前面講到M如果會變成無限大,就無法滿足能夠學習的理論,所以我們希望能透過成長函式mH(N)來取代M,這一講主要在推論mH(N)是不是真的成長的比較慢,且能夠夠取代掉M

前面講到M如果會變成無限大,就無法滿足能夠學習的理論,所以我們希望能透過成長函式mH(N)來取代M,這一講主要在推論mH(N)是不是真的成長的比較慢,且能夠夠取代掉M
這一講主要在延續前一講的推導,說明無限多個hypothesis到底發生什麼事情。
前面有是到如果要讓訓練是可行的,則必需要加上一些假設,首先原本訓練的資料和測試hypothesis的資料都是來自於相同的分配(Distribution),那麼當hypothesis集合是有限的,且資料數量N夠大的情況下,不論演算法A挑出哪一個函式g,Ein和Eout都會是接近的。在這個情況下,只要挑出趨近於0的Ein,就可以保證Eout也趨近於0,即代表學習是可能的。

這一講的學習重點主要是在如何討論學習到底是不是可行的,並進一步推導證明機器是真的可以「學習」的。

第三講主要在說明機器學習有哪些種類,以及在訓練過程中會用到哪些不同的特徵(Feature)種類。在針對輸出空間y的不同可以有以下幾種不同的學習種類:

第二講的內容主要在說明如何透過機器學習來回答兩元問題。上一講有提到機器學習會透過一個演算法A,並透過資料D和假說Hyposis H集合,透過選擇一個假說來學習到函式g。以上一講的案例來說,我們會透過函式g來決定要不要發信用卡。

林軒田老師的機器學習基石(Machine Learning Foundation)又開始在Coursera上開課囉!雖然老師已經在youtube上公開所有的課程影片還有課程Slide了,不過在Coursera上面跟著每周的課程,也滿有上課的感覺!剛好也針對上課的內容,希望在有時間之餘,隨手寫下一些其中自己覺得印象深刻的部份來加深對機器學習的瞭解。
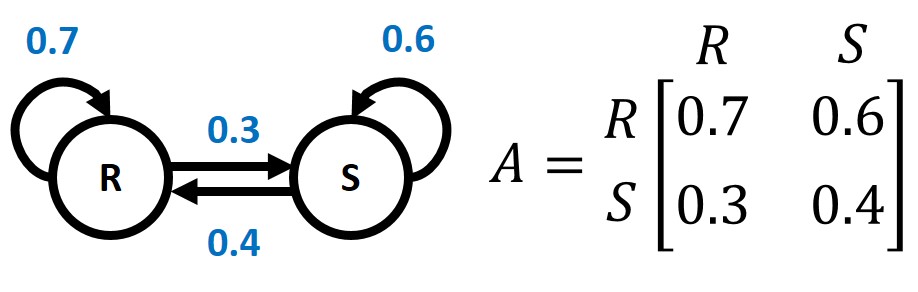
隱馬可夫模型(Hidden Markov Model, HMM)是一種具有隱含未知參數的馬可夫鏈(Markov Chain),隱馬可夫模型常被使用在許多AI與Machine Learning的應用。既然隱馬可夫模型是一種馬可夫鏈,一開始先來簡單介紹一下什麼是馬可夫鏈
馬可夫鏈是指從一個狀態轉移到另一個狀態的隨機過程,且下一個狀態只能由當前狀態決定,根據機率分布從一個狀態轉移到另一個狀態,或是保持目前狀態,不同狀態間改變的機率稱為轉移機率(Transition Probability)。
Python中的decorator是一種對python語法的轉換寫法,使用decorator可以更方便的對函式作修改,也可以提高程式的可讀性。但是decorator只是一種語法糖,使用decorator並不會對語法產生改變,只是讓程式寫法可以更加的簡潔,並且讓開發者可以更方便的使用。
下面開始來說明一下,如何使用decorator來實作在函式的修改:
generator本身也是iterator,和iterator不同的地方在於generator會透過function宣告的方式,但有別於一般的function直接return回傳值,generator的function會在”有需要”的時候,使用yield來回傳值。為什麼稱為”有需要”的時候呢?因為generator在每次呼叫next()回傳值後,會記下所有的資料並保留最後一次執行狀態,直到下一次呼叫next()才會再繼續執行未結束的狀態。我們可以看一下下面這個範例:
1 | def transform(data): |
python中有些資料結構是可以透過for來loop裡面所有的item的,像是list, tuple, dict, str還有file都可以。在使用上其實for迴圈會呼叫物件中的iter(),此函式會回傳一個Iterator(迭代器),Iterator會透過next函式來一次一次的取得下一個item,並在沒有下一個item的時候拋出StopIteration來告訴for迴圈迭代結束。
像這種有按照Iteration Protocol定義iter和next的物件又被稱為Iterable