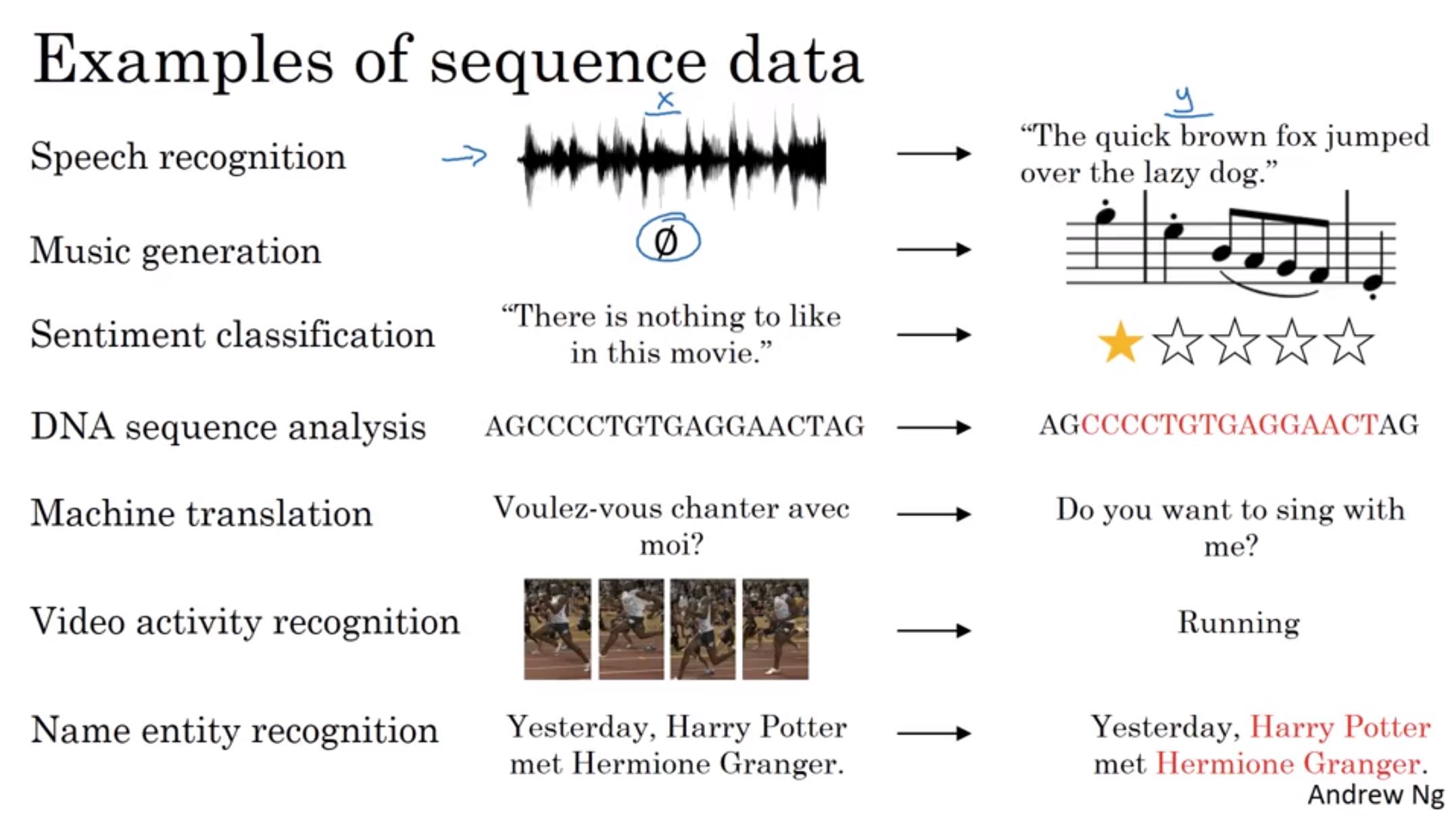
有序列性質的資料(sequence data)可以泛指輸入資料(X)是有序列的,或是輸出資料(Y)是有序列的。比如說在翻譯問題上,輸入和輸出都是有序列性的句子;但在情感分析問題上,輸入會是一個有序列性質的評論句子,但是輸出為情感的等級或是分數。
量化句子的方法可以使用詞庫加上one-hot encoding,可以透過自己建立或是使用已存在的詞庫,並將詞庫使用one-hot encoding作編碼來將文字資料作量化產生可以用來學習的輸入資料X。

如果使用一般標準的類神經網路會有什麼問題呢?1. 每一個訓練資料的輸入和輸出的長度不同,不好處理。2. 在不同文字中的不同位置無法學習出共同的特徵。如果要像CNN一樣能夠在不同的訓練資料的不同位置中學習到共同的特徵,就必須要透過RNN來達成。
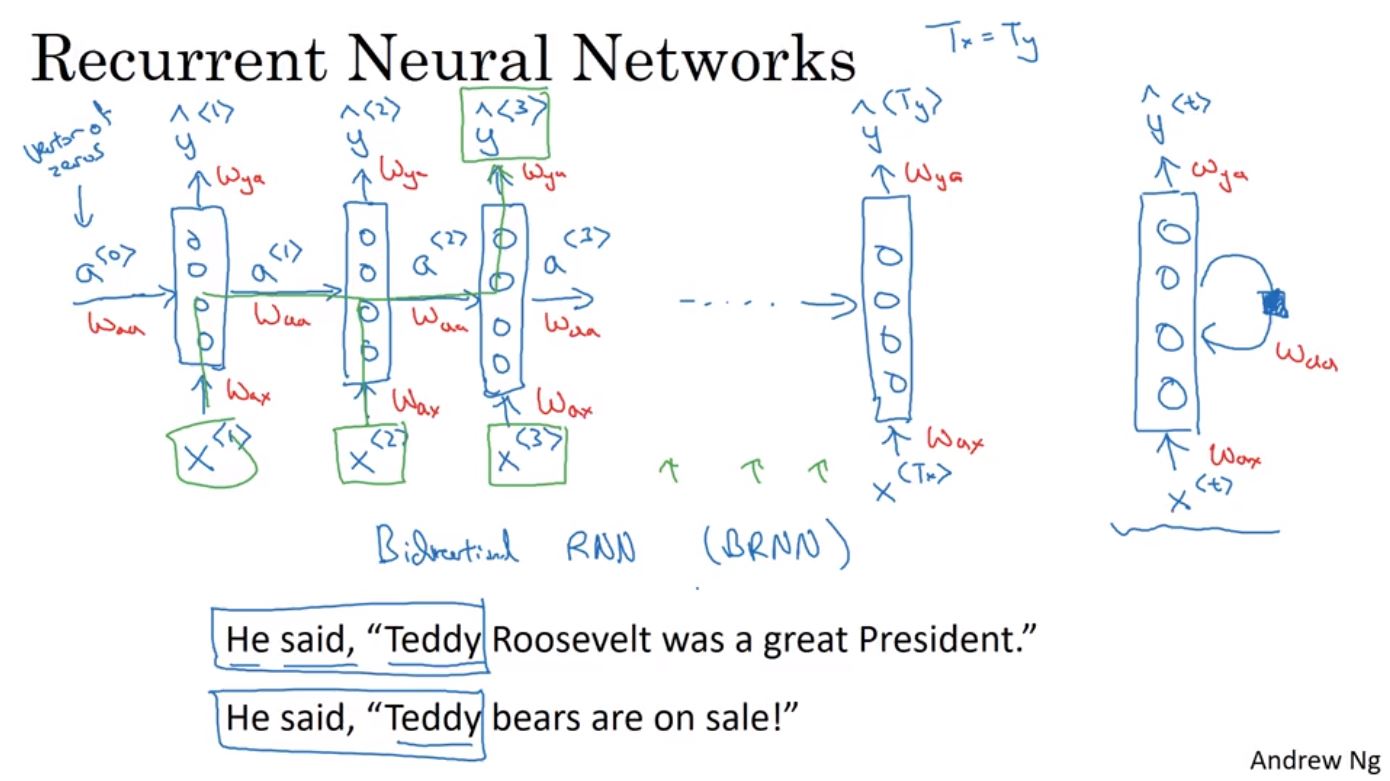
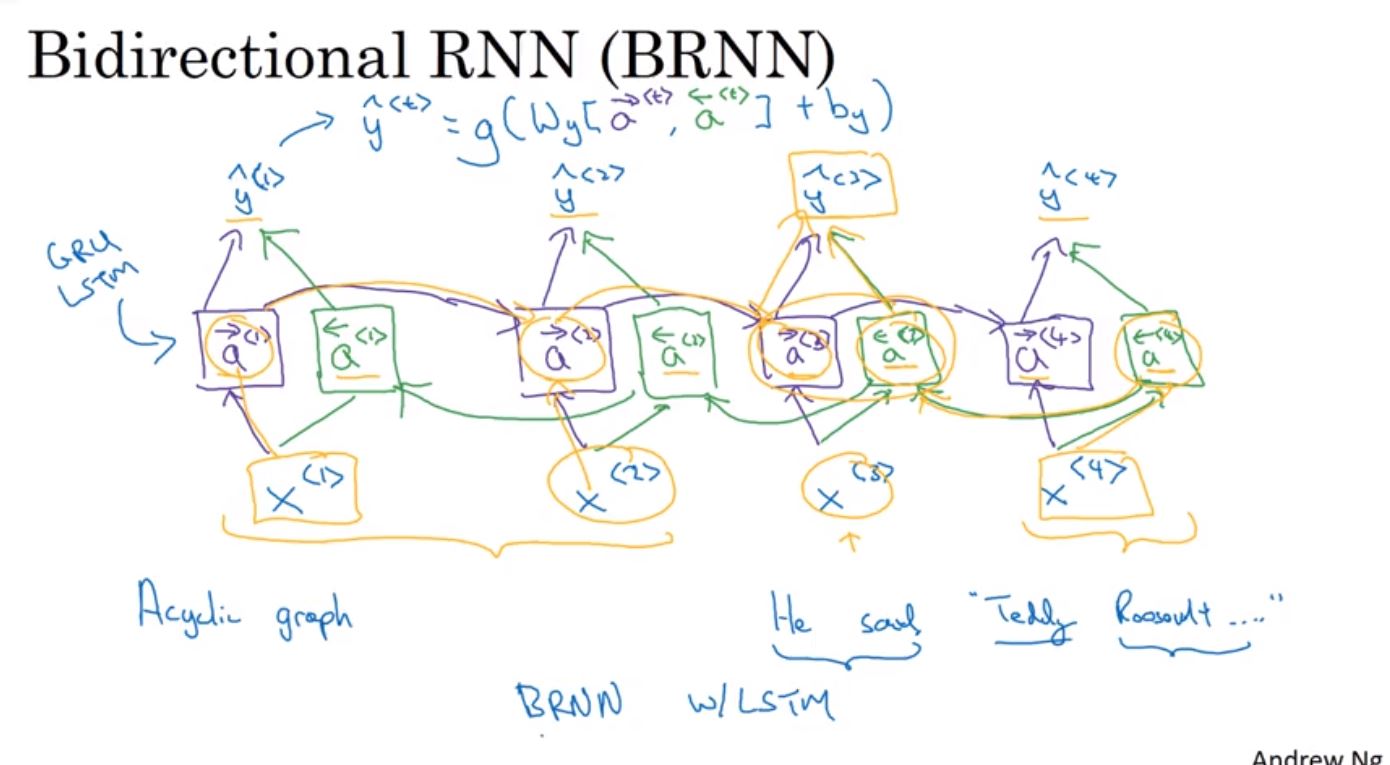
Recurrent Neural Network(RNN)在每個訓練樣本會共同相同的weight和activation function。RNN會將每一個字詞X< i >經過激活函式後的結果,再傳給下一個字詞X< i+1 >,所以每個字詞會拿到由前面傳遞過來的資訊。但是只拿到前面字詞的資訊是不夠的,例如在判斷Teddy時,就需要使用字詞後面的句子內容,才能夠有效的區分Teddy究竟是指總統還是玩具。這時會使用到雙向的RNN(BRNN)才能夠解決這個問題。

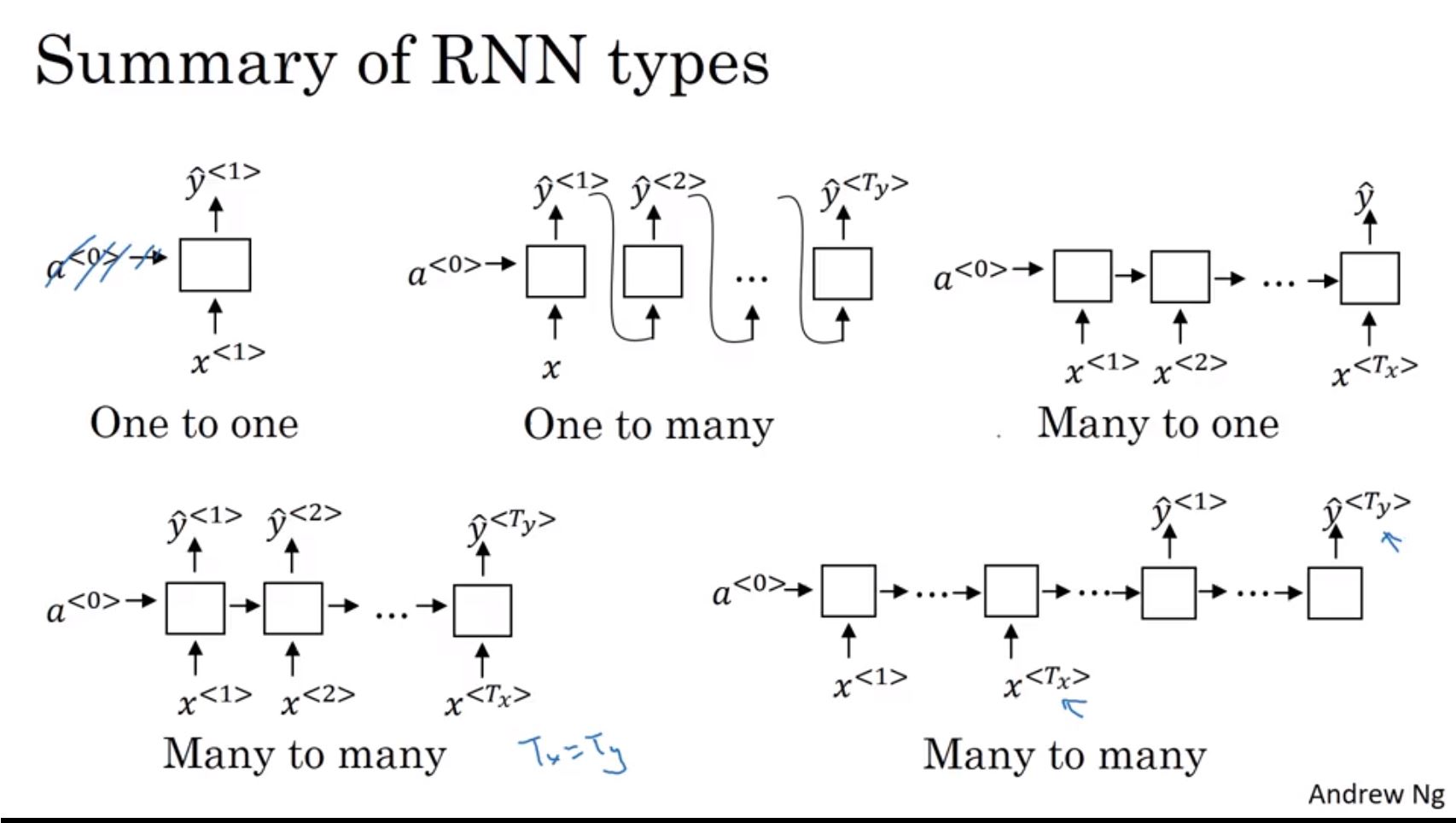
前面有提到RNN的輸入和輸出長度可能會不一樣長,針對不同輸入輸出長度可分為不同類型的RNN。在翻釋問題上,不同的語言可能翻譯後的長度都不同,這是一個Many to Many問題;如果是情感分析會將一則評論輸出成正反或是1到5星等級,屬於Many to One問題;One to Many會適用在像是音樂生成,給定一種音樂類型來產生一首音樂;One to One這種類型就是一般的神經網路了。
RNN可以被應用在建立語言模型(Language Model),例如在語音辨識中,透過語言模型可以透過計算不同輸出句子的機率,來辨識出哪一個句子是最符合的輸出。

把每個句字斷詞並量化後,就可以丟進RNN來建立模型。舉例來說,在訓練時,將第一層RNN輸入空向量,再將本來的實際詞Y< i >從第兩次RNN依序丟進去訓練,就可以建立模型來預測某段句子後會接什麼樣的詞。即輸入Cats average,判斷下個接每個詞的機率。所以可以透過將每個詞依序輸入來計算出在給定某個句子下,輸出某個詞的機率。在這裡可以透過外部詞典,並使用softmax來算出每個詞的機率
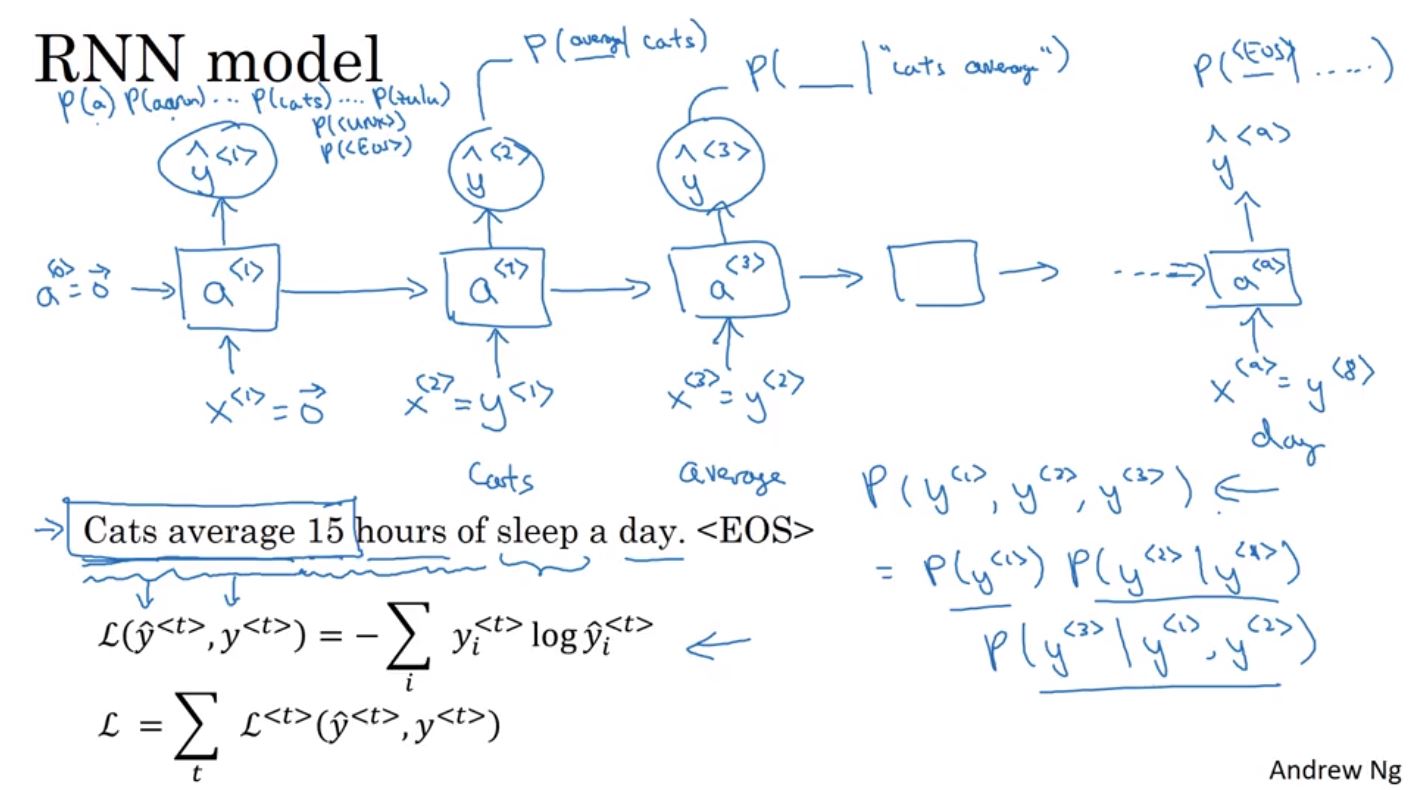
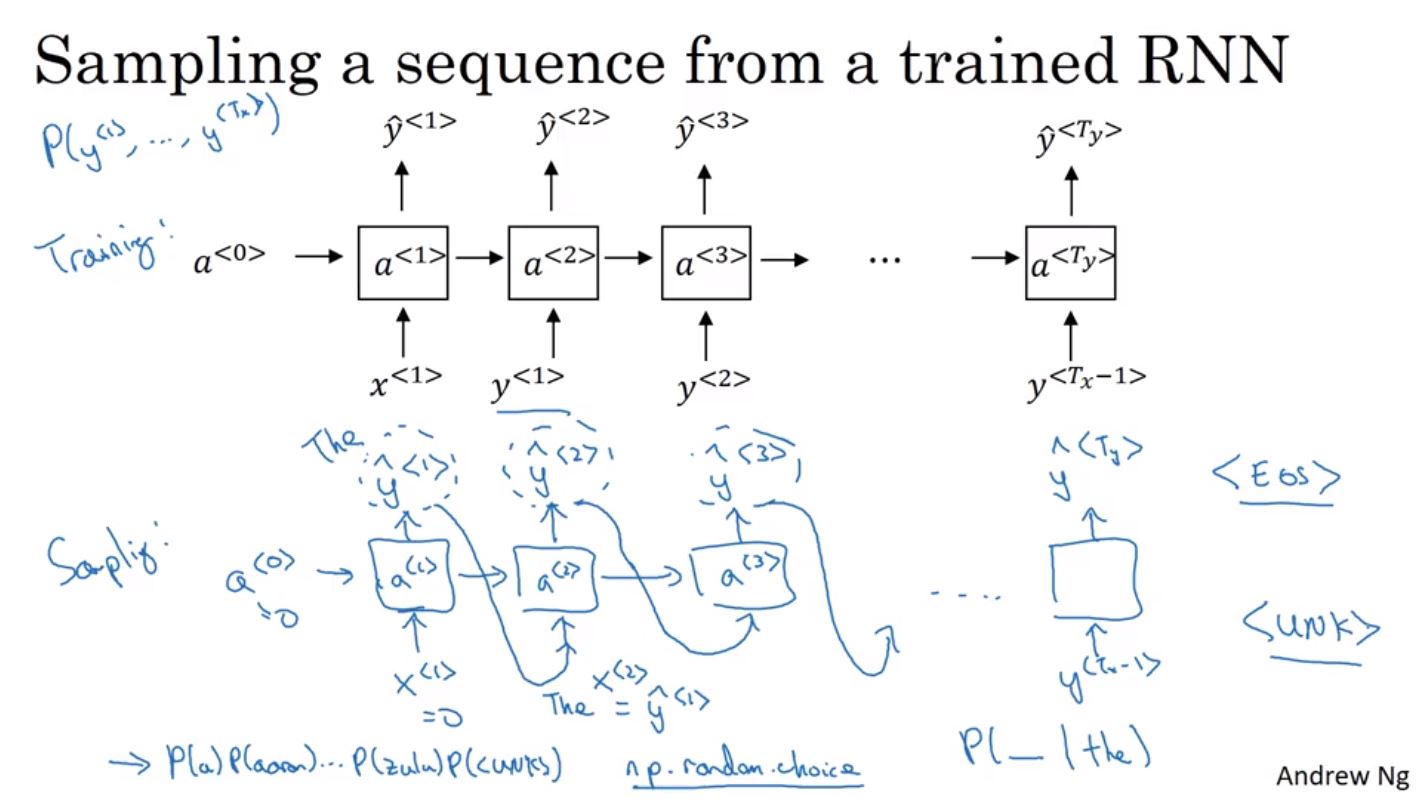
進一步我們就可以使用這個模型來隨機的產生句子,首先先隨機選出一個詞,接著將每個詞依序丟進下個結點來產生新的詞,直到取出字尾EOS或是設定一個固定的句子長度終止。
除了使用詞(Word-level)來組成句子,也可以使用字元(Character-level)來建且模型組成句子。如果使用字元來組成句子,那麼每一個輸出就是一個字元而非一個詞,好處在於不用怕取到辭典裡面沒有的詞,壞處則會產生更長的句子,也會降低訓練速度,所以目前經常是使用詞來建立模型。
梯度消失(Gradient Vanishing)
如果句子太長的話,使得神經網路過於深,會讓梯度在作back propagation時很難影響到前面的layer,產生梯度消失現象。對於RNN來說,實際上的影響在於如果太前面的神經元,將會無法去記住前面的詞(例如區分單數詞或是複數詞)。因此,傳統的RNN的輸出結果主要會受到接近神經元的影響,較遠的神經元不容易影響到最終的輸出。比起梯度爆炸容易被發現與處理,梯度消失反而不容易被處理,而且更容易影響到RNN的訓練結果。
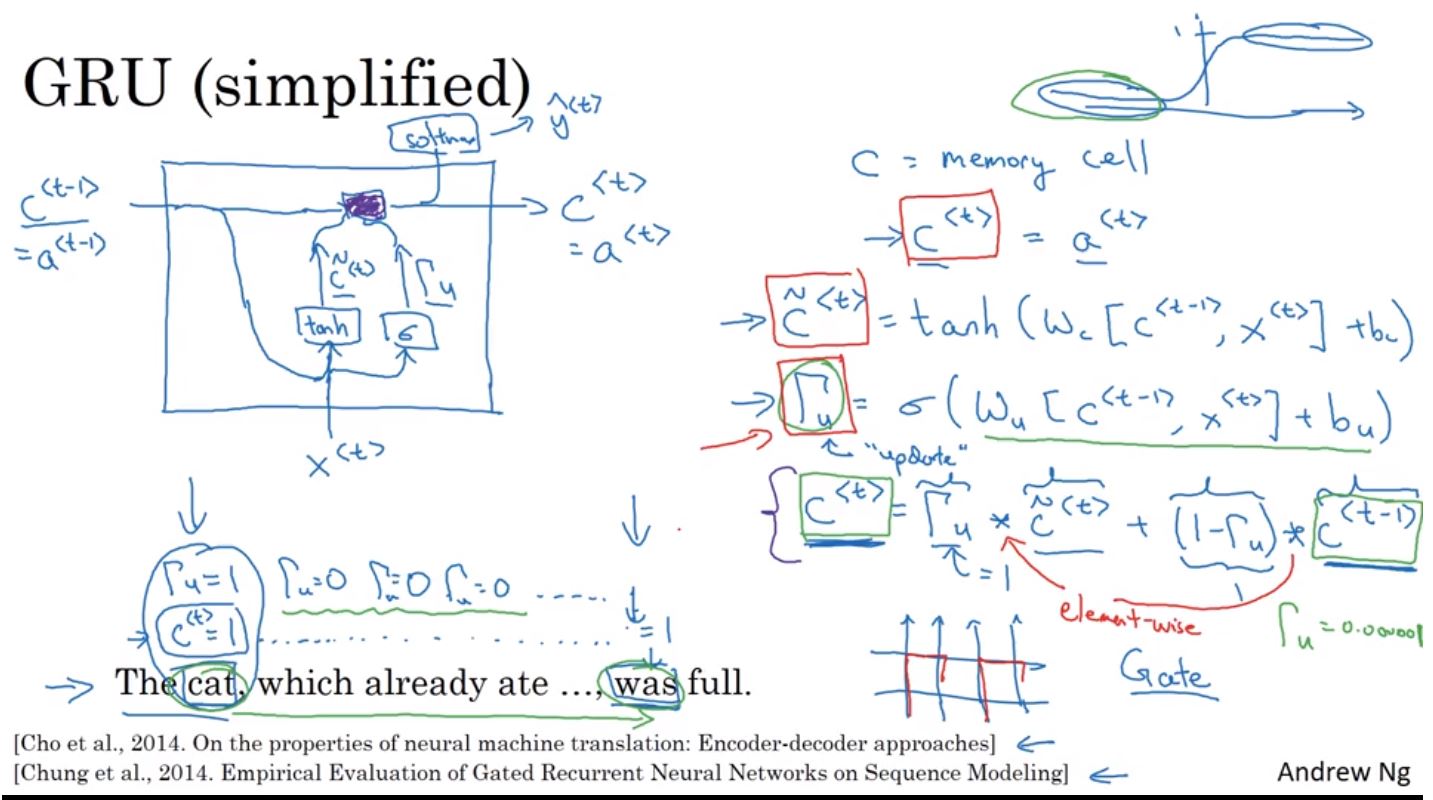
Gate Recurrent Unit(GRU)是一個改善RNN長期記憶問題的方法,他引入了memory cell(C)的概念,在這裡的C就等同於activation function的輸出a,這個memory cell會將長期的記憶儲存下來,並用一個帶使用sigmoid轉換後的Γu值來判斷要不要選擇忘記之前的記憶並更新,還是要保留之前的記憶,直到不需時再忘記。實際上為什麼應用GRU會改善梯度消失的現象,主是要在Γu值透過sigmoid轉換後如數數值很小那麼就可能會非常的接近0,在這個情況下,C< t >就會非常接近C< t-1 >並很容易的保存較遠的記憶來大幅改善梯度消失的現象。
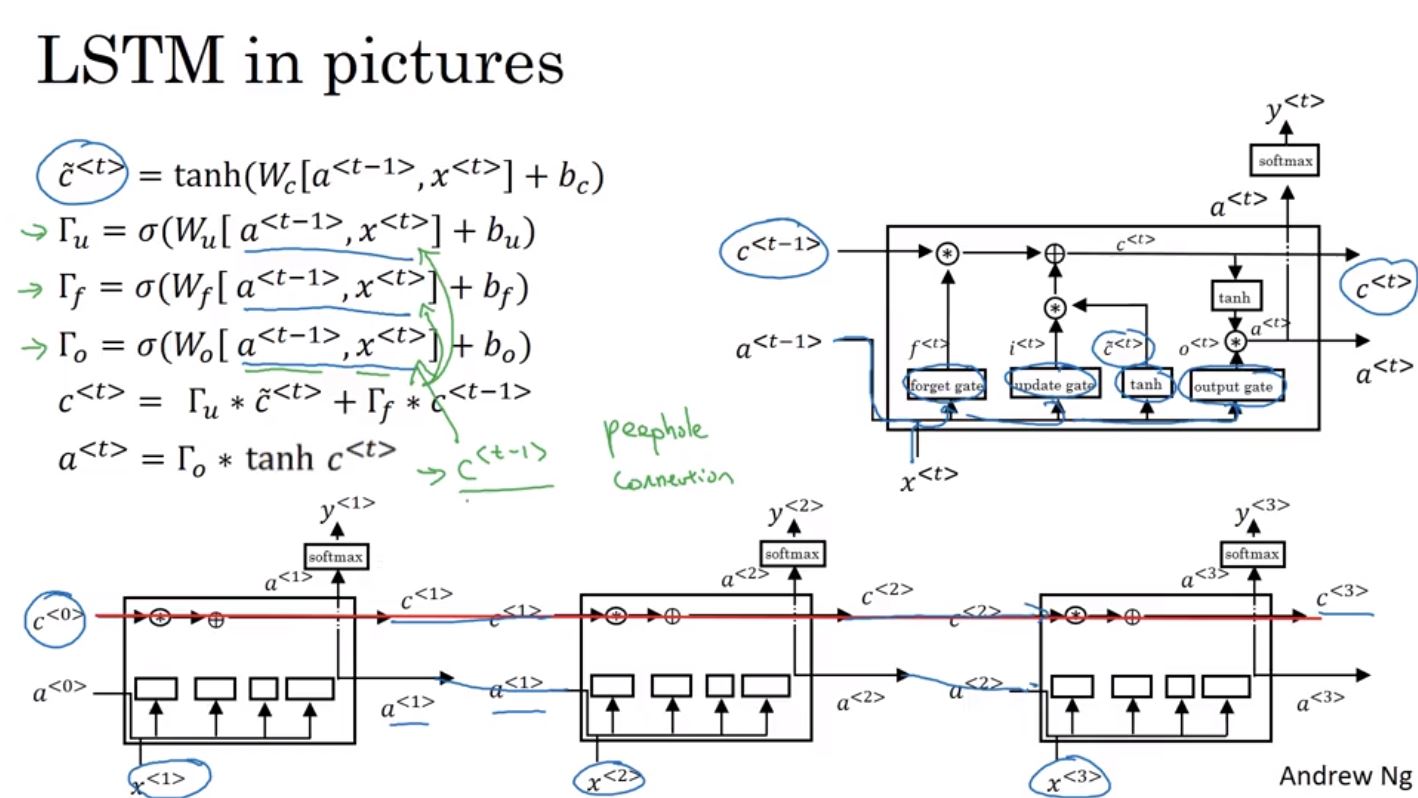
另一個常用的方法為Long Short Term Memory(LSTM),在LSTM裡面C不再等同於a,LSTM會用到3種gate,分別為update gate, forget gate和output gate。

透過update gate和forget gate來決定是否保存較長遠的記憶,並透過output gate來輸出a到下一個神經元。
如果要同時合併前後神經元的資訊,就得使用Bidrectional RNN(BRNN)。BRNN除了從左到右作forward propagation外,也會從右到左作forward propagation。在輸出資料時,會同時輸入兩個方向進入activation function。而其中每個神經元也可以是GRU或是LSTM,所以實務上也會使用LSTM結合BRNN來建立模型。
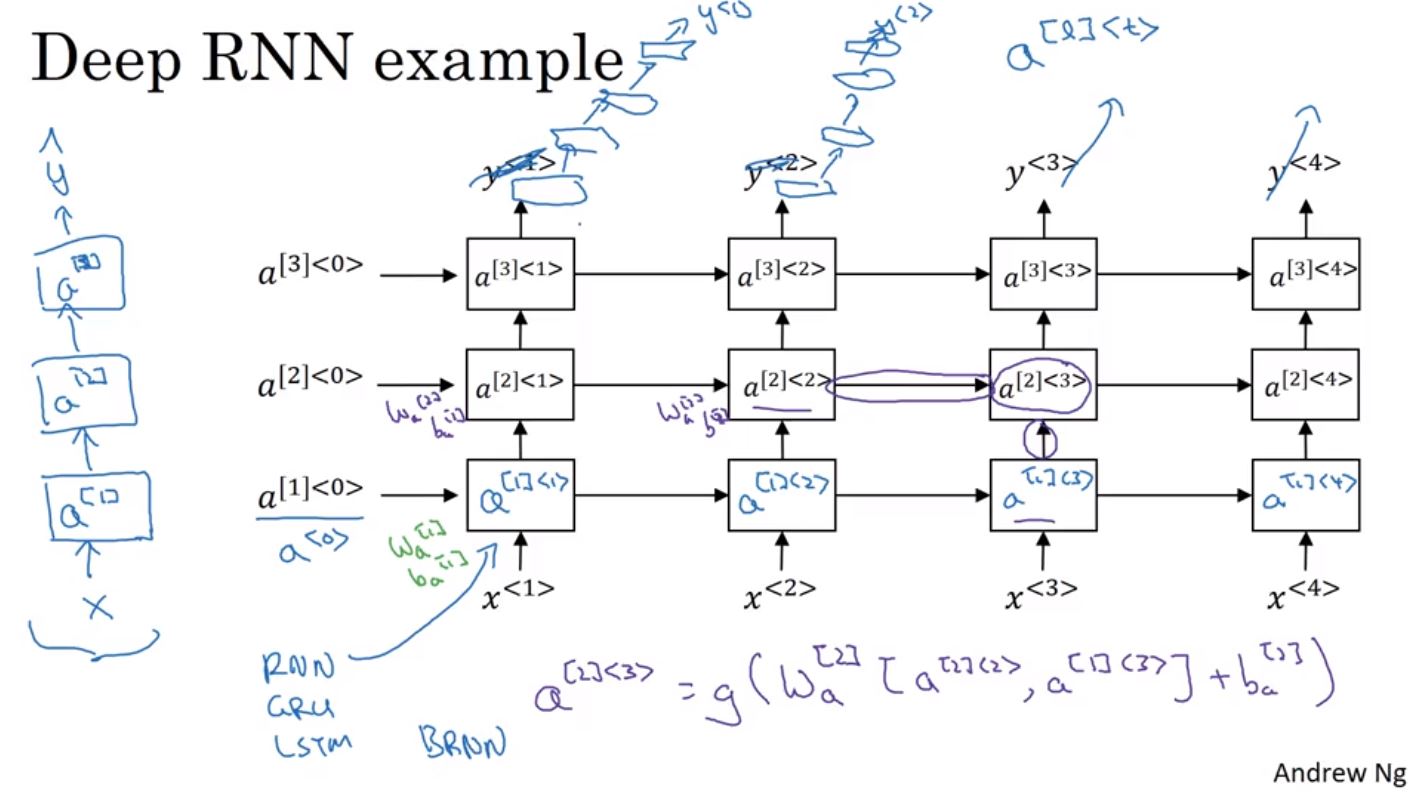
RNN可以疊多層起來變成深度的RNN模型,本來RNN每一個順序都只有連接一個神經元,但也可以在每一個序順接處多個神經元來建立深度的RNN模型,甚至結合GRU和LSTM與BRNN來建立複雜的RNN模型。不過因為深度的RNN在訓練是非常耗資源的,所以不太常見到超過3層的RNN模型。