上一講談到logistic regression,這一講會講到到底該如何使用線性的模型來作二元或是多元分類。
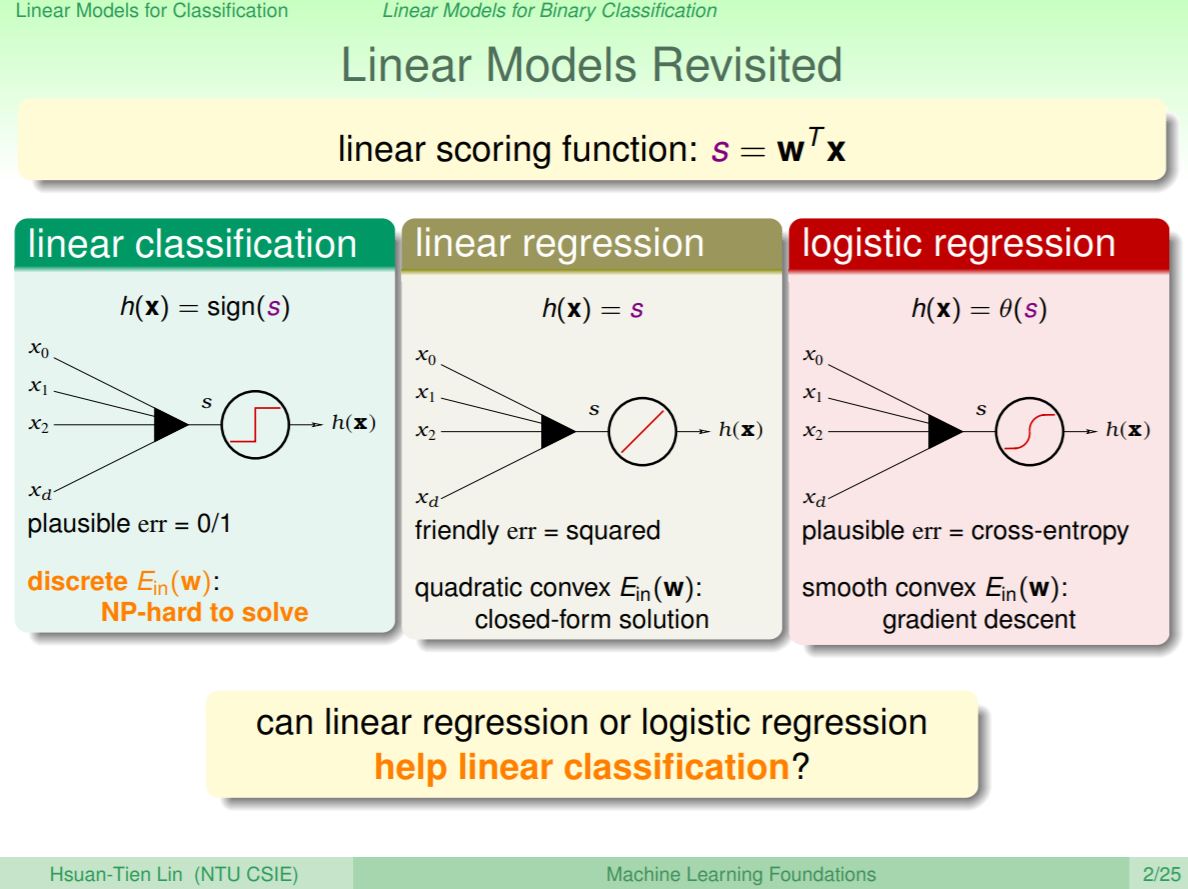
複習一下三種線性模型,共同點就是三種都會透過計算分數來作分類,差別在於PLA的線性分類會將分數取正負號來達到0/1分類,線性迴歸則是直接輸出分數,並使用squared error評估找到最佳解;logistic regression則是會透過logistic function將分數轉換成0到1的機率值。

為了將線性模型作二元分類(y=-1/+1),可以把error function稍微整理算出yx項,這個yx項的實際意義為分類的正確性,也就是yx項得到的分數要是正的(即兩者同號),而且越大越好。

再來將三種模型的error畫出來,可以發現三種error的特性都不同,唯一相同地方在於如果squared和scaled cross-entropy很低時,通常0/1也會很低。

究竟linear regression和logistic regression是否是好的分類方法呢?先從VC的角度來看scaled cross-entropy他會是0/1 error的upper bound,所以如果把logistic regression的cross-entropy error作到最小的話,也就可以說我們能把0/1 error也作的好。當然sqr err也是一樣,所以linear regression和logistic regression確實是可以作到二元分類的。
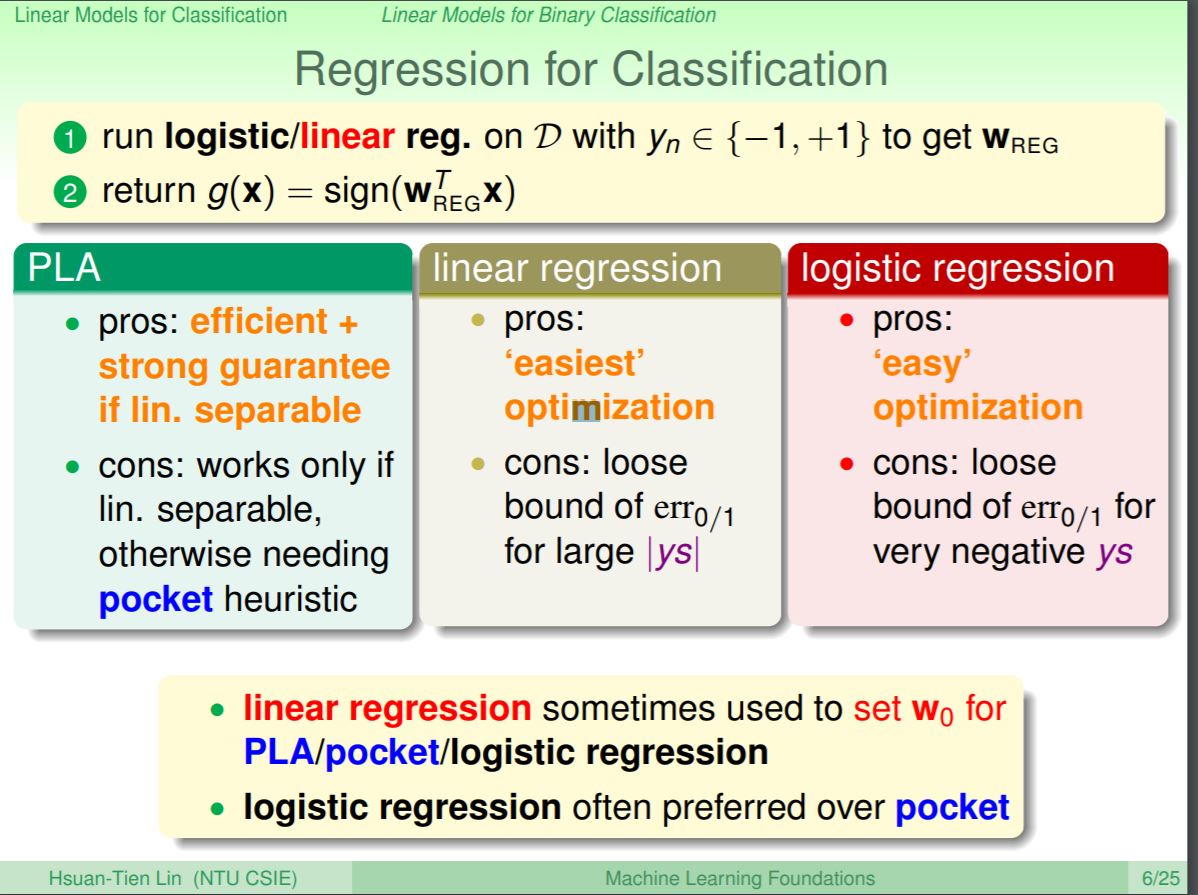
在logistic/linear regression分類問題上,linear regression的好處是他最容易作到最佳化,但是其error衡量比較寬鬆;logistic regression因為他也是convex所以最佳化也是容易的,而error衡量在ys負向很小時會很寬鬆,但也比linear regression還好;PLA則是如果在線性可分的問題上可以作到很好,不過缺點就是如果在非性線可分的問題上,雖然可以使用pocket演算法,但是效果就沒那麼好。
以前有有學過,雖然linear regression太過寬鬆,但是卻可以很快的先拿在找到一個初始的權重值,後續再交給PLA或是logistic regression作後續的最佳化。在實務上大部份的人會較常使用logistic regression來作二元分類,因為可以兼顧效果還有最佳化的容易程度。

雖然PLA和logistic regression都是iterative optimization方法,但是PLA是每看一點就作調整,而logistic regression卻要看完所有的資料點才會一次調整權重,他的速度和pocket一樣,每作一輪都要花比較長的時間,到底能不能讓logistic regression和PLA一樣快呢?

那不就學PLA每看一個點就調整一次權重就好了啊,這種每看一點作偏微分求梯度來調整權重的方法就稱為Stochastic Gradient Desent(SGD),即用隨機的梯度作梯度下降來接近真實梯度的期望值。好處就是每次算一個點比較簡單而且容易計算,由其是在大量資料的情況下原本的批次梯度下降法速度會很慢,但是壞就就是一次看一個點所以每次調整的結果可能很不穩定,但是最終應該都會很接近要求的目標值。這種隨機梯度下降也適合online learning,即每次接到一筆新資料後即作學習調整權重。其實還有另外折衷的方法稱為mini-batch gradient desent,當我們沒辦法看完所有資料再調整權重時,那就一次看N筆資料作調整就好囉!

那PLA和logistic regression到底相差在哪裡呢?PLA是一次調整到位,而logistic是看差多少就調多少,所以SGD的logistic可以說他像soft的PLA,而PLA又很像η設成1的logistic。在執行logistic時有兩個可以調整討論的地方,第一個是停止條件,通常我們會執行夠多的次數,因為我們相信執行夠多次就會逐步接近目標執;另外是η的設定上,老師個人習慣會使用0.1126,也許之後需要調整學習速度時可以參考一下。
再來談到多類別分類的問題,實務上常會有很多多類別的問題,像是要辨識圖像上不同的東西就是多類別的問題,再來會介紹該怎麼使用二元分類來達成多類別分類。

當我們想分類其中一種類別時,可以把其他三種當成同一種類別,這樣就可以建立四種二元分類器,把多類別問題轉成二元分類問題。但是這樣的方法會有某些地方有分類重疊的問題,像是四個角落都有兩種分類器範圍重疊,甚至也會有某些地方所有分類器都分不出來,像是中間區塊所有分類器都會認為不是自己要分類出來的區域。那該怎麼辦呢?

我們可以應用logistic regression來達成softly classfication,用顏色深淺來代表機率的大小,顏色越藍分到O機率越大,反之顏色越紅分到X的機率大。

再來組合出四個分類器,就可以知道在給定一組資料X,他究竟有分到不同類別的的機率有多少,所以可以透過選出機率最大的類別來判斷要分成哪個類別。

當我們有K種類別要作分類時,透過logistic regression建立K個分類器,接著選出機率最高的類別,這種方法來作多類別分類稱為One-Versus-All(OVA)。好處是方法很有效率,而且只要和logistic regression能算出機率值的方法,都可以應用OVA作多類別分類,壞處是如果成兩元分類的資料不平衡的話,可能造成每個分類器都叫你猜大宗類別,造成最終分類效果不好。

前面有講到OVA會遇到Unbalance問題,可能造成分類表現不好,那該怎麼解決這個問題呢?
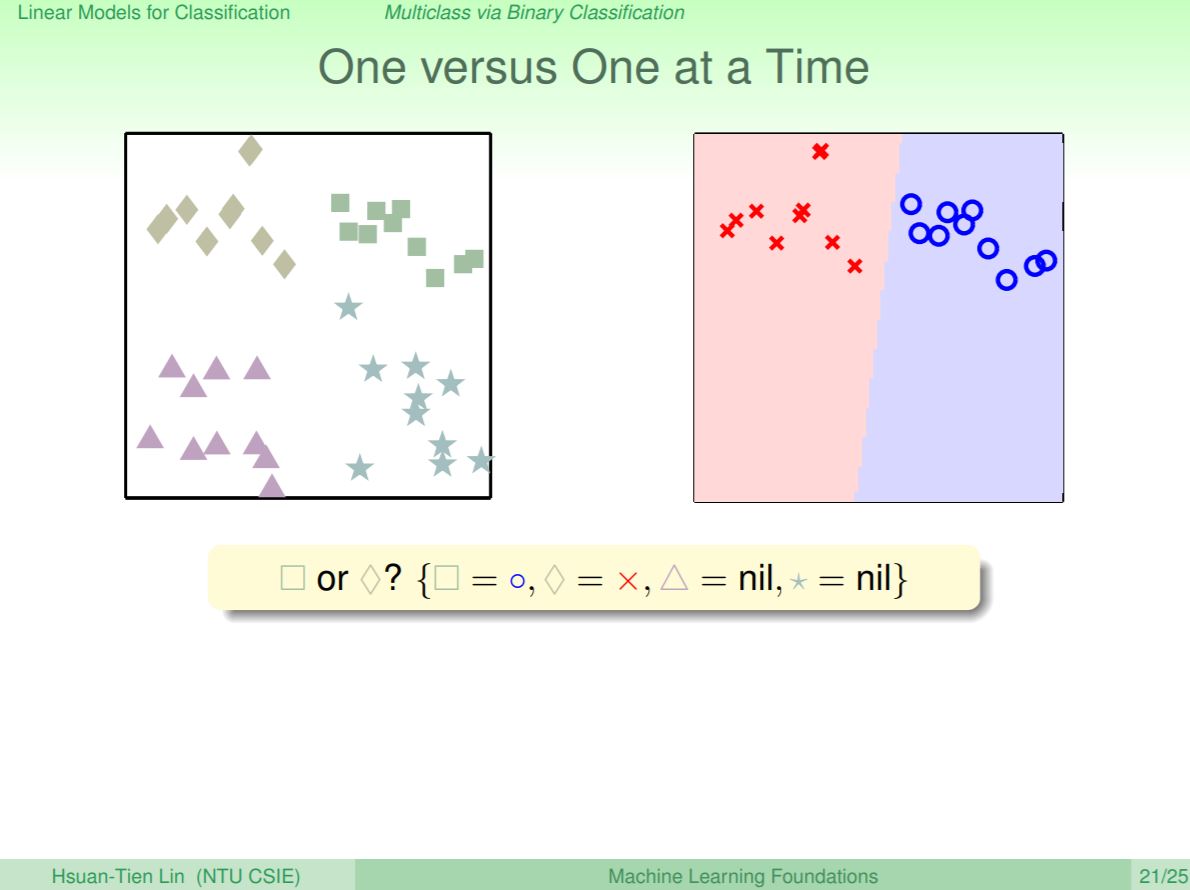
前面是一對其他所有類別作兩元分類,我們其實可以直接使用其中兩種類別的資料作二元分類就好了,如果兩種類別的資料接近的話,那麼資料量就會比較平均避免Unbalance問題。

那有這麼多的分類器,到底該如何判斷是哪個類別呢?以方塊類別為例,其中可以發現共6個分類器,其中前三個都說分出來的結果是方塊,後面三個則分類分到一個菱形和兩個星型,透過投票可以知道最可能的類別應該會是方塊,因為分出方塊佔大多數。

這樣的方法稱為One-versus-one(OVO),因為他是一對一類別的分類,而非一對其他所有類別的分類方法,透過一對一類別的分類別,再找出最有可能的的類別。這個方法的優點是在訓練資料時很有效果,因為只使用比較少的資料量來作訓練,而且可以應用在所有的二元分類問題;壞處則是要訓練更多的分類器,所以在預測的時間、訓練的次數還有儲存的空間都會花比較多。

這一講首先學到了前面講的三種線種模型方法其實都是可以用來作二元分類的,而且針對logistic regression可以使用SGD來作隨機梯度下降找最佳解,這樣的方法很像最早學到的PLA。再來針對多類別的問題教了兩種方法,都是應用二元分類來達成多類別分類,第一種OVA是把所有資料分成兩個類別,一個是要分出來的類別,另一個是把其他資料視為同一類別;第二種OAO是單純就看兩種不同類別來作兩兩比較,而這兩種多類別方法都是簡單而且常被拿來使用的分類手法!