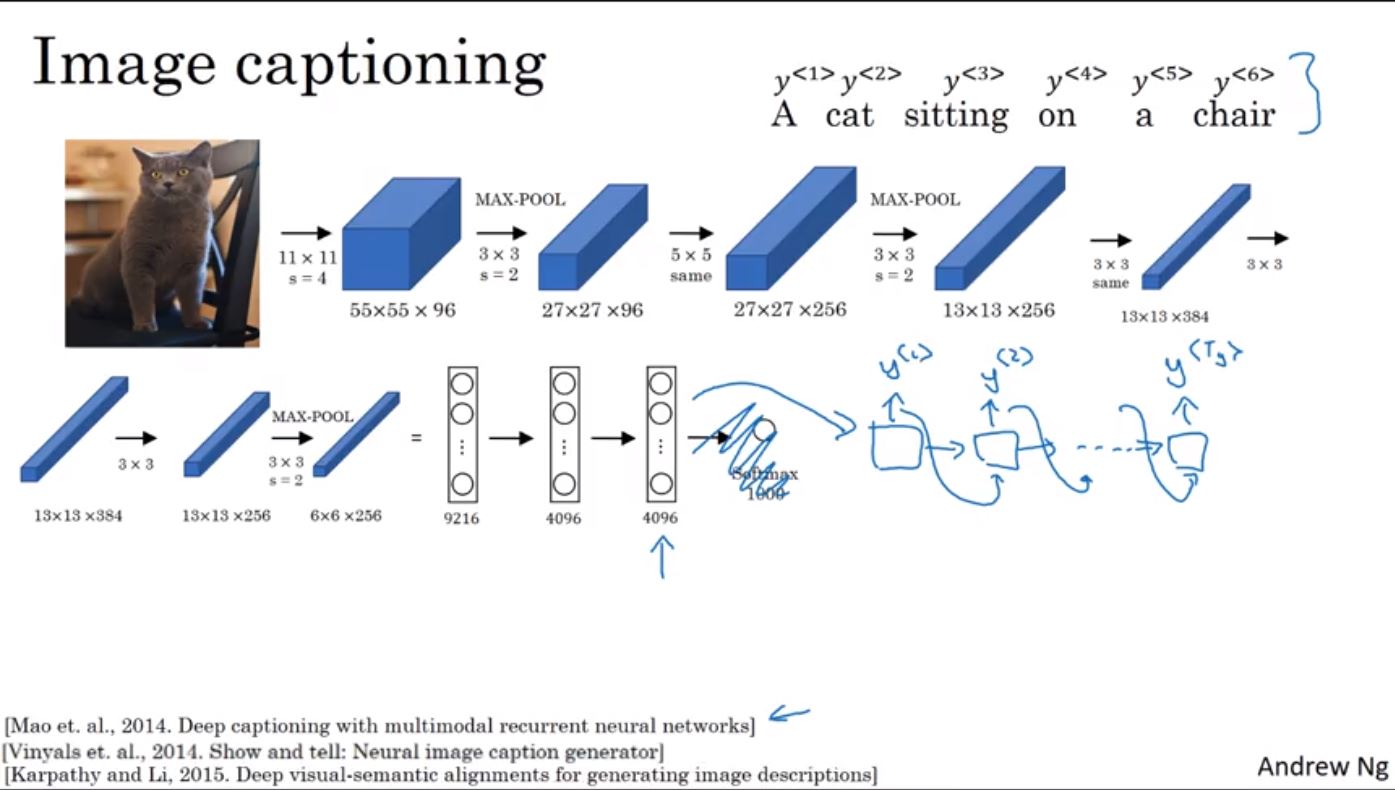
另一個類似的應用是給一張照片,然後自動給予這張照片適當的標題,這時可以透過CNN來建立一個encoder,接著再透過RNN建立一個decoder來產生適當的標題。
第一週有學到language model,會計算產生句子的機率。而在翻譯問題中的encoder部分和language model非常相似,只是在輸入不是向量0,而是一個encoder的網絡。翻譯問題其實很像是一個conditional language model,即給定輸入翻譯前的句子X之下,輸出不同翻譯結果的機率。
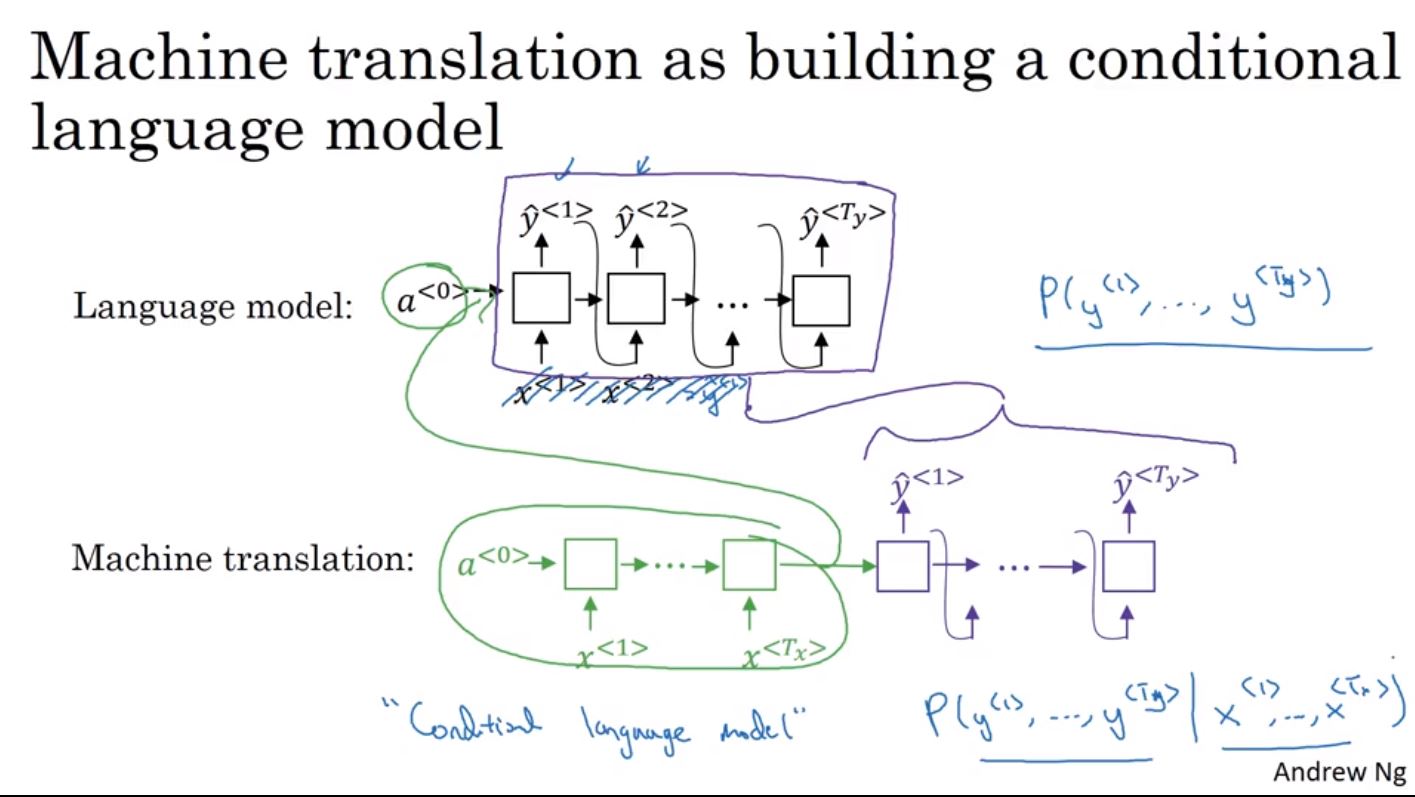
我們並不希望直接對這個分布輸出作隨機的取樣,因為取樣的結果容易很不穩定,有時取到好的翻譯結果,有時取到不好的翻譯結果。所以在使用這個模型的時候,需要使用一個演算法來計算出給定X輸出譯翻結果Y的最大條件機率。
一個方法是使用貪婪搜尋法(Greedy Search),即先根據conditional language model來產生第一個詞,接著在後面的翻譯部份每一次再依據前個詞選取最大機率來產生下個詞。但我們實際上希望的是找到輸出翻譯結果中每個詞Yi最大的聯合機率(Joint Probability),而不是每次都產生一個機率最大的詞,比如說法文翻譯到英文的問題中,如果前兩個字的翻譯結果開頭都是Jane is…,但是going這個字在英文上比起visiting還常見,所以用這個方法會造成第3個詞比較容易接going,但是這並不是一個最佳化的翻譯結果。但在英文可選的詞非常多,所以會使用approximate搜尋法來嘗試找到最大的條件機率。

Beam Search演算法的特性在於不會像之前一樣只找一個最大的機率,而是會存下前B個最大的機率值在記憶體裡面。比如說第1個詞已經找出是in, jane和september,再來會繼續再找出第1個詞是in的情況下,第2個是哪個詞。這時會計算出在給定輸入X且第一個詞是in之下,哪個詞的機率最大,即P(Y2|X,Y1)。再將機率乘上P(Y1|X)就可以得到給定X之下,前兩個詞的機率P(Y1,Y2|X)。然後存下前三個最大的可能性,這時可能會存下in september, jane is和jane visiting,再繼續往下找第3個詞。這時也就代表演算法認為september不會是第一個詞。
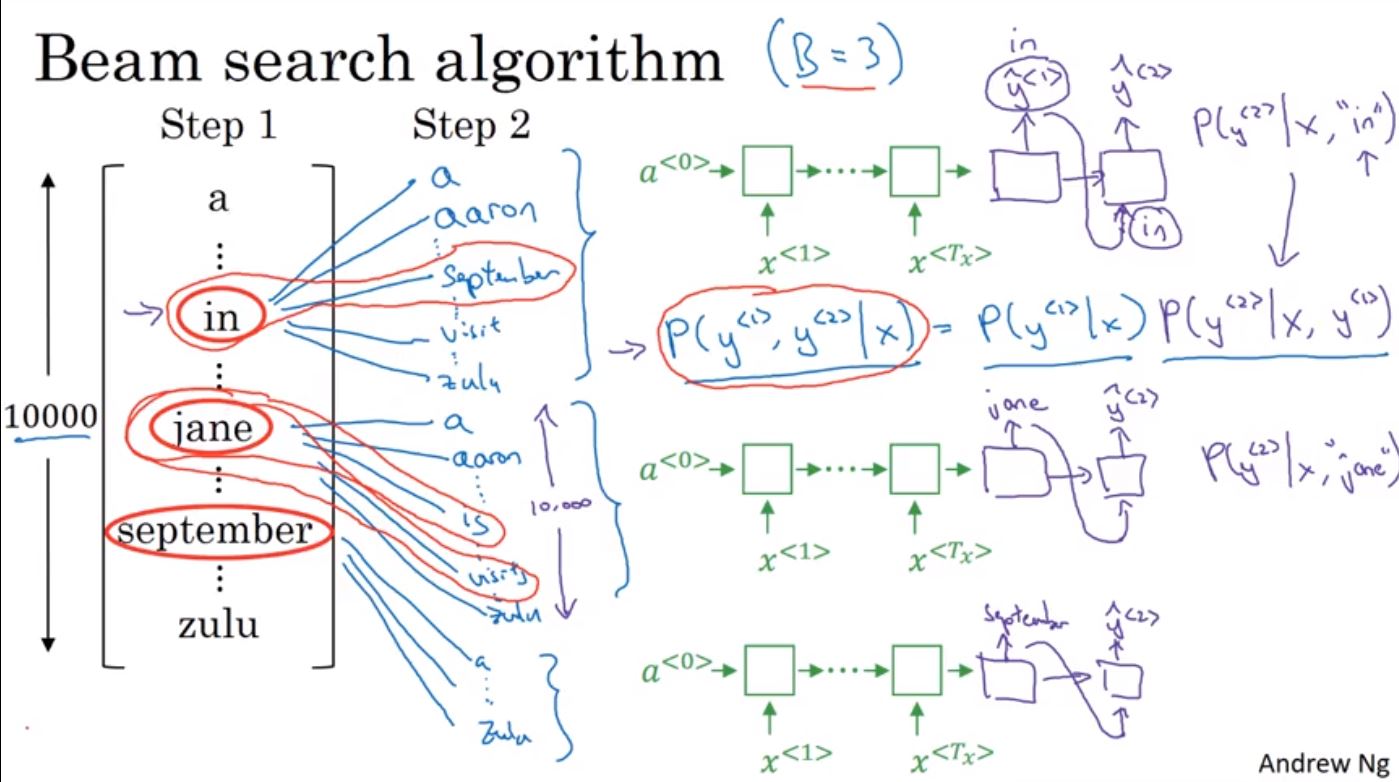
接著beam search再從前兩個詞的三組詞往下展開來,並找出前三個詞最大機率的三組保留,透過這個方法持續到接到結尾EOS並停止。要注意的是如果把B設定成1的話,就等同於前面介紹的Greedy Search。
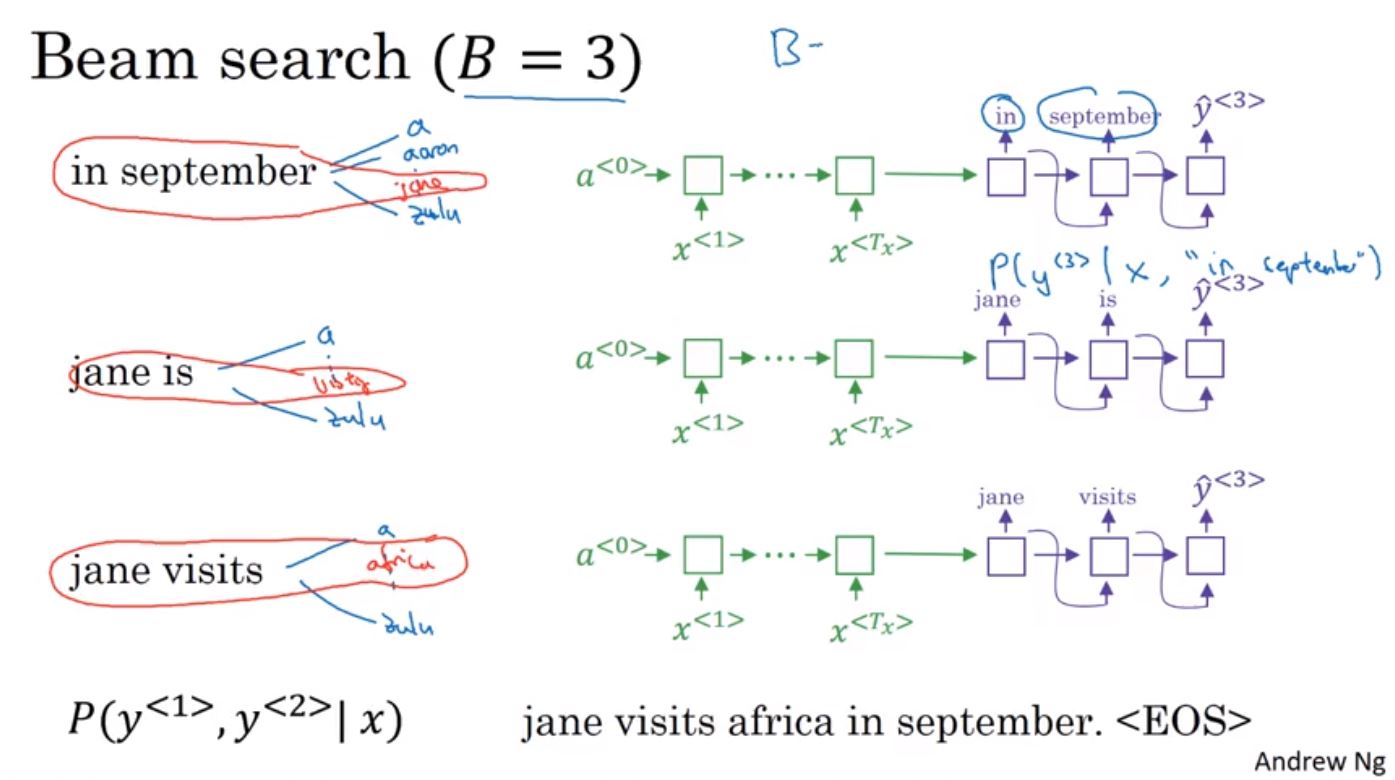
有些不同的方法可以讓beam search可以得到更好的結果,其中一個是length normalization。beam search會持續連乘使得機率值變很小,這可以透過取log相加取代,因為logP(y|x)和P(y|x)兩者取最大值將會有一樣的結果。當句子很長時,可以透過改變目標函式的方法來解決這個問題。因為取log後為<=1,所以當詞越多值也就會越小,一個方法是除上詞的數量來作正規化,這可以大幅的降低因為句子太長所造成的懲罰(Penalty)效果。另外為了要讓這個正規化效果更加的平滑,可以將Ty取α次方,比如說設定成0.7(1為完整的正規化,0為不作正規化)

但B值到底該如何選擇呢?B值越大會可以留下更多的組合來找到更好的結果,但卻訓練的時間會更久,而且也會使用更多的記憶體。Andrew這邊建立在production系統B為10就可以了,但是在研究的系統上,可以取更大的B來計算不同的組合,多次作嘗試。
因為翻譯問題不是像是圖像辨識一樣有正確的答案可以用accuracy來衡量,翻譯結果可能可以有多個一樣好的結果,這個時候可以使用Bleu(Biligual Evaluation Understudy) score來作訓練結果的衡量。
Precision會比對機器翻譯出來的結果和人翻譯的結果,看機器翻譯的每個詞,是否都有出現在不同的答案reference中。比如果機器翻譯出來有7個詞,其中the這個詞都出現在reference中,所以precision為7/7。但這樣的計算顯然不夠精確。Modified Precision則會給予每個詞不同權重,像是the在reference 1出現2次,在reference 2出現1次,因此會給它權重為2,那邊Modified Precision將會修正2/7。
但是衡量並不會只看單一詞的結果,比如說使用兩個詞為一組(Bigram)來作計算的話,會先透過bigram來取出所有組合,並計算每個組合在機器翻譯結果出現次數,再來計算每個組合在所有的reference中有沒有出現(1或0),再來則將reference的數量除上機器翻譯bigram出現次數來計算 bigram的precision。

所以在使用N-gram取組合時,即可以歸納出一個公式,如果機器翻譯出來的結果和其中一組reference相同時,modified precision就會等於1。

把多個n-grams分數綜合起來,可以計算出一個綜合的分數再乘上BP。因為當機器的翻譯結果過短時,會造成大多的字存在reference中,使得modified precision會偏高,此時會引入BP(Brevity Penalty)的概念,當機器翻譯的長度比起reference還長時,BP為1即不給予懲罰分數;反之給予一個懲罰分數。

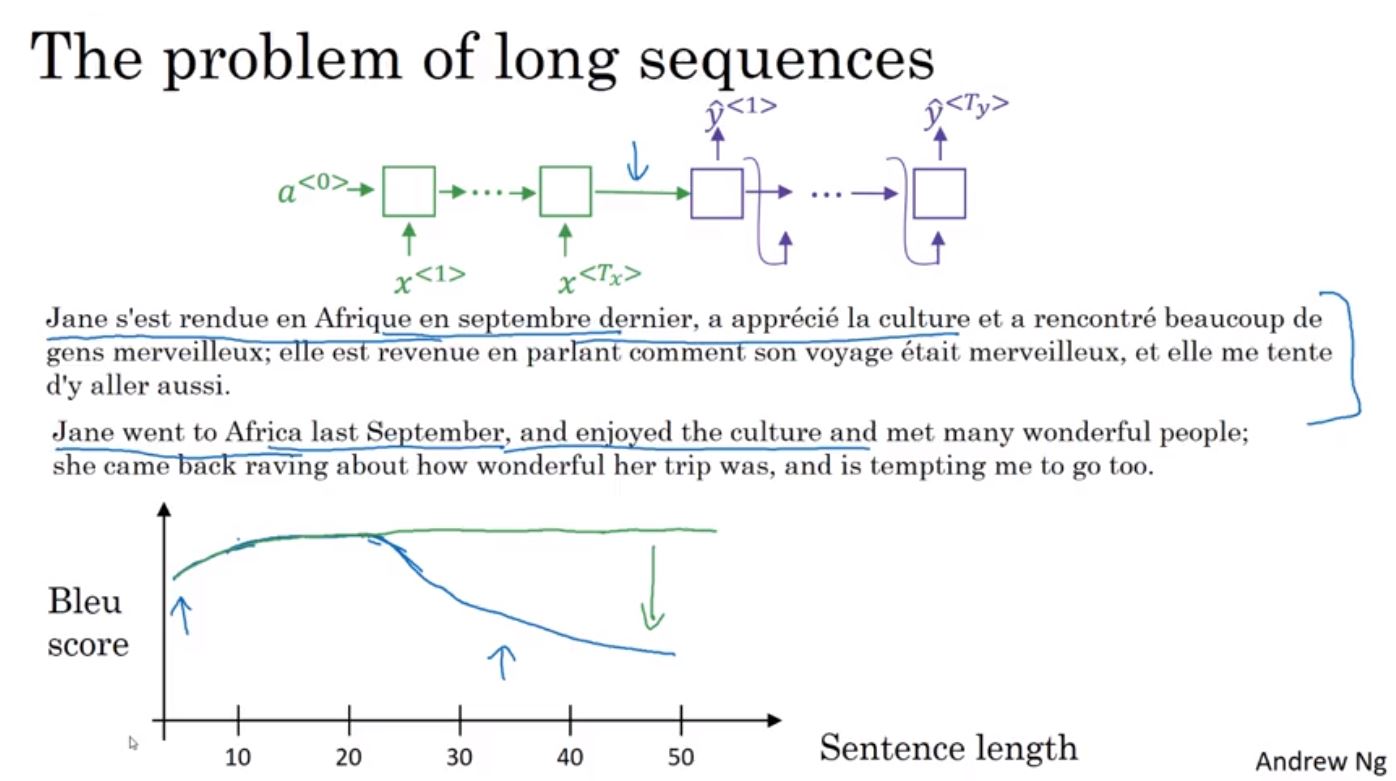
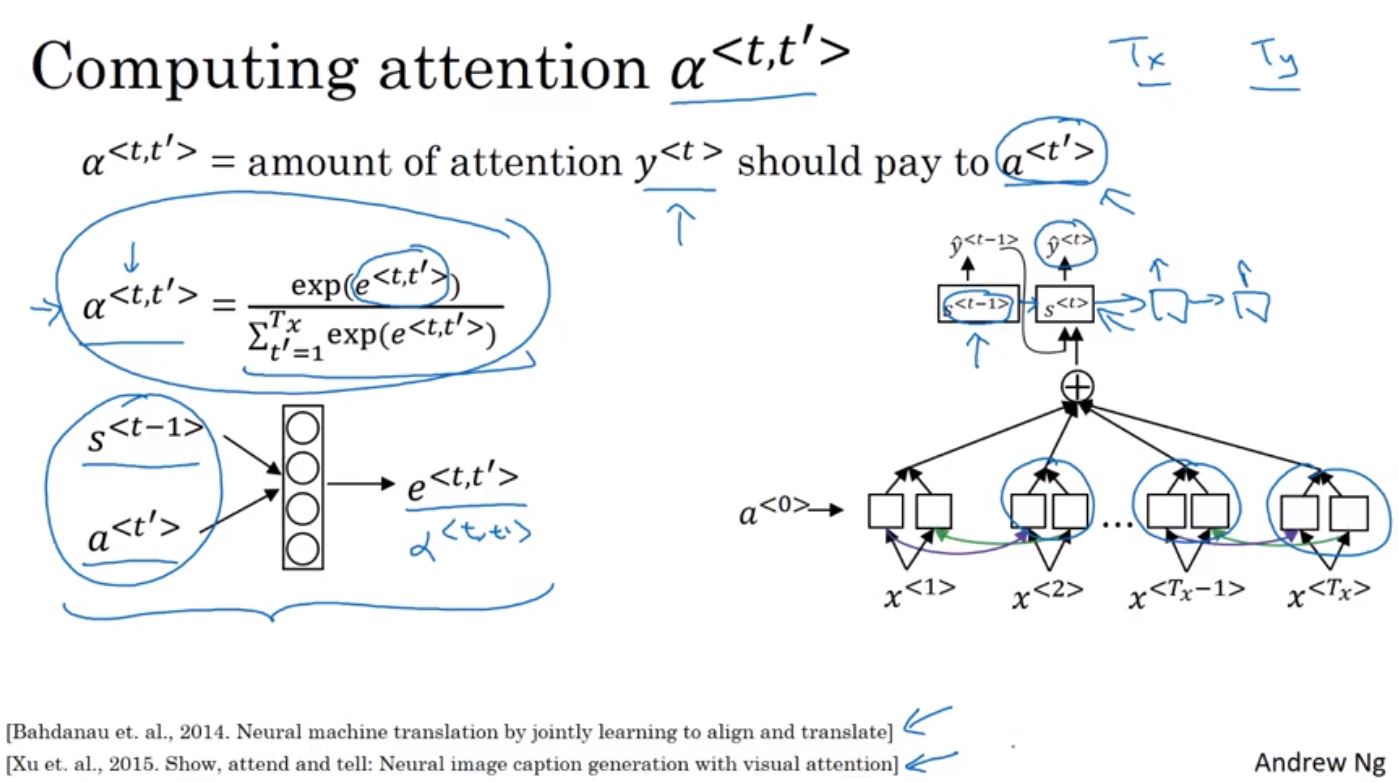
實際上人在進行翻譯時,並不會把整段都看完再翻譯,而是先看一小段翻完再往後看另一小段。而且當句子越長時,Bleu score會逐漸降低,這時如果使用Attention Model來幫助每一小段作翻譯的話,則可以解決這個問題。
雖然attention model是用在比較長的句子,但這邊使用短句來作說明。這裡encoder使用bidirectional RNN,在decoder時透過另一個RNN來完成翻譯。在產生第1個詞時會透過α來表示要產生這個詞應該要注意的資訊量有多少。接著再產生第2個詞時,會產生一組新的attention weight來表示產生第兩個詞時該注意的資訊量,並加上前一個產生的詞。
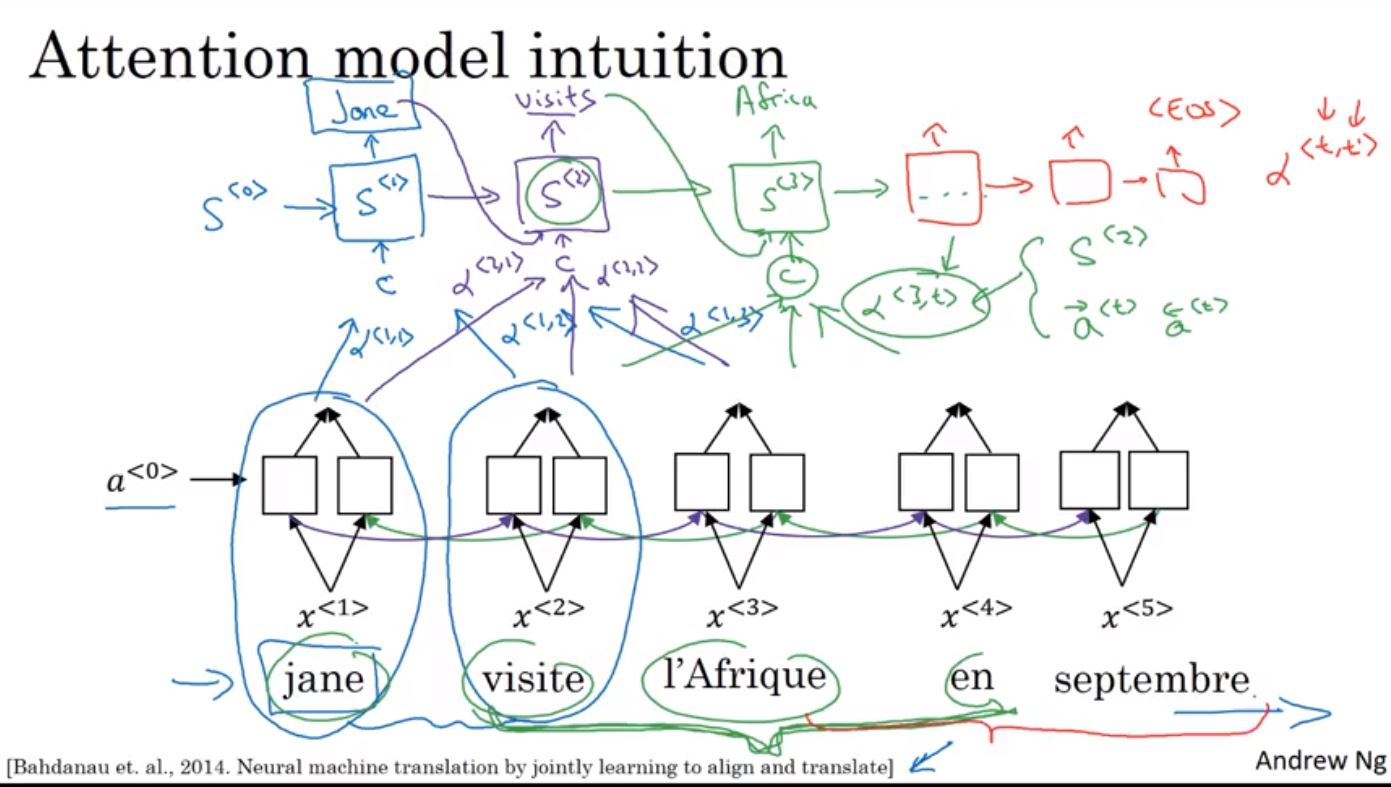
在建立attention model時,encoder使用的bidirectional RNN會貢獻兩個activation值,此值即為α權重。接著在decoder產生每個Y值時會輸入C,這個C即為α值的加總,用來表示要產生的Y值需要注意多少的資料量,而這個α會取softmax確保其加總為1。
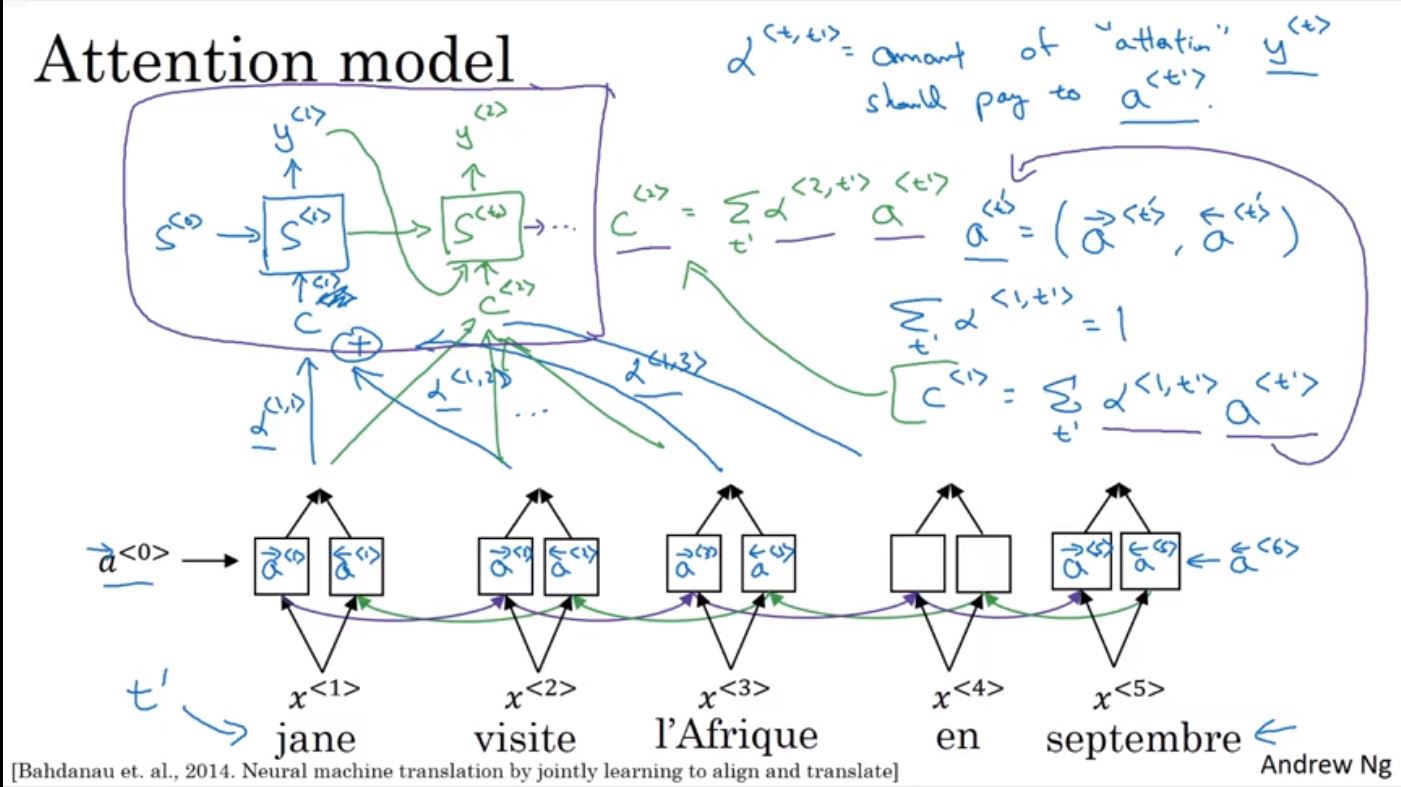
所以在產生Y時主要有兩個輸入,一個是上個hidden狀態S< t-1 >,一個是要注意的資訊量a < t’ >,透過建立這個小的神經網路來使用梯度下降作訓練。但attention model的缺點就是他的計算成本較高,複雜度為Tx * Ty。
seqence to sequence可以被使用在文字的正規化,把不同型態的文字表達轉成一個相同的表示方法。
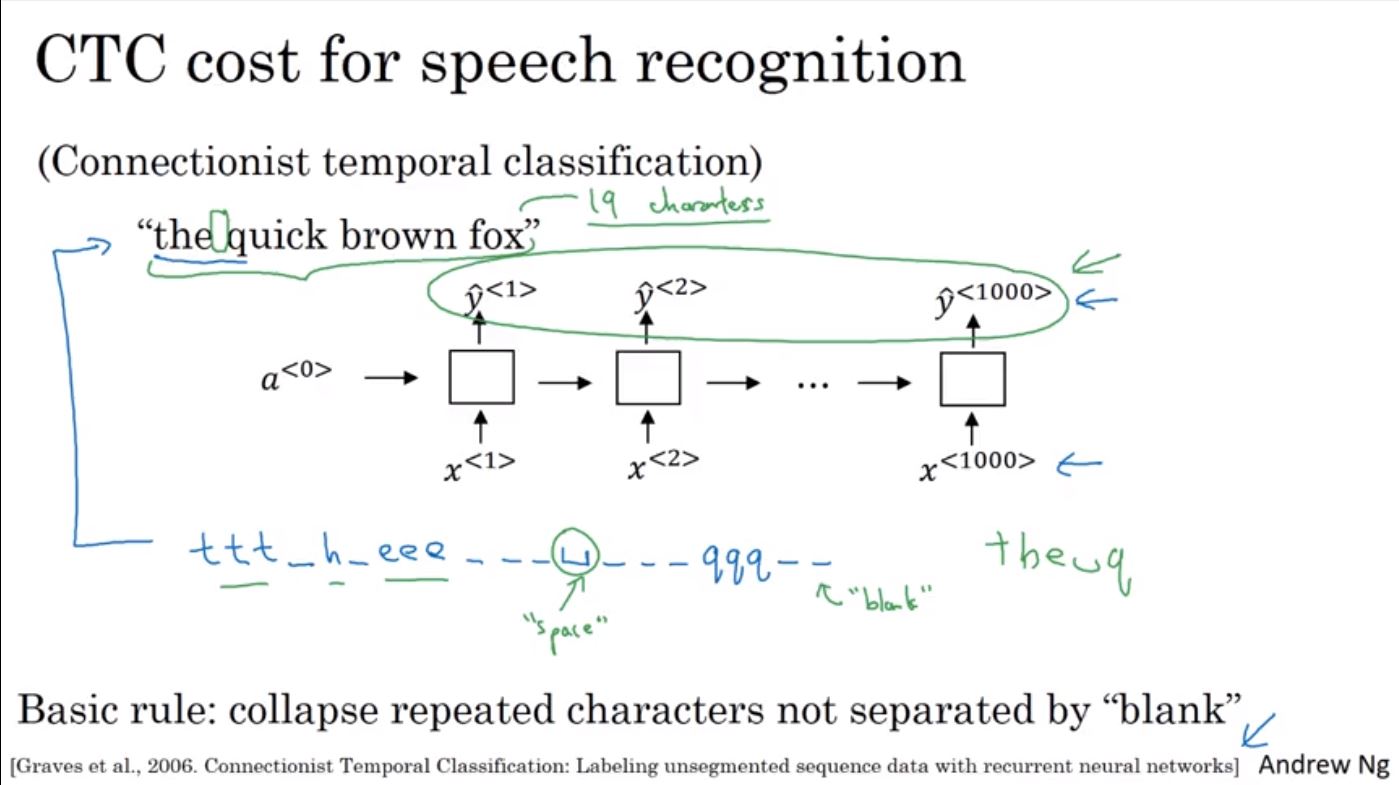
語音辨識(Speech Recognition)也是一種sequence to sequence的問題,輸入一段語音後期望可以輸出一段正確的辨識結果。傳統的語音辨識方法會使用音位(Phoneme)當作基本的單位來表示語音結果,但在end to end的深度學習方法,已經不再需要使用這種方法。
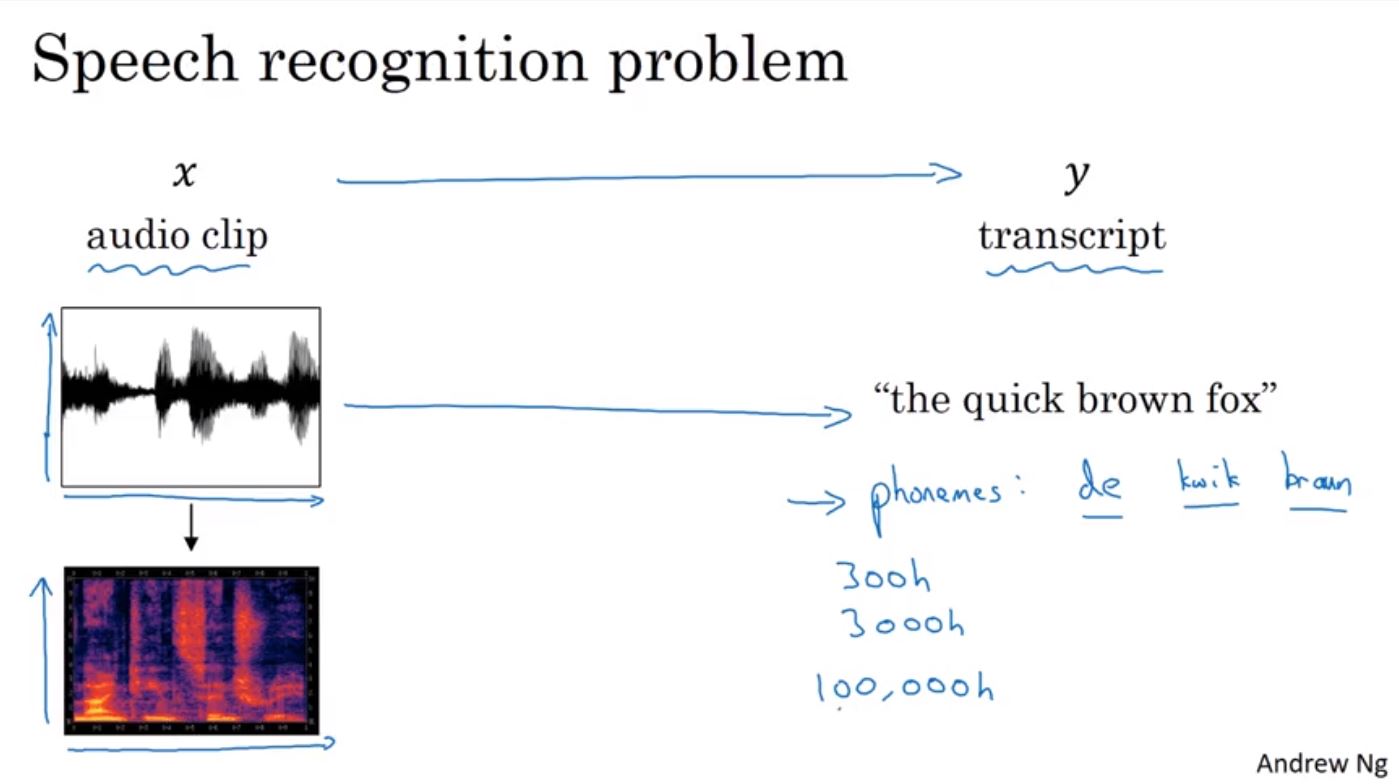
一個有效的方法是使用CTC cost,語音辨識因為每秒可能有多次的取樣,所以輸入的資料會很大,光是10秒的語音就可以變成上1000的輸入,但是輸出的辨識結果並不會有上千的輸出。CTC可以協助幫輸出的結果作適當的collapse,其會對重複的字作collapse像是重複的t, e和q來產生較短的結果。
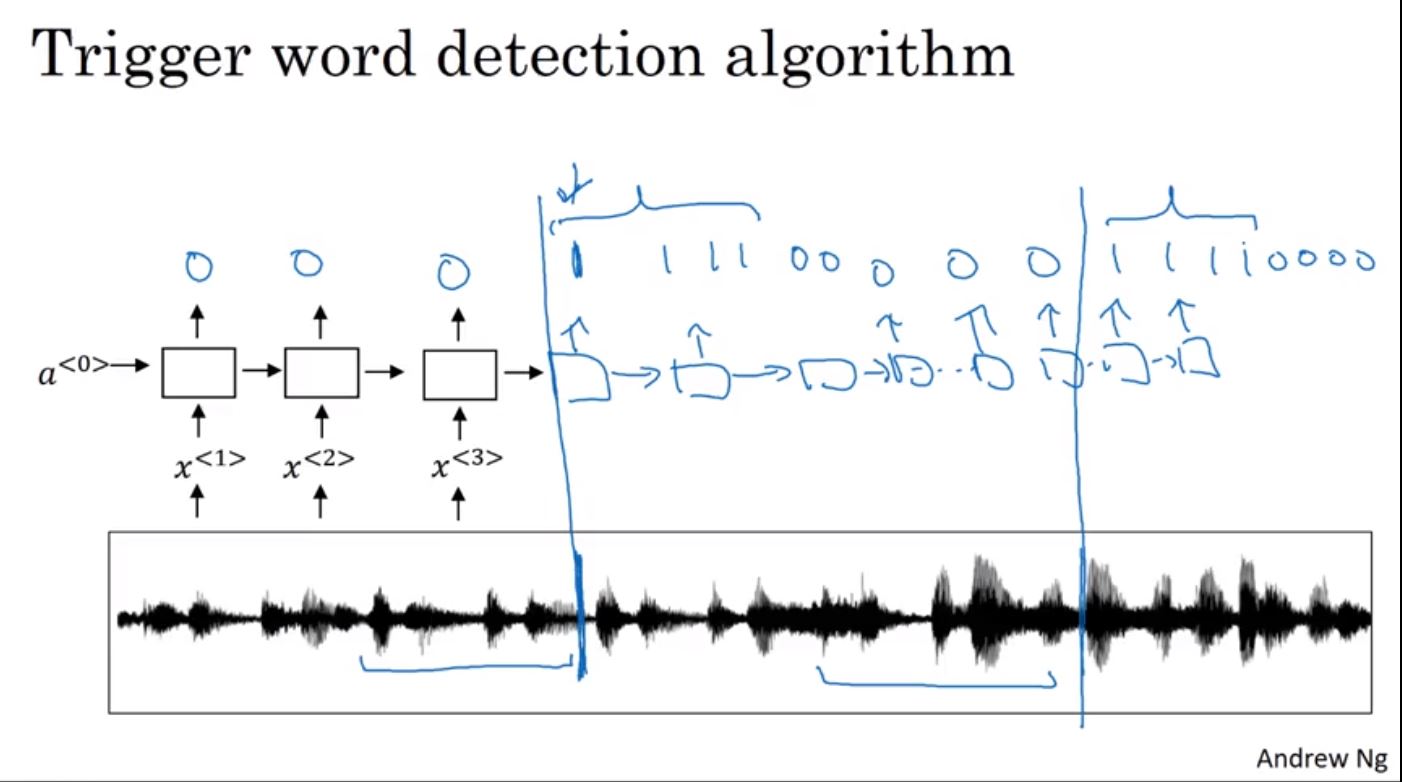
這裡以trigger word偵測系為例來說明語音辨識問題,trigger word常被使用在一些智慧管家的產品當中,像是Google Home或是Amazon Echo。在訓練過程中會輸入語音,並在出現trigger word時的目標label設定為1,其它部份為0。