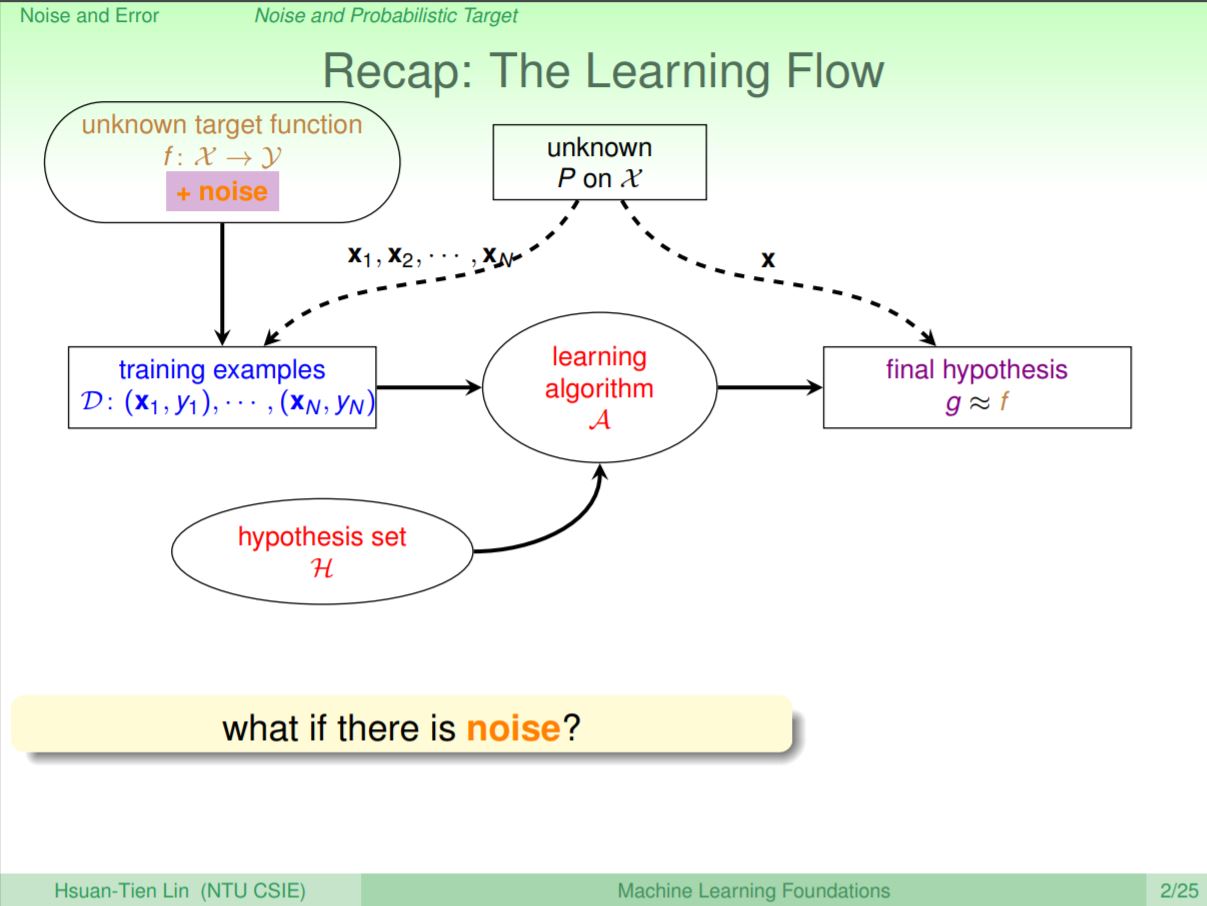
上一堂課講到為了避免overfitting,可以使用regularization的技巧,把一個regularizer加在Ein上面,轉而求Augmented Error反而可以有效的解決模型複雜度太高的問題。這一堂課會講到該如何使用Validation的手法幫助選擇機器學習裡面不同的參數。

上一堂課講到為了避免overfitting,可以使用regularization的技巧,把一個regularizer加在Ein上面,轉而求Augmented Error反而可以有效的解決模型複雜度太高的問題。這一堂課會講到該如何使用Validation的手法幫助選擇機器學習裡面不同的參數。
上一堂課講到overfitting現象,他會在使用過高的模型複雜度、雜訊過多或是資料太少時發生。上次有提到可以使用Data Clean/Purning和Data Hinting從資料面下手解決,這堂課會提到regularized手法來避免overfitting。

上一講提到可以使用非線性轉換的方法,將線性的模型轉換成非線性,雖然可以解決更複雜的問題,但也伴隨著模型複雜度提高的代價。這一講將提到過度適合(Overfitting)現象所造成的泛化能力缺陷。
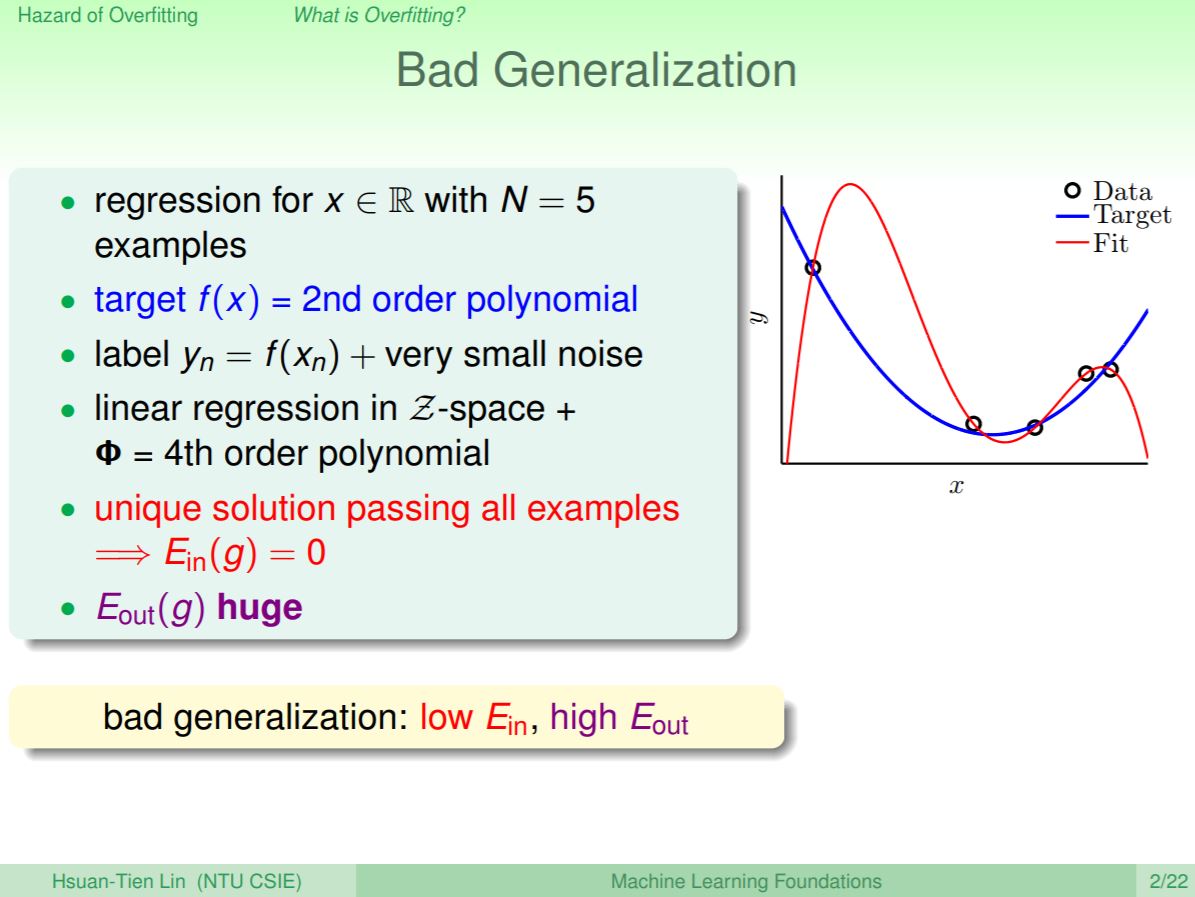
上一堂講到三種不同的線性模型都可以用在二元分類,並且還可以透過二元分類來達成多類別分類,這一堂課會教到該如何將線性模型延伸轉換成非線性模型。

上一講談到logistic regression,這一講會講到到底該如何使用線性的模型來作二元或是多元分類。
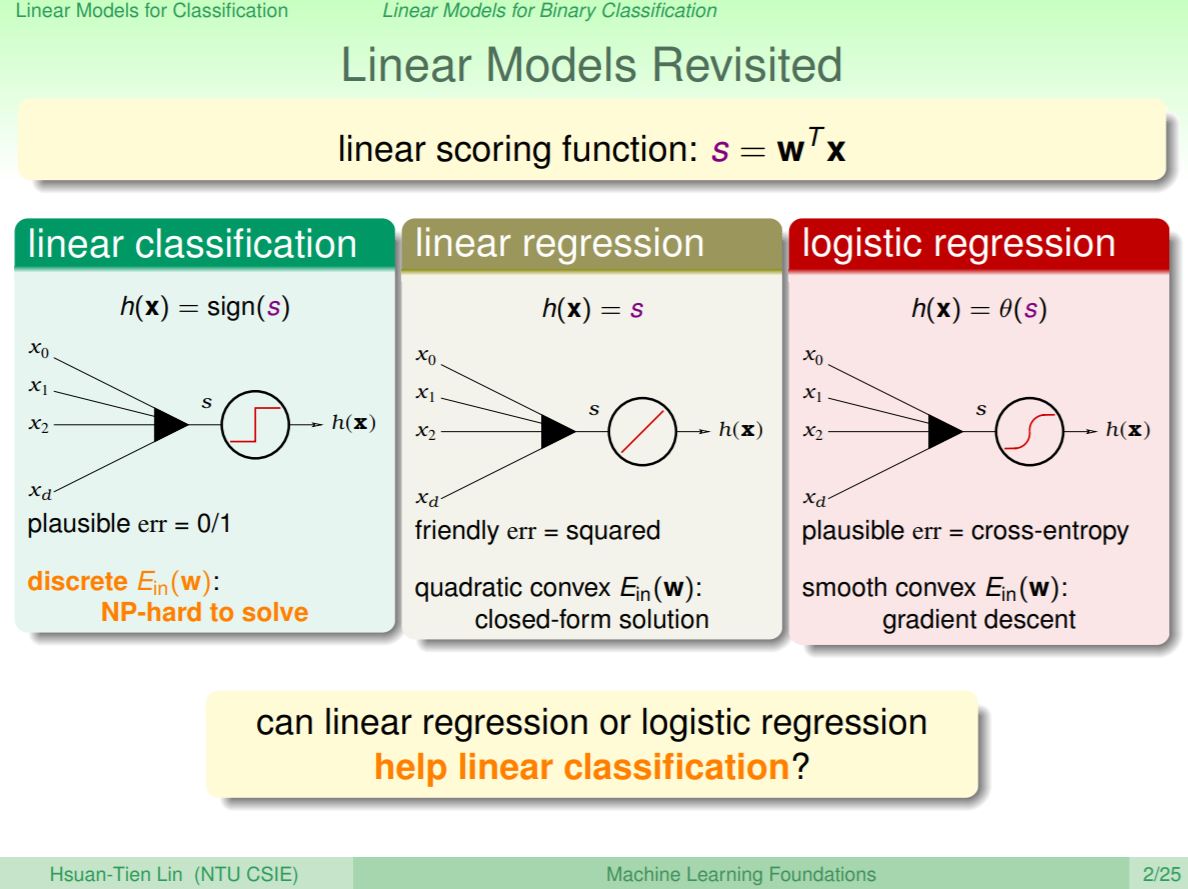
上次介紹了linear regression,這一堂課會說到logistic regression,主要會將linear regression使用sigmoid轉換來算出不同類別的機率。
上堂課講到err的衡量方法有兩種,其中一種squared err就是這這堂課Regression就會用到的err衡量方法。
雖然python已經有很好用的測試框架可以使用,不過對於剛開始想要自己寫測試的人,這些框架該怎麼使用還是需要花點時間學習一番。在真正進入使用測試框架之後,不彷先來作個簡單的測試感覺一下,其實我們可以很簡單的使用python的assert來實作看看。
假設今天要設計提款功能,其中有兩個函式,一個會回傳存款減去提款剩下的金額,一個會檢查提款金額只能以1000為單位。所以這台atm很簡單,就是只讓你提1000為單位的金額,而且不能提超過你餘額的錢。

先來複習一下前面課程,從前面的課程可以得知,在有限的VC維度下,且有大的樣本N並且Ein是夠小的,滿足三個條件我們就可以讓機器可以學習。
在上一講中證明了如果存在break point,而且輸入點N夠大的情況下,Ein和Eout是會接近的。這一講會延續VC bound帶出VC Dimension。
