上一篇說明Langchain的SQL Agent範例如何透過ReAct Prompting實作,而目前LLM其實都已經具有Function Calling的能力,比起要解析LLM回傳的Action和Action Input再另外執行,直接透過Function Calling的效果其實更好。甚至目前的LLM能力已經可以在不強迫產生Thought的推論動作下模型就能順利解決問題。
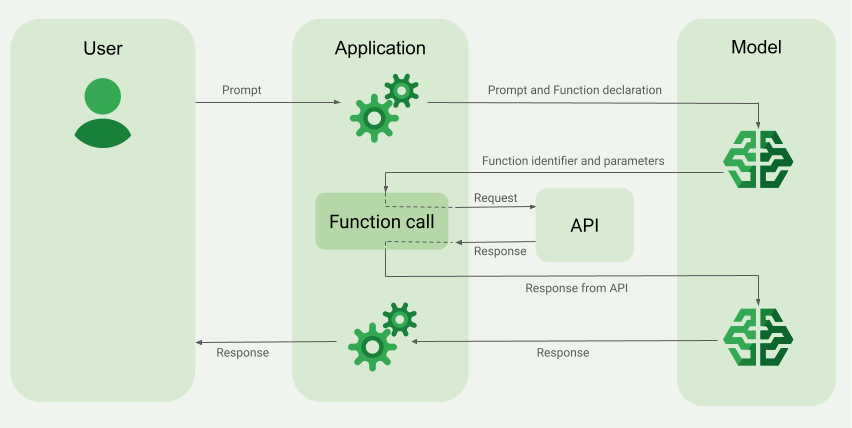
上一篇說明Langchain的SQL Agent範例如何透過ReAct Prompting實作,而目前LLM其實都已經具有Function Calling的能力,比起要解析LLM回傳的Action和Action Input再另外執行,直接透過Function Calling的效果其實更好。甚至目前的LLM能力已經可以在不強迫產生Thought的推論動作下模型就能順利解決問題。
上一篇透過Langchain SQL Agent建立資料問答系統中使用了Langchain的create_sql_agent來建立SQL Agent。Langchain在實作這個SQL Agent背後的使用了create_react_agent,這是基於2022年的paper “ReAct: Synergizing Reasoning and Acting in Language Models”的實作,雖然這個版本是比較早期的實作現在並不適合拿來使用在production環境,但仍可以透過瞭解SQL Agent是怎麼基於ReAct prompting技巧運作的。
上一篇解釋了如何透過Langchain SQL Chain建立資料問答系統。使用 LangChain 的 SQL Chain 可以將問題轉換為 SQL 查詢,這過程中會將不同的動作連結在一起,最後通過執行完整的 Chain 一步步地完成每個步驟,最終獲得結果。如果我們希望 LLM 能夠更主動地與環境互動並完成特定任務,就需要建立代理(Agent)。
上一篇透過Langchain SQL Chain建立資料問答系統中使用Langchain的sql query chain能夠快速開發資料問答功能。雖然Langchain提供了方便的開發模組,但卻封裝了許多與大型語言互動的細節。我們可以嘗試的從原始碼來看幾個Langchain封裝起來的細節。
在這篇使用大型語言模型(LLM)完成Text-to-SQL任務可以看到要把輸入的問題轉成SQL查詢,和LLM互動時會需要準備prompt,如果有自己準備prompt的話,就能在呼叫create_sql_query_chain帶進prompt參數。如果沒有的話,Langchain會預設使用sql_database的prompt。
延續上一篇使用大型語言模型(LLM)完成Text-to-SQL任務,在開發大型語言模型的應用程式時,可以採用像LangChain一樣的開源框架。LangChain目的在幫助開發者建立大型語言模型的應用程式,縮短開發時間並更容易的實現各種複雜的大型語言模型應用程式。
Text-to-SQL(Text2SQL)是一種自然語言處理(NLP)技術,旨在將自然語言文本自動轉換為SQL查詢語句。這項技術的核心在於將用戶輸入的自然語言描述轉換為結構化的SQL查詢,使這些查詢可以在關聯式資料庫中執行。
在現代化的數據平台中,通常會提供自助服務環境,讓使用者在獲得資料存取權限後,可以自行進行數據分析。然而,有時使用者所面臨的問題並不需要將資料匯入Power BI或Tableau等BI工具進行可視化分析,而只是希望在資料中透過查詢、篩選、聚合運算找到答案。
在這種情境下,對於不熟悉SQL的使用者來說,Text-to-SQL服務是一個很好的解決方案,因為它可以幫助使用者輕鬆地將自然語言轉換為SQL查詢,從而快速獲得所需的數據。
拜大型語言模型(LLM)的普及,Text-to-SQL可以很容易的透過LLM完成。以下透過建立Chinook這個SQLite範例資料庫來當作Text-to-SQL任務中查詢用的關聯式資料庫:
當專案已經準備要導入Cassandra時,可能是專案已經遇到某些困難與瓶頸,並已經考慮採用Cassandra是一個正確的使用情境。以下是使用Cassandra: The Definitive Guide, Third Edition其中第十五章的部份段落來說明如何將資料表轉移到Cassandra上。
要將關聯式資料庫轉到Cassandra上,第一個遇到的問題就是如何將原本的資料表關係轉移到Cassandra上。一種方式是將既有的資料模型作直接轉譯(Direct Translation),以下會舉旅館預約系統來說明如何對資料模型作直接轉譯。
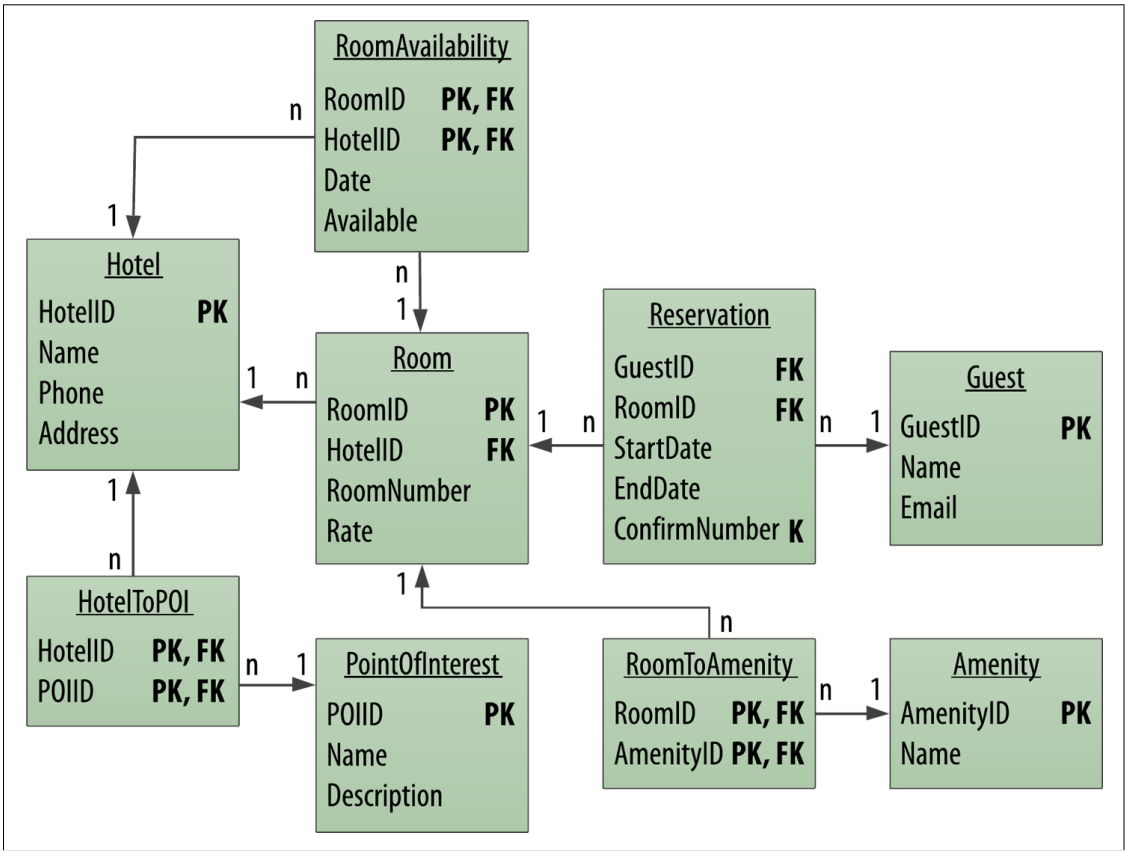
關聯式資料庫的使用者在使用Cassandra設計資料模型時,通常第一個會遇到的問題就是不能使用join。Cassandra明確說明不支援join,建議的方式為建立一個反正規化(Denormalization)的資料表。
有別於關聯式資料庫的正規化(Normalization)設計,透過減少資料庫內的資料冗餘(Data Redundancy)和去除相依性來增進資料的一致性。這種方式的缺點在當資料被拆成多個資料表後,依不同使用情境下將資料join起來查詢時,會導致效能不佳。
而反正規化則是相反,反正規化會增加資料冗餘或是對資料進行分組,來得到最佳化的讀取效能。所以在反正規化的實例中,會把預先join完的資料建成一張資料表,這時就會有同一份資料被複製成多張資料表的情況。
SQL開發者在查詢完資料後,往往會使用ORDER BY語法對查詢結果作排序調整。Cassandra的排序是對partition中的資料作排序,而且這個排序必須在建立資料表時就先定義好,並不能在查詢時使用任意的欄位改變排序。
Cassandra在建立資料表時定義的partition key決定資料存放的位置,並在每份partion中使用clustering key決定資料的排序,而且資料在寫入Cassandra時就會依據clustering key定義的欄位順序將資料排序好。
以下用員工表範例來作說明:
SQL開發者絕對少不了會使用聚合函式對資料作加總、平均、計數和取大小值,而Cassandra也支援了SUM、AVG、COUNT、和MIN/MAX的聚合函式。以下用員工表範例來作說明。