林軒田老師的機器學習基石(Machine Learning Foundation)又開始在Coursera上開課囉!雖然老師已經在youtube上公開所有的課程影片還有課程Slide了,不過在Coursera上面跟著每周的課程,也滿有上課的感覺!剛好也針對上課的內容,希望在有時間之餘,隨手寫下一些其中自己覺得印象深刻的部份來加深對機器學習的瞭解。
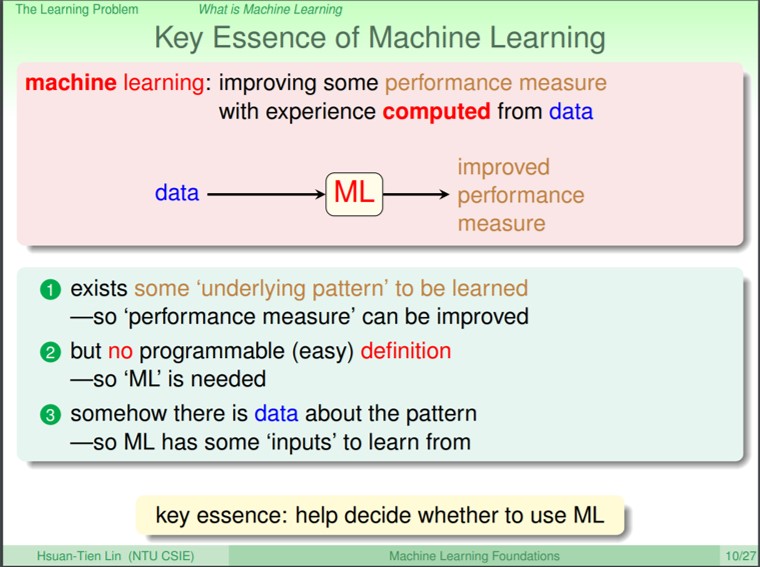
在第一講裡面談到了機器學習的背景,機器學習的過程是從資料出發,經過計算後可以得到某種表現的增進。比如說我們透過股市的資料,經過計算後讓電腦自動投資,來賺到更多的錢。那什麼時候該使用機器學習,其中有提到三個關鍵:
- 資料或問題有潛藏的模式(Pattern)可以學習,並得到某種表現的增進
- 具有存在的規則,但我們無法得知該如何(或是簡單的)定義
- 需要有資料,因為機器學習需要從資料來學習潛在的規則

上面共有四個問題,讓我們思考倒底什麼時候可以使用機器學習(答案是3)。
- 預測小孩下次什麼時候哭,因為是沒有pattern所以無法使用機器學習
- 要判斷一個graph裡面是否有cycle,其實寫程式就可以判斷,而不用使用到機器學習
- 判斷是否要核信用卡,其中包含了pattern,而且不容易被定義,且可以使用歷史資料來學習
- 核能是否會毀滅地球,這個問題太有爭議性而且也沒有足夠的資料來學習

在看機器學習的流程前,機器學習有幾個重要的定義:
x: 機器學習的輸入資料,會透過這些輸入作學習
y: 我們想要機器學習告訴我們的結果
f: 目標函數,也可以說是x和y之間的pattern,他定義了x和y之間實際上的關係,因為f是未知的,所以這也是後們想透過機器學習來學到的
D: 即資料,每一組資料包含了x和他相對應的y。d={(x1, y1)…..}
g: 我們希望透過機器學習學到f,但事實上我們並不一定真的能得學到f。所以我們希望機器學習可以學到一個假說(hypothesis)的函數g,而且和f越接近越好
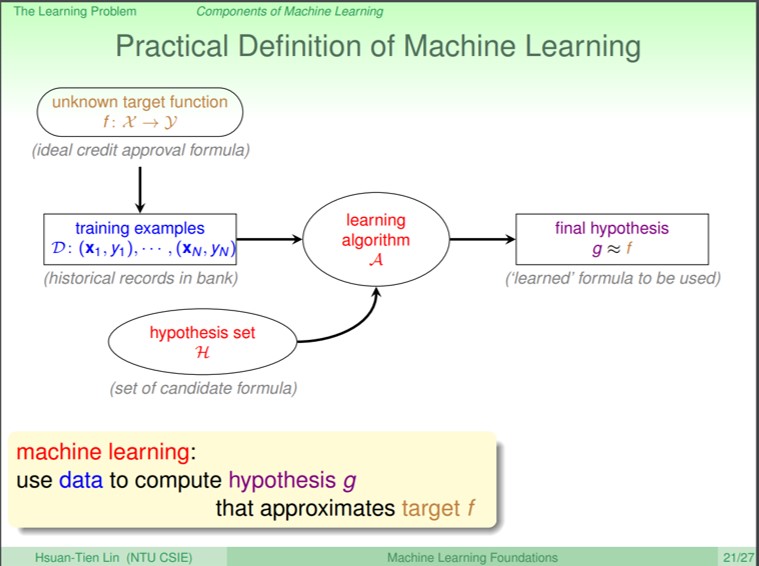
上面可以看到機器學習的流程,透過資料餵給機器學習的演算法來學習到一個函式g,並且可以和f可以很像,這裡的f即是指資料的一種隱藏pattern,而且是未知的,而函式g會從hypothesis的集合內選出一個最符合資料的hypothesis。
機器學習常常被和很多不同領域搞混或是分不出清楚,在課程也有說明機器學習和不同領域的關係
Machine Learning vs Data Mining

資料探勘簡單來說是指,期望從資料庫中大量的資料出發,並從中找到一些有趣的發現來回答問題。以超市來說,會希望透過銷售的資料來找到一個人買了一樣商品後,是否也會買另一樣商品(像是之前的尿布與啤酒都市傳說)。但如果在資料探勘中想要找到有趣的事情,是指要找到一個假說G來作預測的話,那這裡的資料探勘就等同於機器學習。但資料探勘並非都會專注在作預測,有時可能只是想找到一些關聯性。
所以機器學習和資料探勘兩個領或可以說是密不可分的,甚至兩者是可以互補的。比如說可以透過資料探勘找到有趣的性質可以幫助機器學習找到好的假說(可以用在摘取好的特徵值),或是透過機器學習的假說來幫助資料探勘找到有趣的發現。
Machine Learning vs AI
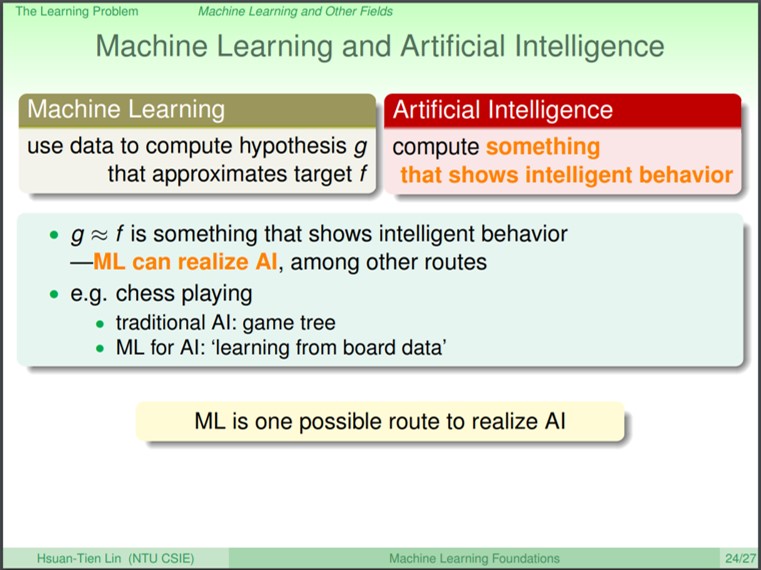
人工智慧: 希望電腦能夠作出智慧的表現,來完成一件事情(開車、下棋、預測)
有很多的方法可以達到不同的人工智慧任務,以下棋來說,傳統的人工智慧作法會設計演算法,透過分析一個game tree(下某一步棋的好處和壞處)來讓電腦自動下棋。如果是使用機器學習方法的話,就是設計演算法來可以告訴機器怎麼下棋會贏怎麼下會輸,然後讓機器分析後自己決定怎麼下(Alpha GO)。所以可以說,機器學習是實現人工智慧的一種方法。
Machine Learning vs Statistics
統計:使用資料來推論原本不知道的事情(ex: 丟銅板的機器)
機器學習中的假說G實際上是一個推論的結果,F則是一個我們不知道的事情,所以統計可以說是實現機器學習的一種方法。我們可以透過很多傳統統計的工具來實現機器學習,將這些工具借過來,使用機器學習的角度來看他。