
上一堂講到在允許違反部份邊界下,引入C當作懲罰值,將Hard-Margin SVM轉成Soft-Margin。而Soft-Margin的對偶問題和Hard-Margin非常相似,只差在對偶問題中的α有上限值C。這堂課會談如果將kernel trick引入logistic regression可以怎麼作。

回顧Soft-Margin SVM,裡面發生的違反邊界會被紀錄在ξn裡面,而ξn會是1-yn(W.Zn+b),因為會紀錄下與1的距離來表式違反的程度和嚴重性;相反的在沒有違反下ξn值為0。再來可以把ξn寫成另一個更簡單的式子,即為轉換成對1-yn(W.Zn+b)和0之間取最大值來算出ξn,並帶入SVM的最佳化式子中,將ξn轉成b和w算出來的結果。

這個轉換後的最佳式其實和之前教過的regularization非常相似,就是在求長度w控制複雜度之下加上regularization項次。所以從這裡可以看到,Soft-Margin SVM其實可以從regularization推導過來,但上一講會選擇從Hard-Margin推導過來的原因是因為這個式子並不是一個QP問題,而且在兩項取最大值時也會有微分求解問題。
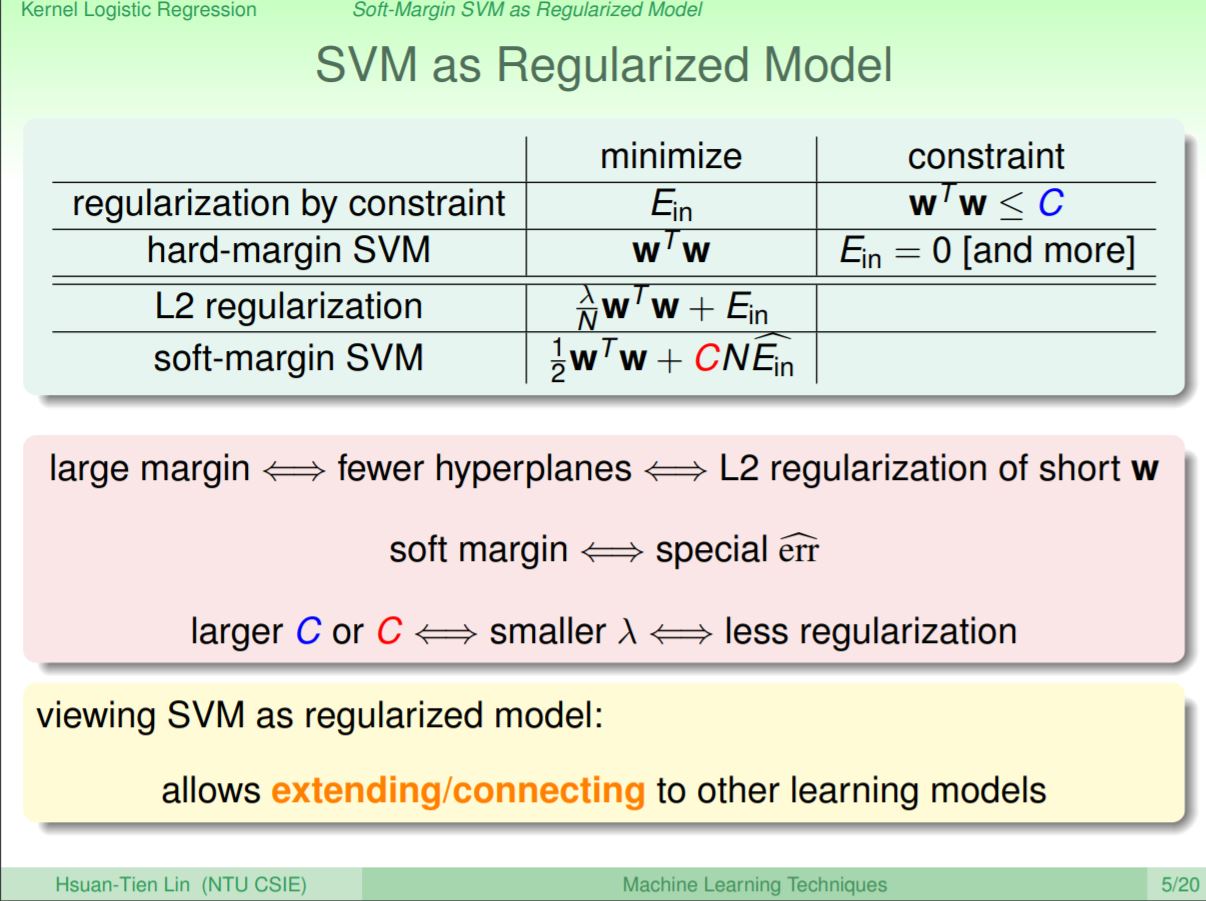
在前面課程推導對偶問題時有提到SVM和regularization的相似地方,而這裡可以看到Soft-Margin SVM其實就和L2 regularization是相似的,所以SVM的large margin就是一個對regularization的實現。但其中細部的差異在於Soft-Margin會使用到特別的error表示,而C的大小即為控制regularization的程度(越大的C代表越小的regularization)。

在計算zero-one error時會是一個像階梯狀的函數,因為ys是正的error為0(猜的方向正確),ys如果是負的error為1(猜的方向錯誤)。而SVM的error會由兩個線段組成,在ys離1越遠error會越大,而ys為正時error為0,SVM的error為zero-one error的上限,所以Soft-Margin也是在間接的把zeor-one error作好。

如果將SVM和logistic regression比較的話,從圖上可以發現logistic regression會和SVM很接近,進一步將ys在正無限大和負無限大比較時,兩者的error也是相近的,所以SVM其實也很像在作L2-regularized,因為在加上error項後,其實error項和logistic regression的error項非常接近。
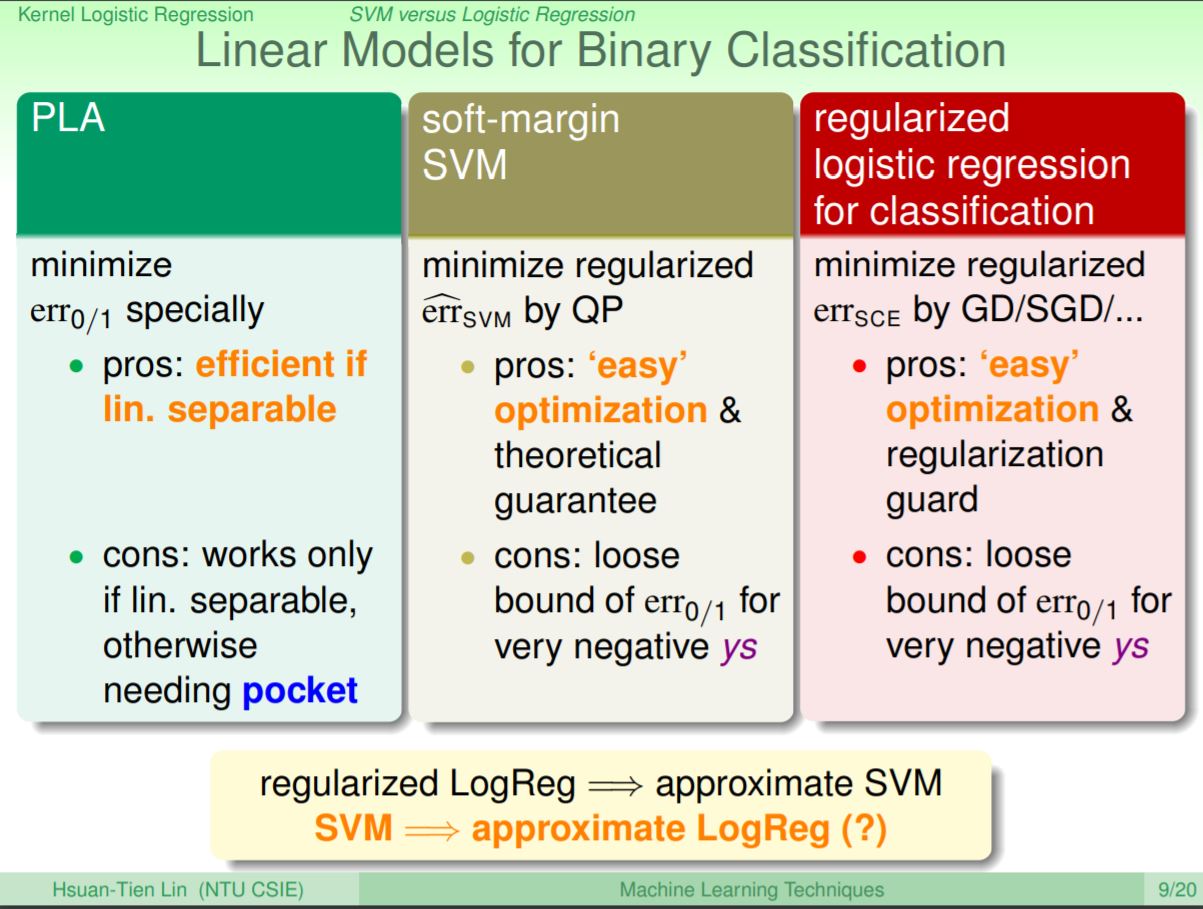
在比較三種兩元分類方法,最一開始教的PLA需要在線性可分的情況下才好作,如果在線性不可分要透過pocket也不好達成;logistic regression的函數有很好的最佳化性質,而且加上L2-regularized後還能對模型的複雜度有一定的保護;Soft-Margin SVM差異在於最佳化使用了QP,並且在有large margin的理論保證,其error的計算方式雖然和logistic regression不同,但確實非常接近,而且兩者都是在作最佳化zero-one error的上限值。因此regularized logistic regression其實就幾乎是在作Soft-Margin SVM。

在二元分類問題中可以有兩種簡易的方法,第一種是透過SVM找到最佳的b和w,再直接丟進logistic reression作出二元分類,但這樣的手法就缺少了點logistic regression像是maximum likelihood的特色;第二種則是將SVM找到的最佳b和w,放進logistic regression當作始初解,之後再作最佳化找到最佳解,但這樣和本來logistic regression用其他初始解再找最佳解的結果相同,而且解變動後也失去了SVM的特性。
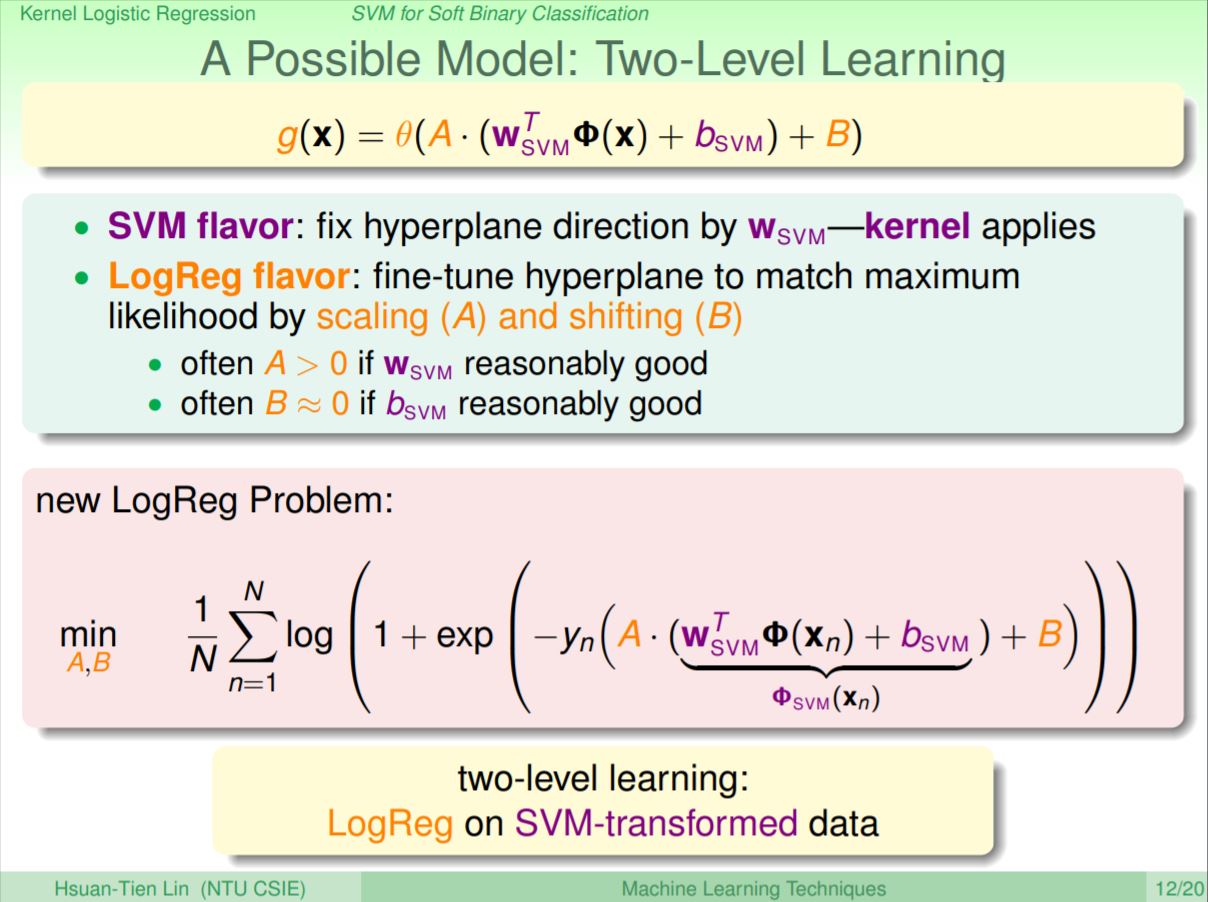
如果要同時有兩種方法的特性,可以先作SVM找到分數,再加上放縮的A與平移的B,最後再放進logistic regression訓練,其意義為先透過SVM找到最佳的超平面,再透過logistic regression作放縮與平移調整到最佳。也就是先透過SVM當作轉換,再丟進logistic regression作兩階段的的學習。

透過這樣的方式就可得到SVM的Soft binary clasifier,因為引入縮放和平移所以會和原本的SVM會不太相同,在求解logistic regression時可以使用Gradient Descent即可。到這裡我們透過kernel SVM去推論logistic regression在z空間的近似解,但這裡不是真的在z空間解出logistic regression,而且透過SVM在z空間找近似解。
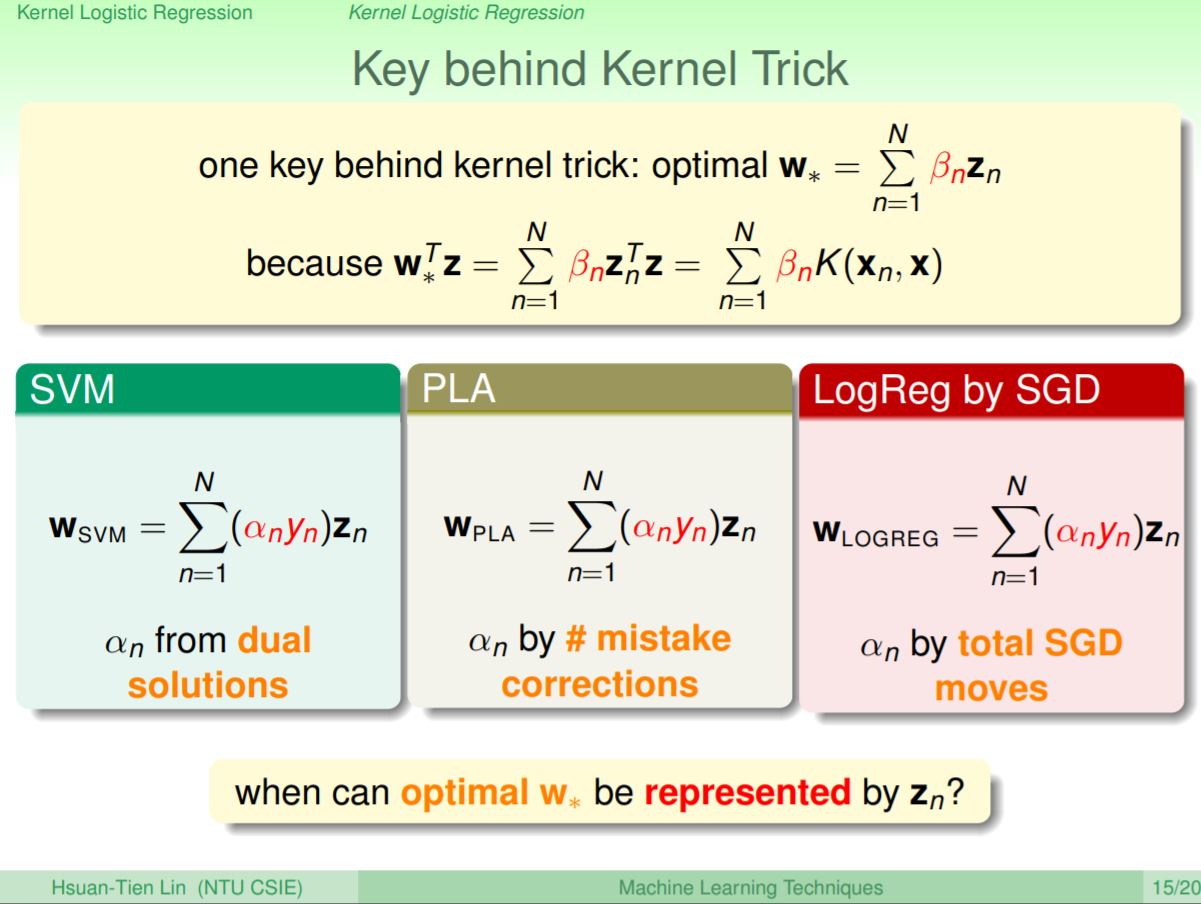
複習一下SVM能使用kernel的關鍵點,是在於將W.Z的內積問題,將W轉換成一堆Z的線性組合,成為求Z.Z內積問題,這時候就能讓kernel上場。在SVM中,W就是Zn的線性組合,組合的系數就是對偶問題的解;PLA的W也是Zn的線性組合,組合的系數取決定每次犯錯的修正,而logistic regression中的W也是Zn的線性組合,這些系數來自梯度下降最終求得的結果。所以這些方法應該都能夠應用kernel trick輕易的在取得z空間的解,最好的W即可透過這些Zn來表達出來。

老師在這裡用例子證明任何的L2-regularized線性模型皆可以應用kernel。

因此,在L2-regularized的logistic regression,就可以將W替換成Zn的線性組合,從求W轉成求所有β系數。在將Zn線數組合代進入取代W後,就能將Z.Z的部份使用kernel,接著就可以透過梯度下降來求最佳解,這就是kernel logistic regression。

如果看這個kernel logistic regreaaion,先從β的角度看起來就像是在求β的線性組合,而且其中還將kernel用來作轉換與正規化;如果是從w角度來看,即為藏有kernel轉換與L2正規化的線性模型。但要注意常常β解出來會有很多0。

總結這堂課從將Soft-Margin SVM解釋成使用hinge error的regularize model,再進一步和L2-regularized logistic regresion比較兩者的相似性,透過結合兩者建立two-level learning應用在Soft Binary Classification,最後真的證明logistic regression也可以應用kernel並求出z空間的解,但會付出解出來很多β會為0的代價。