
上一堂講到kernel logistic regression,並證明L2-regularized linear model都可以kernel化。這堂課會嘗試將kernel放進L2-regularized linear regression作出kernel ridge regression。
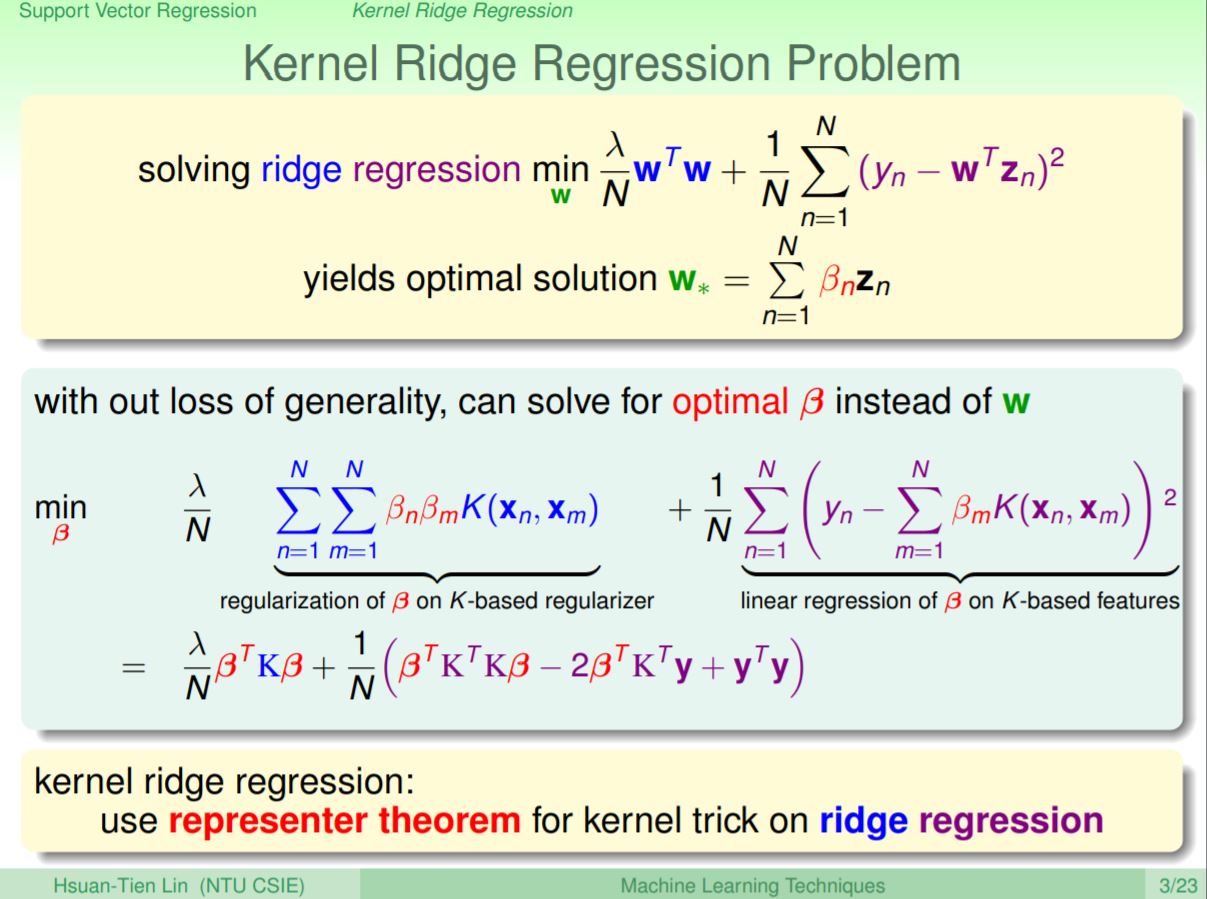
因為已經知道最佳的w會是βZ的線性組合,所以這裡一樣可以將w轉換為z的線性組合,當出現Z與Z乘積時就可以換成kernel,轉成透過kernel trick解β問題。

因為這是一個無條件的最佳化問題,所以可以求梯度為0,即對β微分等於0求出讓梯度為0的β最佳解。因為K一定大於0所以可以求出需要求解的反矩陣來解出最好的β。原本之前說的要作nonlinear的方法是先作transform轉換再作regression,而且現可以另一種方法即使用kernel來達成nonlinear regression。
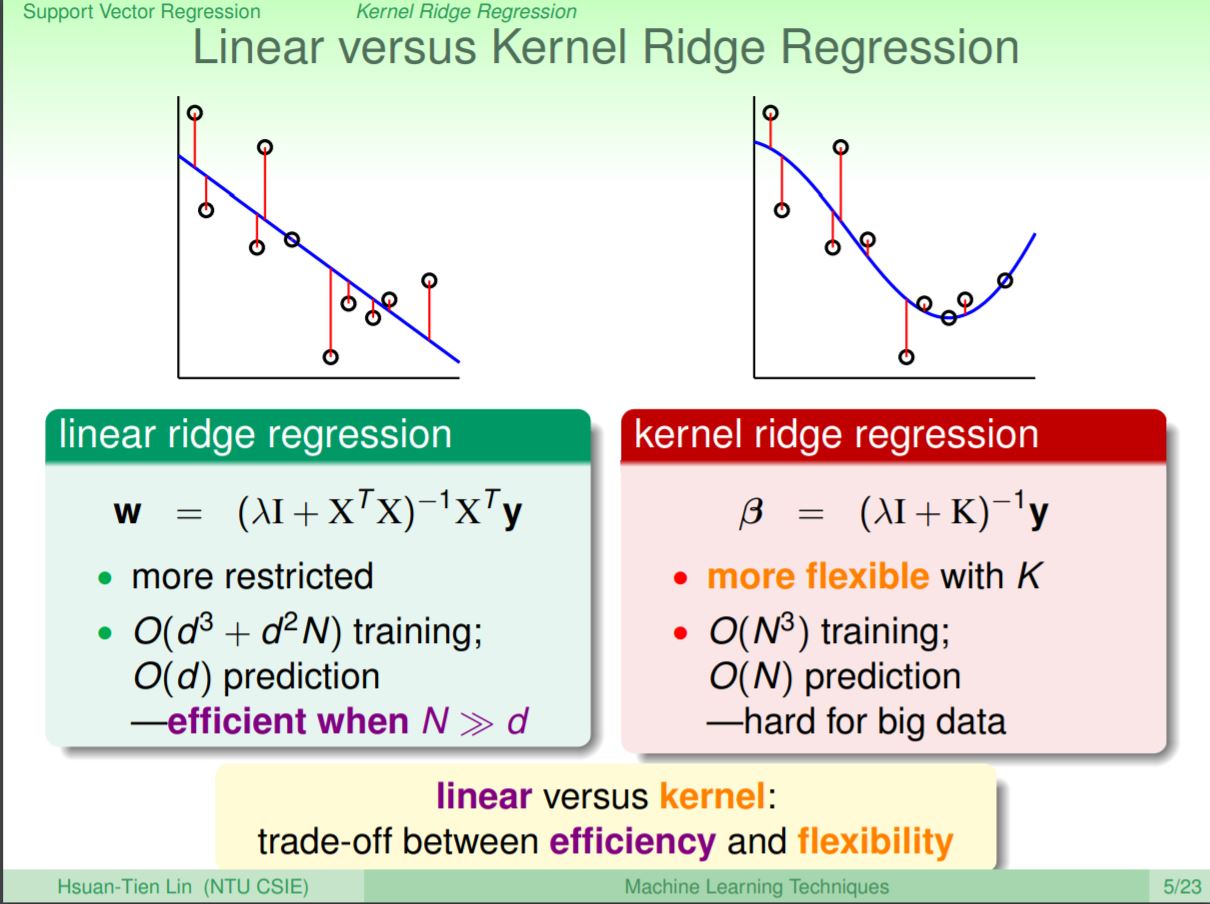
比較linear ridge regression和kernel ridge regression,kernel ridge rgression具有非線性性質所以有更彈性的應用來解決較複雜的問題,但其缺點就是要付出較大的計算時間複雜度。
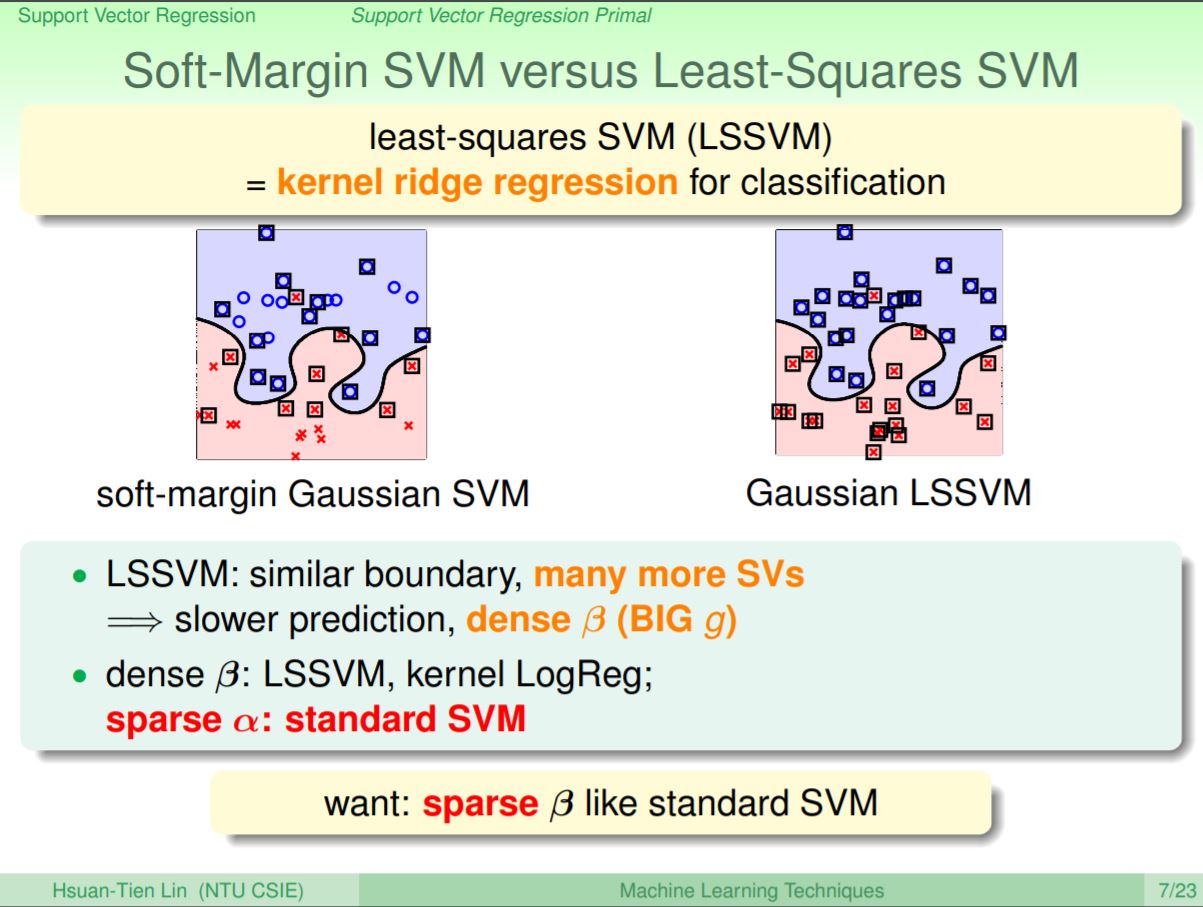
kernel ridge regression當然也可以拿來作classification,這個方法又稱為LSSVM(least-squares SVM)。在比較Soft-Margin SVM和LSSVM,兩者得到的邊界可能會差不多,但比起Soft-Margin裡面求出的α是稀疏的,前面在解kernel ridge時β沒有特別的限制,因此β會求出dense的解,因而得到比Soft-Margin更多的support vector。而support vector較多的情況下,會造成在預測時效率較差。所以再來的重點是如何讓β也可以和標準SVM一樣求出稀疏解。

這裡介紹到Tube Regression,比起原本的regression會計算每一點算與實際值的誤差,tube regression允許在一個範圍內,即落在tube內的點可以不計算error,而落在tube外的點除了計算與實際值的誤差外要再減掉tube的寬度,得到一種新的error計算方法。這種error被稱為ε-insensitive error,下一步會嘗試透過這個新的error來解出稀疏的β值。
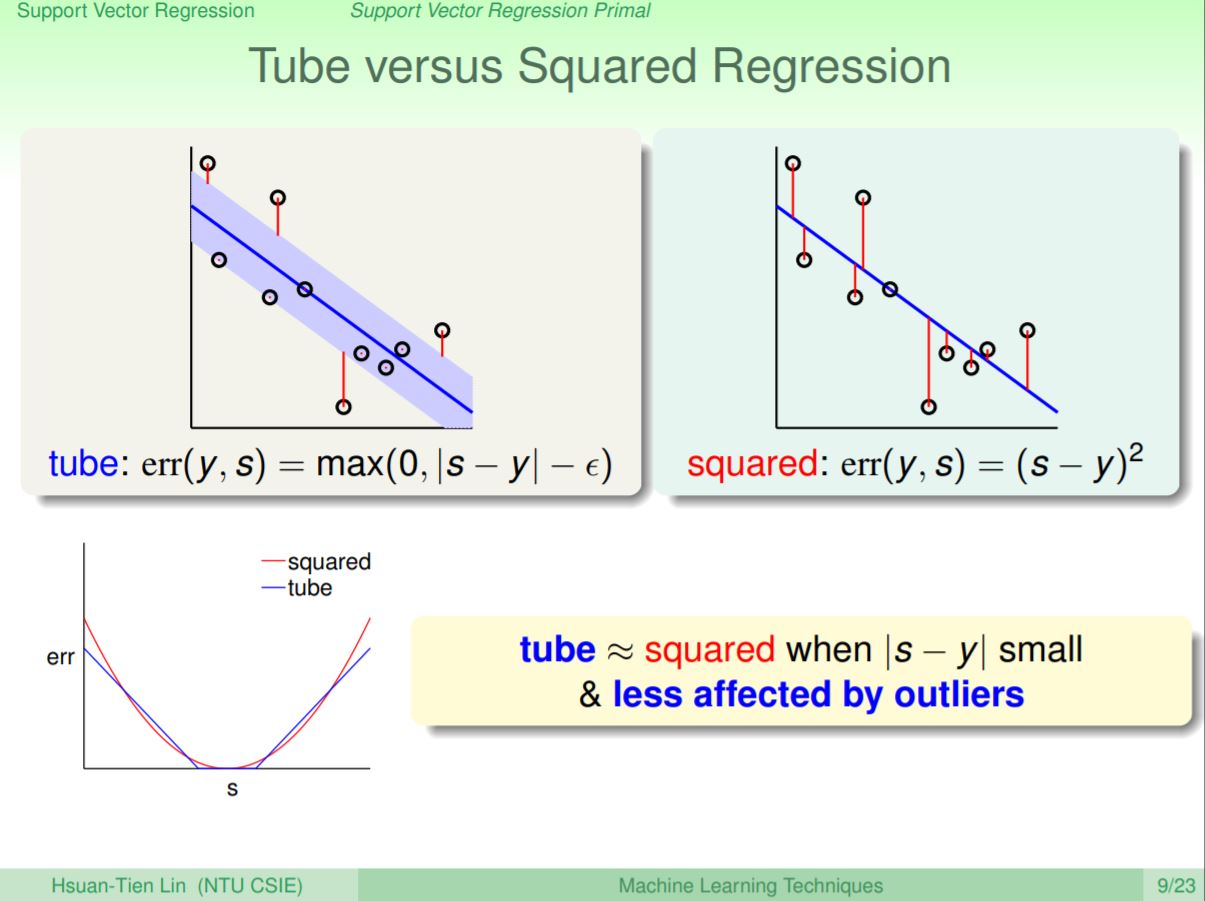
在比較Tube Regression和Squared Regresion會發現,兩者在預測值和實際值接近時,error計算是比較接近的。但是在相差越來越大時,squared regression的error會成長的比較快,因此也比較容易受到雜訊的影響。

L2-Regularized Ture Regression在求解時可以使用任何unconstrain的方式,和之前SVM求hinge error時一樣會遇到max無法微分,雖然也可以使用reprsenter的方式作kernel化,但卻無法保證最後求出的是稀疏解。而標準的SVM一樣無法微分,但是可以被寫成QP問題求解,再透過求對偶問題達成kernel化,而且因為滿足KKT condition可以保證其具有稀疏性。因此這裡可以把L2-Regularized Tube Regression模擬成像原本的SVM再求解(加入C並將w0拆出b值)。

再進一步加入ξn來紀錄犯錯的程度,其中為了將限制式的絕對值拆掉,會得到upper tube violation和lower tube violation兩個ξn。這個式子就是一個Support Vector Regression(SVR)的標準式,而且也會符合QP問題。

這個SVR的標準式會有兩個參數,一個是C和之前的SVM一樣用來控制regularization和violation之間的trade-off。第二個是ε用來紀錄tube的寬度決定允許的犯錯範圍。

有了SVR的primal後,就可以引入Langrange multiplier來轉成對偶問題,所以這裡會引入兩個α來對應兩個ξn,再來就是重複之前課程的推導。

因為SVM和SVR的問題相似,所以可以發現兩者的對偶很相近,而且可以透過QP來解。

回到原本的問題,我們希望β可以是稀疏的,也就是β系數在某些情況要是0。可以發現如果資料是在tube內部ξ會為0,而ξ為0的情況下complementary slackness括號內部的值就不等於0,又因為α和括號內部其中要有一邊要為0,所以α必定要為0,也就是β會等於0。所以位在tube內部的β會為0,而tube外面或是邊界就是對w有貢獻的support vector,這就可以得到β要稀疏解。
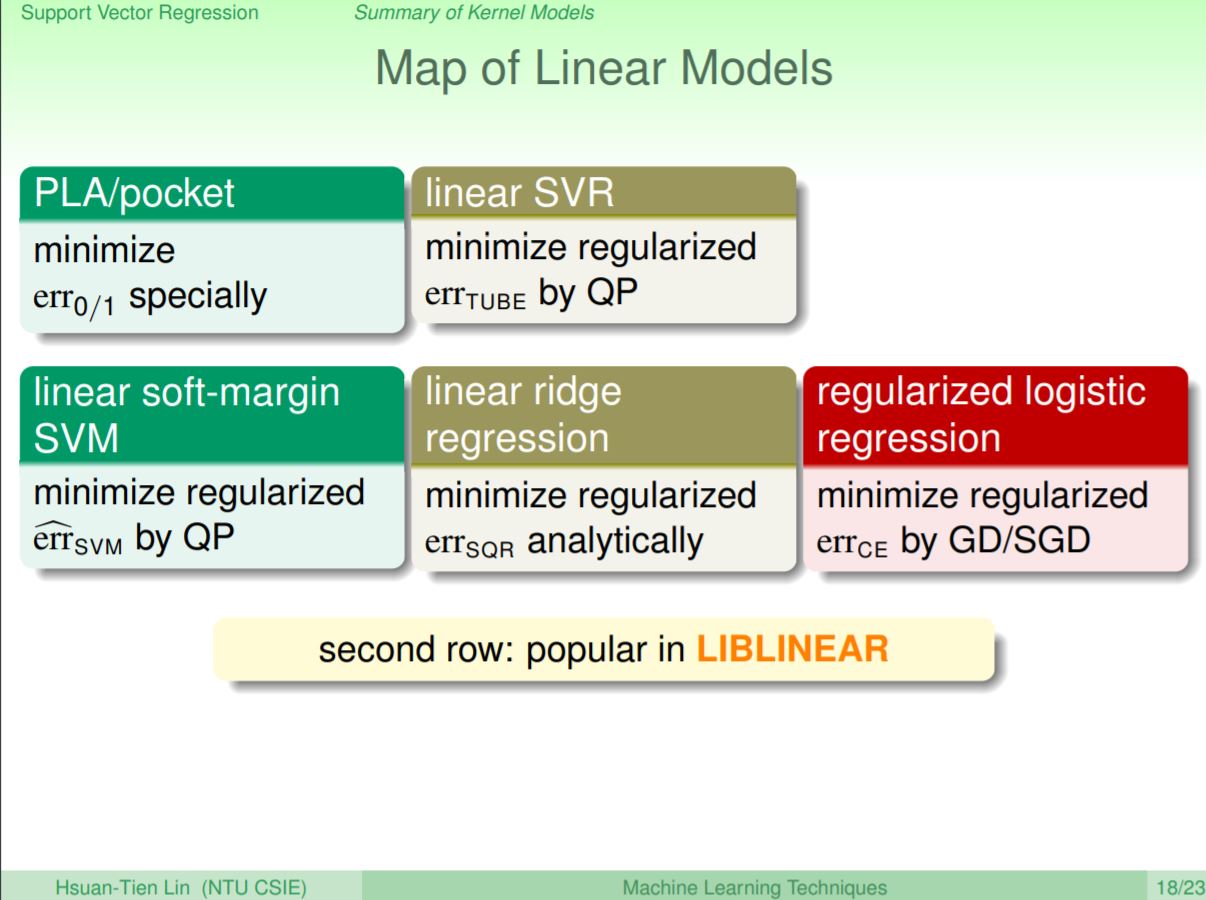
到目前為止教過的linear model總共有5種,在分類問題上,除了最早教到的PLA/pocket方法,這幾講教的linear soft-margin SVM是透過找到具有soft-margin性質的超平面來解分類問題;在regression問題中除了前面講到的linear ridge regression,還引申出透過Tube與SVM概念所延伸出來的linear SVR。另外還有regularized logistic regression結合regularization作模型複雜度修正與maximum likelihood概念來處理分類問題。
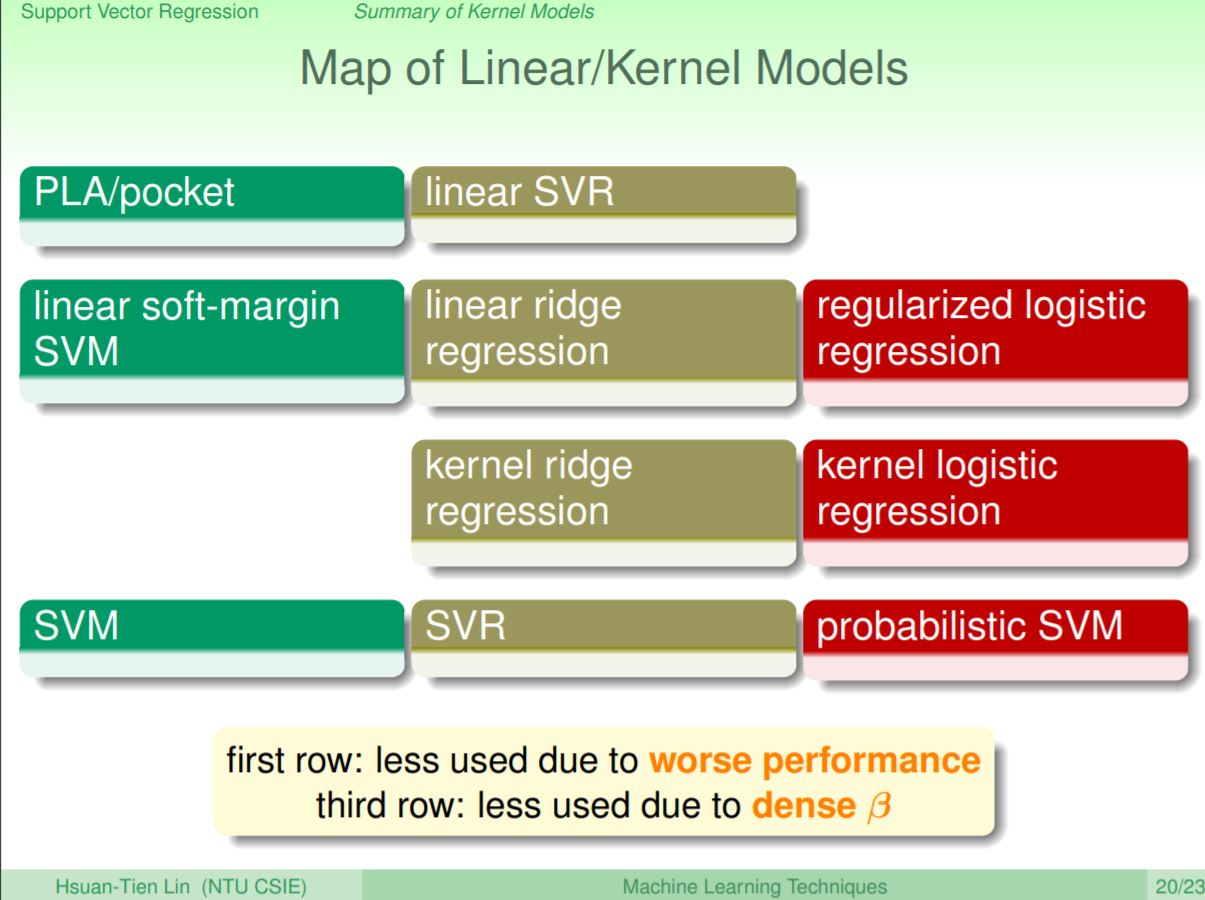
當linear model具有regularized性質時都可以引入kernel的概念,而這6講的內容分別教了如何將SVM、ridge regression、SVR和logistic regression帶入kernel trick。其中第一排的PLA/pocket和linear SVR,因為其表現都沒有第二排linear soft-margin SVM和linear ridge regression來的好,所以實務上比較少用。第三排的kernel ridge regression和kernel logistic regression因為β解出來是不是稀疏解,所以實務上傾向使用第四排的SVR。
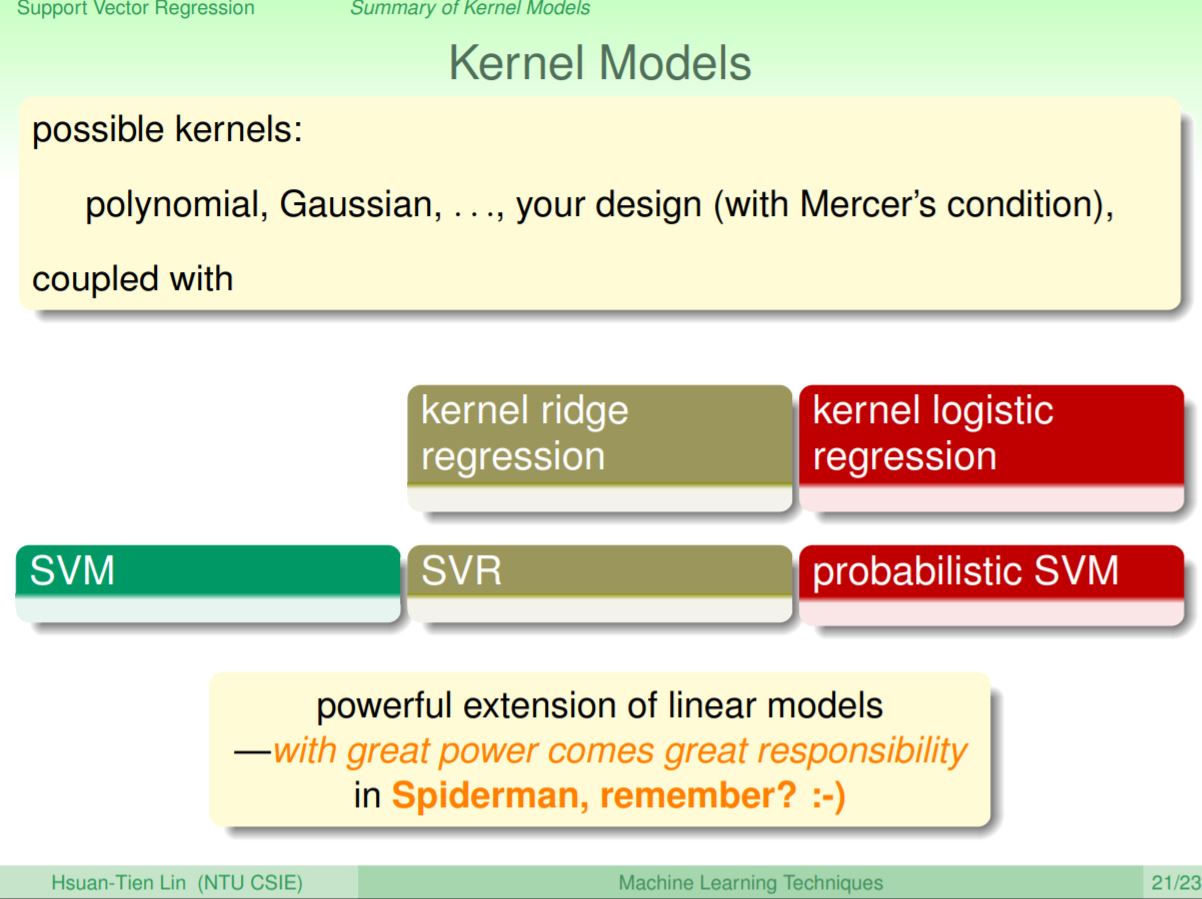
kernel是一個power的方法強化linear model來解更複雜的問題,但要注意的是要小心處理參數的選擇以避免發生overfit。

總結這一講的內容,教到將representer theorem應用在ridge regression上,並結合tube regression引申出SVR的primal形式,再透過求解對偶得到β的稀疏解。最後則比較到目前為止教到的線性模型,並且有嘗試使用kernel來解更複雜的問題時要小心使用,避免overfit。