在上一週的課程中,我們使用了one-hot結合詞庫來將句子作量化處理。但是使用one-hot的缺點是每個詞被視為獨立的,也就是無法衡量出兩個詞之間的相似或與重要性(兩個one-hot vector內積都會為0)。所以當你想知道apple和orange之間的關係比起apple和king還接近,就無法單純的使用one-hot來作文字的量化。其中一個方法是可以用不同的特性來作量化,比如說使用性別、是否為食物等等的特性,這個時候便可以辯識出具有相同性質的詞。

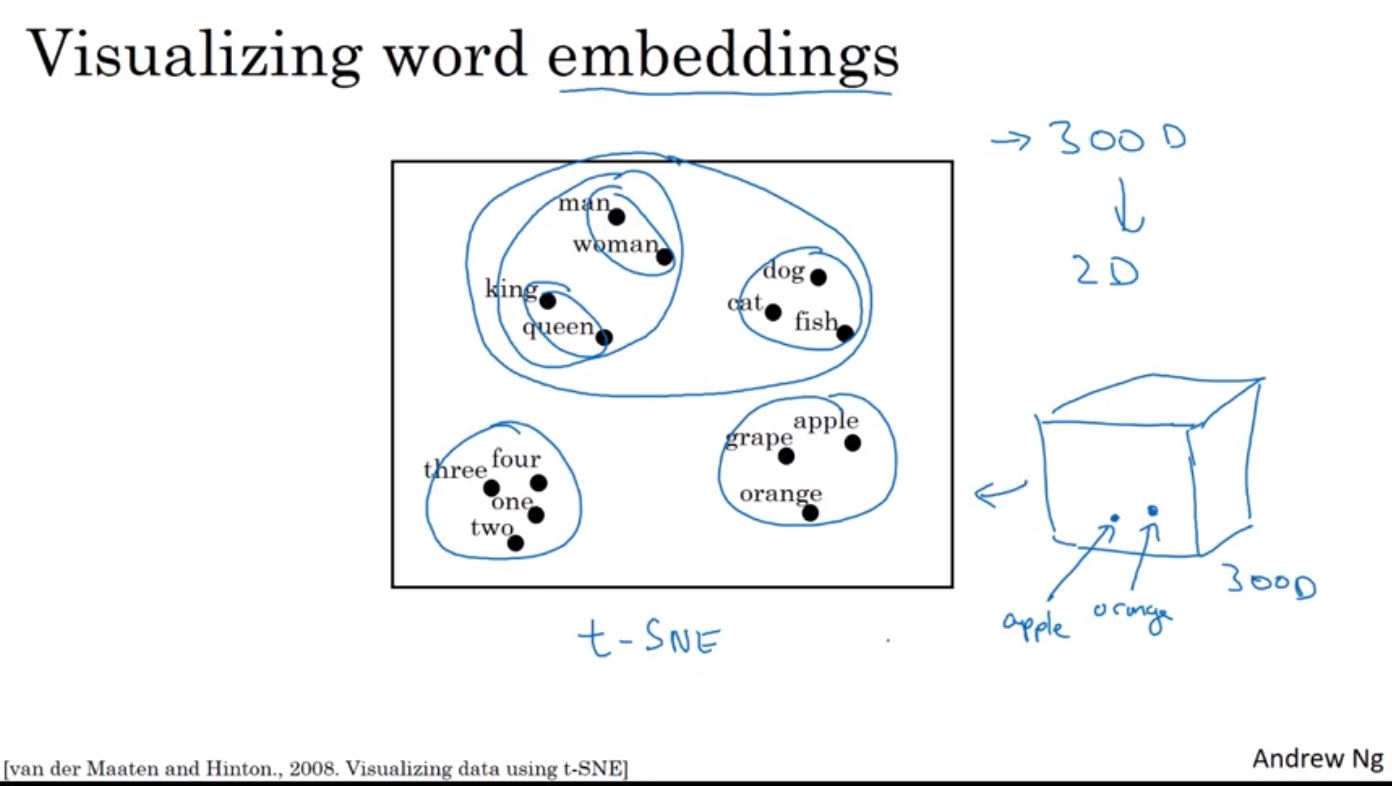
這種量化文字的方法又可以被稱為Word Embedding,像是每個詞會嵌在高維度的特徵向量中,即每個詞都可以在高維度的特徵找到一個能表示它的位置,而如果要將多個維度的特徵壓縮到兩維來表示,可以使用t-SNE演算法來找到相同的詞會彼此較相近。
使用Word Embedding的好處除了可以判斷出兩個詞之間的相關係,也對Transfer learning有很大的幫助,即使用已經訓練好的word embeddig來用在新的任務。在使用word embedding於transfer learning有幾種方法。1. 從大量的詞庫(1-3B)中進行訓練(或是下載已被訓練過的) 2. 使用原本已建立的embedding並transfer到新的而且訓練資料集較小(1-3k)的任務 3. 持續的使用新的資料來對embeddings進行finetune。
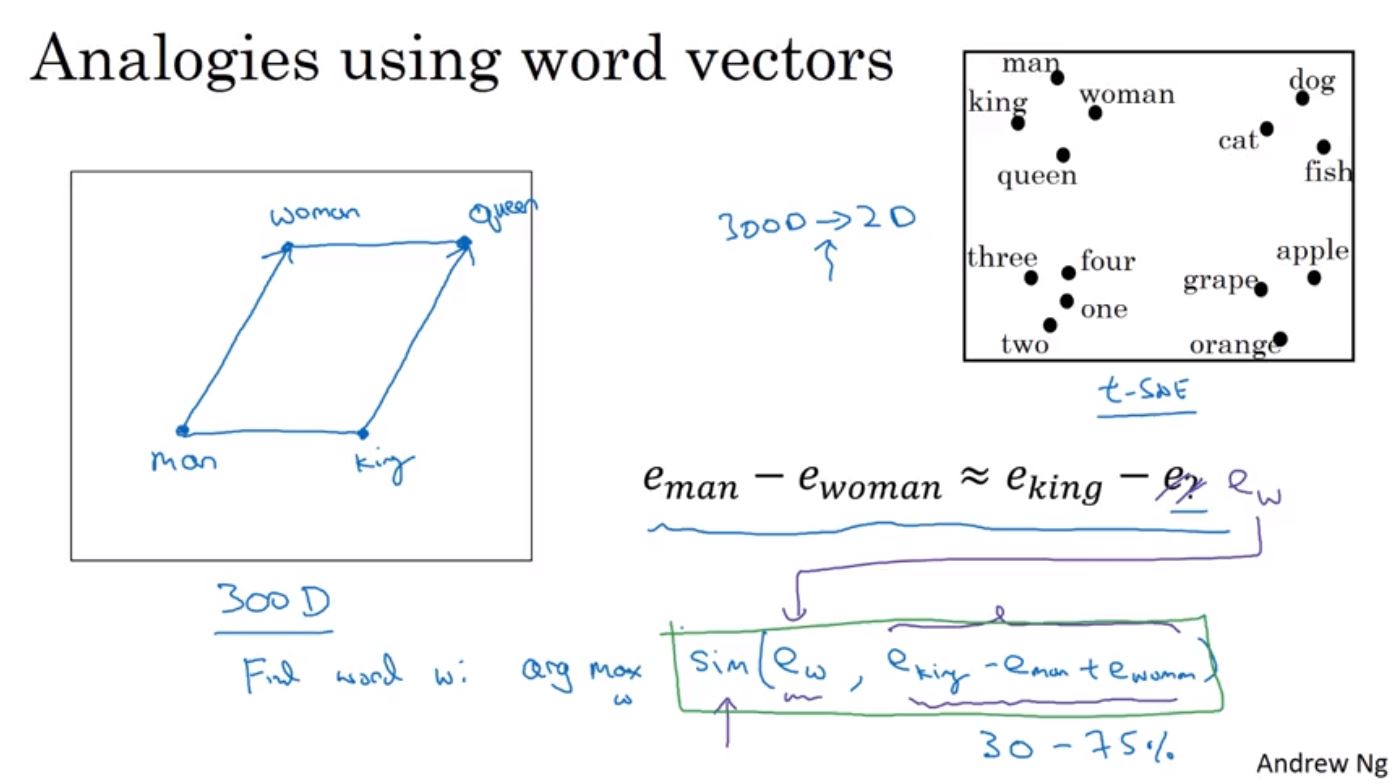
Word Embeddings也可以作到比擬(analogy),比如說Man之於Woman等同於King之於Queen,這可以透過向量相減來找到相似的結果。

實際上要基於Man與Woman的關係來找到King和某個詞,可以透過向量相似度的計算來找到,只要找到King和哪一個詞的相似度與Man和Woman的相似度最接近即可。這裡的相似度計算是從原始的高維度(~300D)來的,雖然可以透過t-SNE來將高維度使用非線性的轉換到2維空間作視覺化,但如果使用了轉換的2維來計算反而會失真,所以在實際上的相似度計算會使用原始的高維度向量空間。
一個常用的相似度計算是Cosine similarity,即計算兩個向量的角度來判斷兩個相向之間的相似度。Cosine similarity也經常被用在文本分析中,透過計算代表兩筆資料的高維度向量,來評估兩筆資料的相似度。

Word Embedding的學習最終會得到一個Embedding Matrix,凡是把這個矩陣乘上某一個詞的one-hot向量,所得到的即是代表這個詞的embedding。因為one-hot是高維度而且幾乎都是0的稀疏矩陣,所以在實務上並不會真的相乘,而且透過特別的方法來找到詞的embeddings。

在word embeddings的學習演算法中,過去往往會使用很多很複雜的演算法來學習,但後來卻發現很多簡單的方法就可以達到很好的效果。在複雜的方法中,比如說要預測一句話的下一個詞,可以把每個詞的word embeddings輸入到一個類神經網路學習,最後訓練出我們要的embedding matrix(E)。如果有300維度,那麼要輸入到網路裡面的維度就會多達300乘6共1800維,也可以選擇只看前4個詞來學習,那麼維度就會降到300乘4共1200維。

不過事實上用簡單一點的模型也可以訓練出好的效果,比如說只用預測詞的前一個字,或是最接近預測詞前一個詞的詞(又稱為skip gram)來訓練word embeddings matrix。
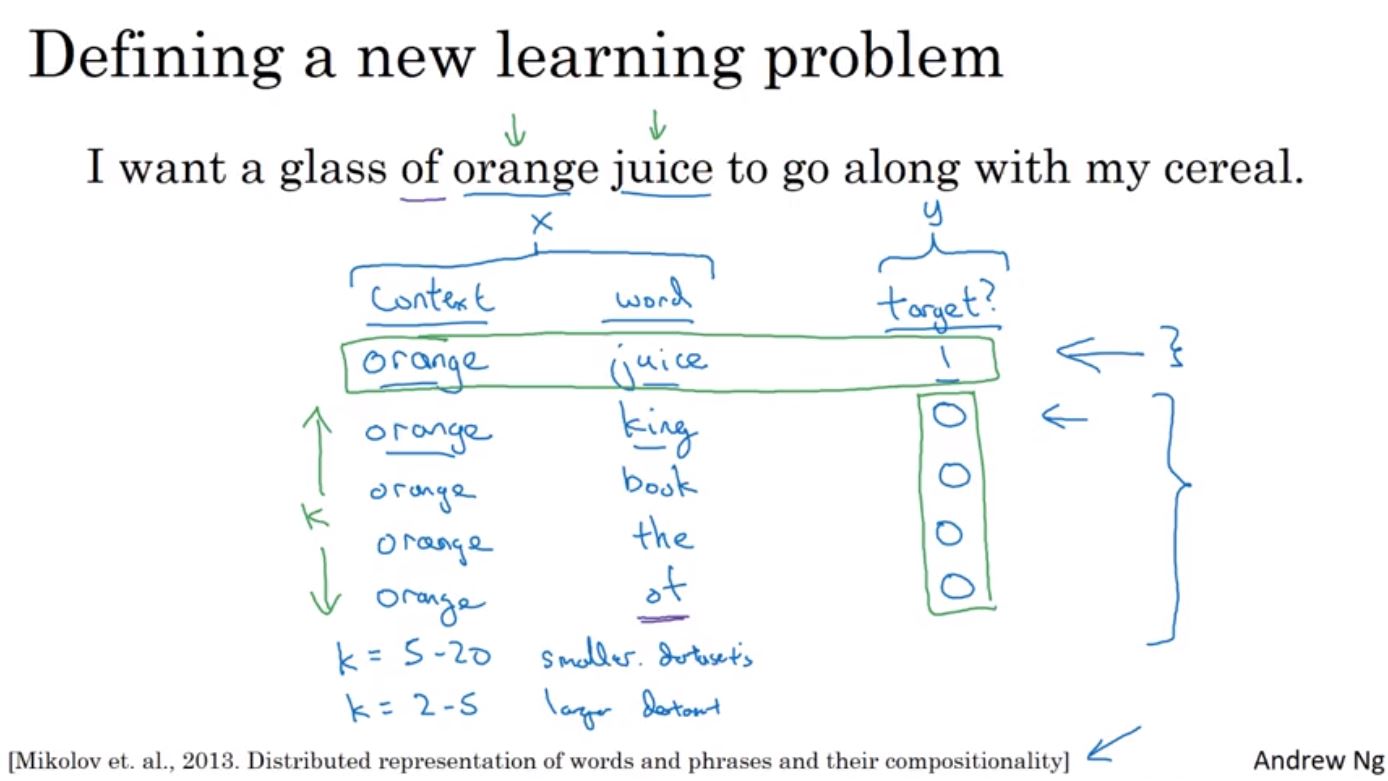
這裡介紹Word2Vec的Skip-grams模型,Skip-grams在選擇Context與Target組合時,針對Target可透過隨機挑選的方式選出不同的組合,比如說Context詞的+-5~10個詞來選出Target詞。

再來將這些對應的組合透過matrix E轉成word embeddings後丟入神經路網學習,接著經過softmax後計算loss function來訓練出matrix E。

但這個方法的主要缺點在於需要大量的計算,因為在計算softmax時,分別需要加總所有詞,如果詞的數量越多,那麼速度就會越慢,因此很難擴充到大型的訓練詞集。一個解法是使用hierarchical softmax,先拆出詞位於哪個部份(前或是後五千詞),接著再接續往下作二元拆解。在tree的結構可以把常出現的通用詞放在上半部,這樣就可以較快的被找到。

因為skip-grams在計算softmax需要花費大量運算,使用Negative Sampling則可以避免這個問題。Negative Sampling首先會先建立postive pair和negaive pair,比如說orange和juice會一起出現,就給予label 1,然後再隨機選出其他K個詞和orange組成negative pair給予label 0(即便某些時候negative pair組合真的有一起出現也沒關係)。最後將這些組合透過監督式學習訓練模型。
接著可以使用logistic regression來計算在給定label為1時,postive pair組合的機率,並使用K+1組資料進行訓練,然後再將這個分類器應用在10000個詞作二元分類。因此比起原本作skip-grams要一次訓練10000組資料,使用negatiev sampling的方法只需要用少量的資料訓練,再一次用在多組詞的分類。

但是該如何去選擇negative sampling呢?一個方法可以從詞出現的頻率選起,但是很容易選到停用詞(stop word);或是假定他是均勻分配,使用1/|V|來選擇,而在這篇論文裡面是用了每個詞在訓練詞庫中出現的3/4次方來計算機率作選擇。

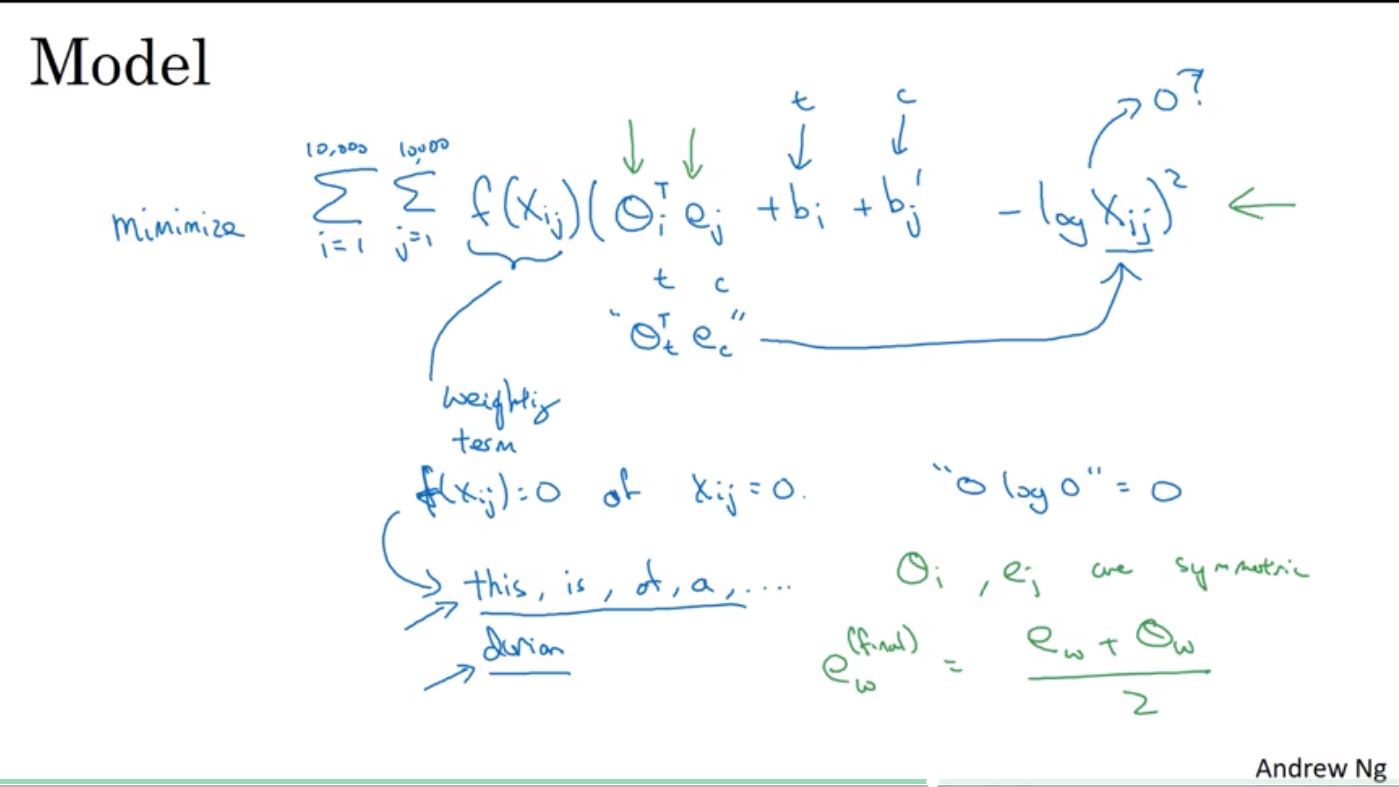
另一個學習方法為GloVe,首先會計算context和target一起出現在訓練資料的次數,Xij會等於Xji如果是用target的正負距離來選擇context,但是如果只看target出現在context後面,就會不相等。

GloVe的模型中為了避免Xij為0,因此會乘上一個權重f(Xij),如果Xij為0則f(Xij)為0,當然這個函式也可以用來給予不同詞頻的詞有不同的權重處理。
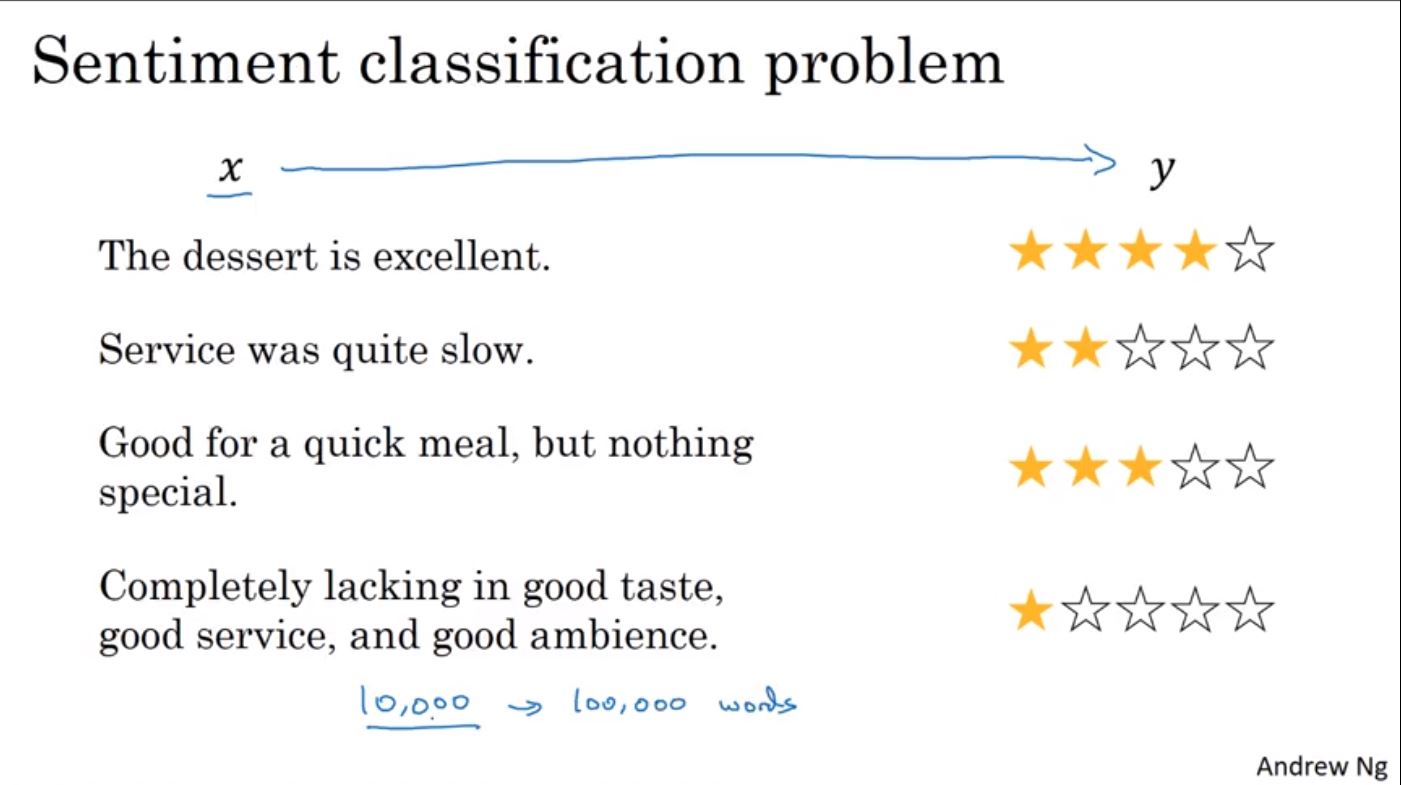
情感分析(Sentiment Analysis/Classification)是NLP其中一種應用,主要用在判斷文本中是表達喜歡或是不喜歡(正或負)。比如說,輸入的X為評論的內容,輸出Y為評論的情感等級,像是從網路評論中判斷對於餐廳或是旅館的正負評論。其最大的困難在於情感分析缺乏大量的標記資料來學習,如果使用word embedding可以幫助在少量訓練資料的情況下學習。
在建立情感分析模型時,一樣使將每個詞透過embedding matrix選出該詞的embeddings向量,接著透過加總或是取平均值後,再使用softmax函式得到輸出Yhat。不過因為這樣的方法是沒有前後順序的,所以如果遇到明明有否定詞在前面,但是後面出現很多的正向詞good,這可能就會造成誤判斷把明明是一星的評論判成五星,因為出現很多次的good會把結果導到正向,這個時候就需要使用RNN來建立模型。

使用RNN一開始也是將每個詞透過embeddings matrix找到該詞的embeddings向量,接著將每個詞輸入進RNN,最後再接softmax判斷結果,這個就一開始提到的Many to One的RNN類型。因為RNN是會有順序性的,所以對於出現否定詞的句子能夠處理的比較好。因為word embedding可以從較大的訓練資料訓練出來,所以即使在情感分析的訓練集裡面缺少了某些詞,但這些詞有被word embedding訓練過,這樣在作情感分析時也可以得到較好的結果。

在word embeddings的訓練過程中,可能會造成帶有偏見的學習結果,比如說本來是希望學出Man之於Woman等於King之於Queen,但可能會學習出Man之於Programer對於Woman之於Home_keeper這種帶偏見,或是Father之於Doctor對於Mother之於Nurse這種錯誤的結果。因為機器學習現在已經越來越普及的被應用在許多不同的領域上,所以這種帶偏見的錯誤結果應該要被避免的。

解決這種錯誤的學習有不同的方法,以解決性別偏見為例來說明,第一先將girl-boy和mother-father來找到屬於性別的分界向量,這時把任一個詞和這個分界向量作內積,就可以找到這個詞會偏向哪個性別,並找出bias direction,要讓不能帶有性別偏差的詞向量去除bias。透過Neutralize將一些對於性別來說屬於中性的詞,將其投影到non bias的方向軸,最後為確保像是doctor這種應該屬於中性的詞,與帶不同性別的詞(像Girl或是Boy)距離要是相同的,會使用Equalize pairs的手法將帶性別的詞移動到以軸為中性對稱的位置,這樣就會讓兩者與doctor的距離或是相似度是相同的。在選擇哪些詞需要進行Neutralize,可以透過練一個分類器來分辨;在選擇要equalize的部份因為較少量,所以可以簡單透過人工挑選的方式完成。
