關聯式資料庫的使用者在使用Cassandra設計資料模型時,通常第一個會遇到的問題就是不能使用join。Cassandra明確說明不支援join,建議的方式為建立一個反正規化(Denormalization)的資料表。
什麼叫反正規化(Denormalization)
有別於關聯式資料庫的正規化(Normalization)設計,透過減少資料庫內的資料冗餘(Data Redundancy)和去除相依性來增進資料的一致性。這種方式的缺點在當資料被拆成多個資料表後,依不同使用情境下將資料join起來查詢時,會導致效能不佳。
而反正規化則是相反,反正規化會增加資料冗餘或是對資料進行分組,來得到最佳化的讀取效能。所以在反正規化的實例中,會把預先join完的資料建成一張資料表,這時就會有同一份資料被複製成多張資料表的情況。
怎麼將反正規化應用在資料設計
關聯式資料庫正規化設計
舉DataStax的課程DS220.08範例來說明。這個範例為電影資料庫被設計成videos、users和comments三張資料表。
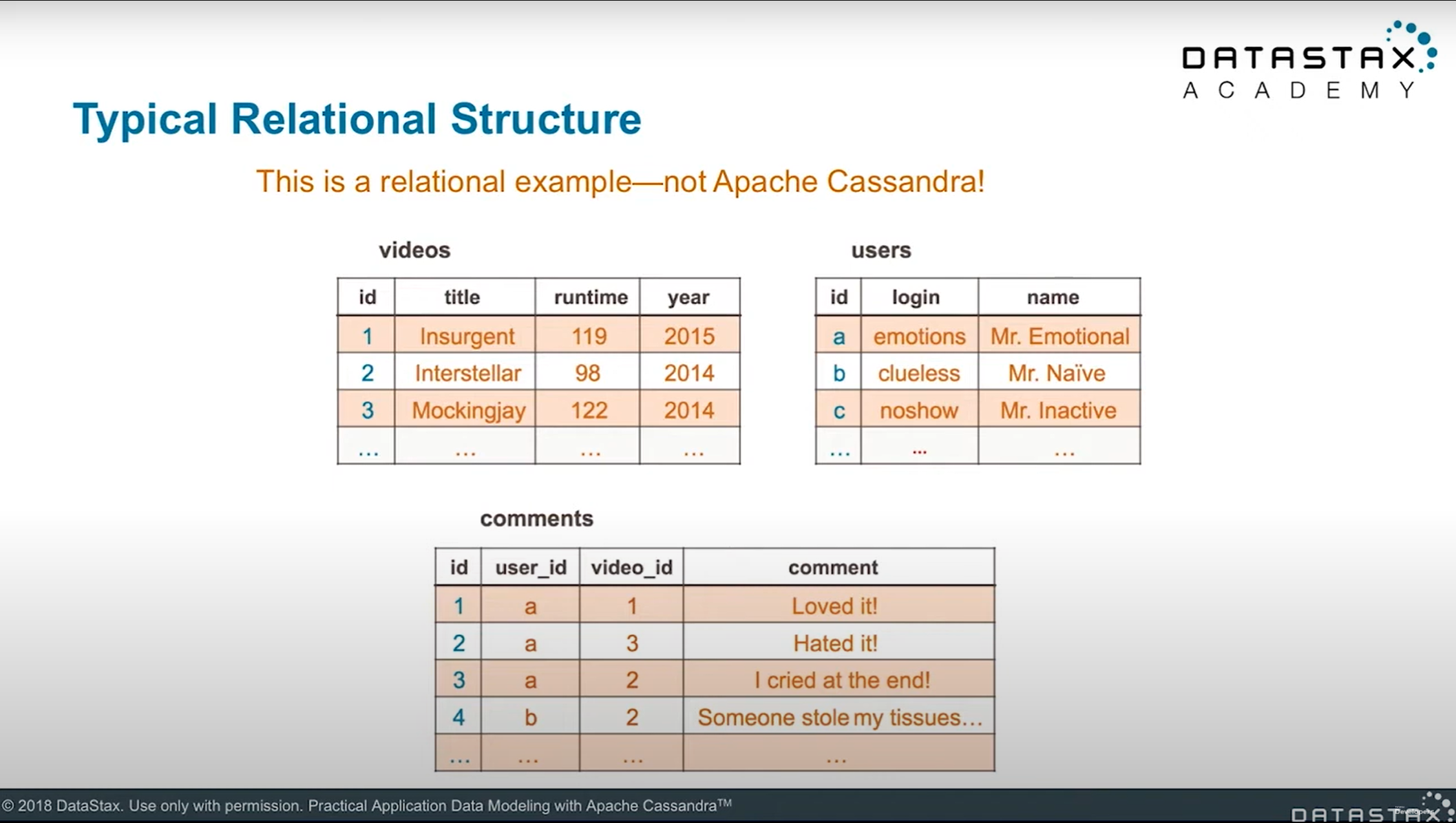
如果想要依電影標題查詢評論時,可以使用videos的id和comments的video_id將兩張表join起來,這時就可以使用videos的title欄位查詢出對應的comment資訊。

如果要依會員帳號查詢評論時,則是使用users的id和comments的user_id將兩張表join起來,接著就可以使用users的login欄位查詢出該會員帳號留過的評論。

Cassandra反正規化設計
在Cassandra的反正規化資料模型設計會直接建立成兩張資料表,並透過不同的primary key來提供兩種查詢方式。第一張comments_by_video會將video_title設定成partition key,第二張comments_by_user會將user_login設計成partition key。
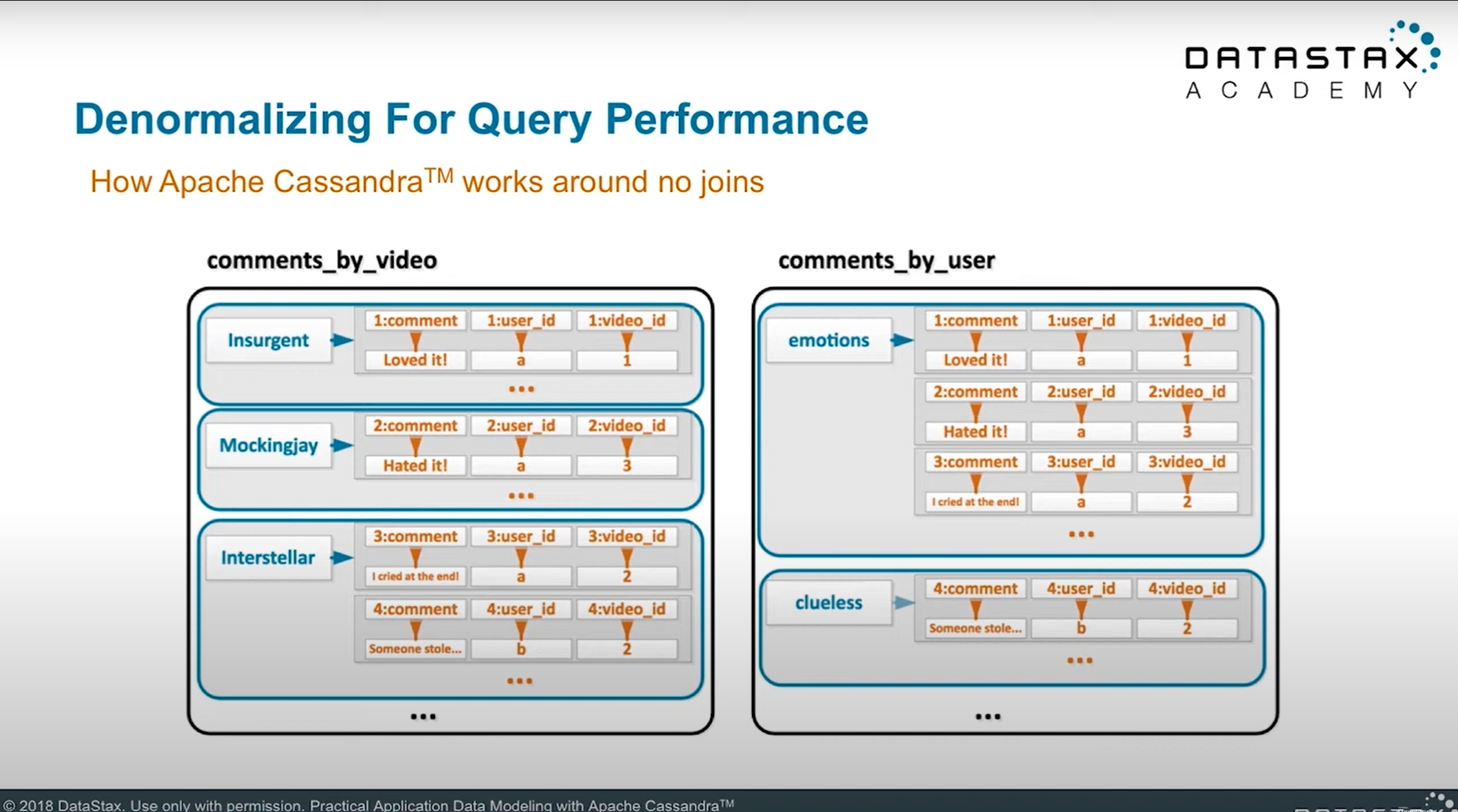
因為Cassandra會使用partition key決定存放資料的位置,因為在作Cassandra的資料模型設計時,要查詢的欄位都必須被設計成partition key才能達到最佳的查詢效能。以這個例子來說,這兩張表的建立資料表指令如下,可以看的出來兩張資料表幾乎有共通的欄位,只差在partition key的設計不同。

這就是反正規化中對資料作pre-join並且會將資料複製成多張資料表的作法。而目的就是為了要讓查詢的效能可以最佳化,不需要在查詢時面對可能不可控的join結果,或是複雜的join行為帶來的查詢效能低落。