上次介紹了linear regression,這一堂課會說到logistic regression,主要會將linear regression使用sigmoid轉換來算出不同類別的機率。
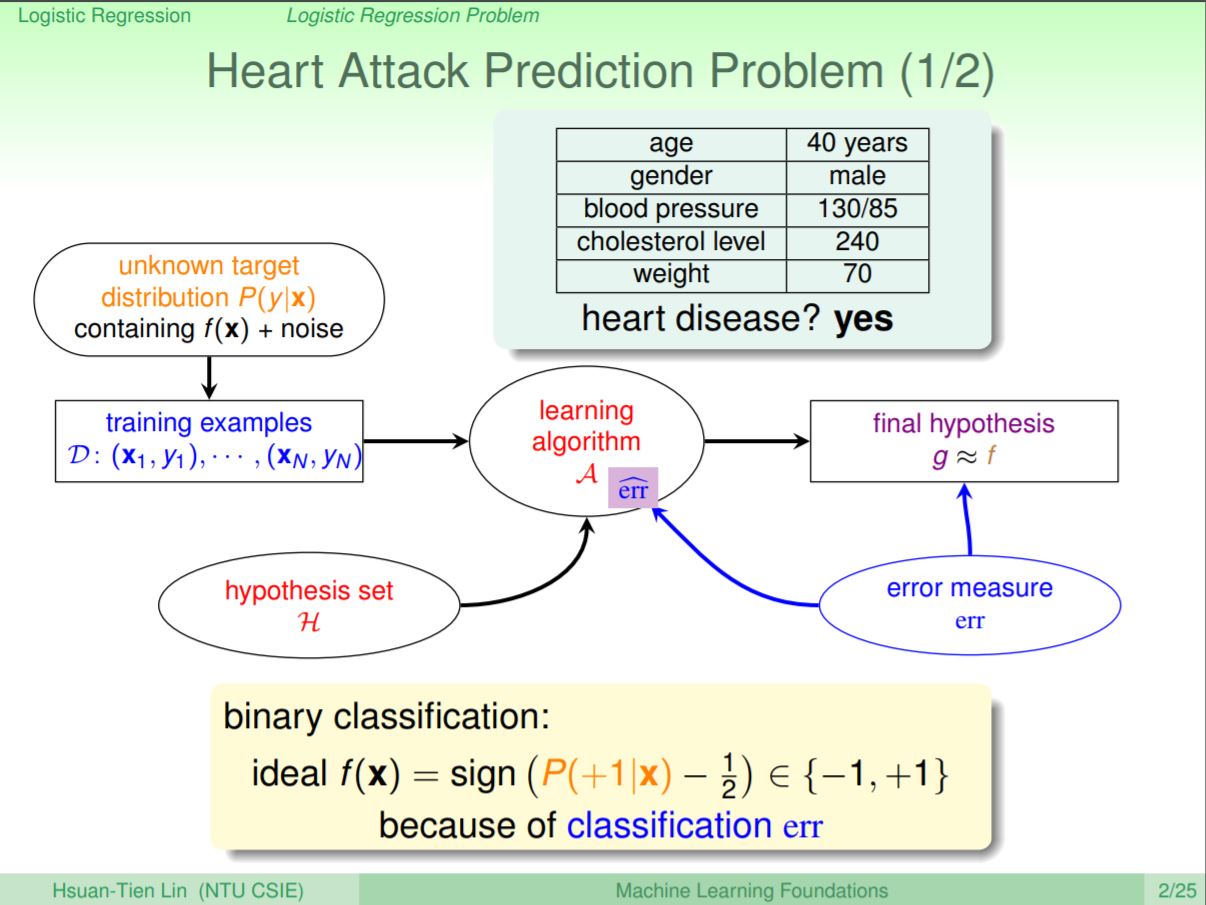
之前有學過在二元分類中會判斷病人「有」或是「沒有」心臟疾病,並可以使用0/1的分類錯誤來判斷分類的結果好壞

但如果今天並非想要知道病人「有」或是「沒有」心臟疾病,而是想知道未來一段時間後,心臟疾病發生的機率是多少。和二元分類有點不同,我們想要知道的是發生某個狀況的機率,這會是一個介於0到1的數值。當然後續可以對這個數值定義出一個臨界值來達成二元分類,所以又可以稱為soft binary classification。

如果我們可以知道在給定一組x,他的結果y是一個機率值的話那就可以很容易的找到這樣的結果,但是實務上我們只會拿到有抽樣誤差雜訊的結果,只能知道0/1的結果(即有沒有心臟病發)。再來會學到的是,如果只能知道0/1的情況下,要如何求出想要的機率值。

要如何找到這個機率值呢?一樣可以像之前的線性問題,將每個特徵乘上特徵權重,就會找到分數,但是這次想要的不是這個分數,而且要把分數轉換為0到1的機率值,分數越大機率越大,反之分數越小機率就越對,這裡會透過logistic function會把這個分數值轉換成0到1的機率值。
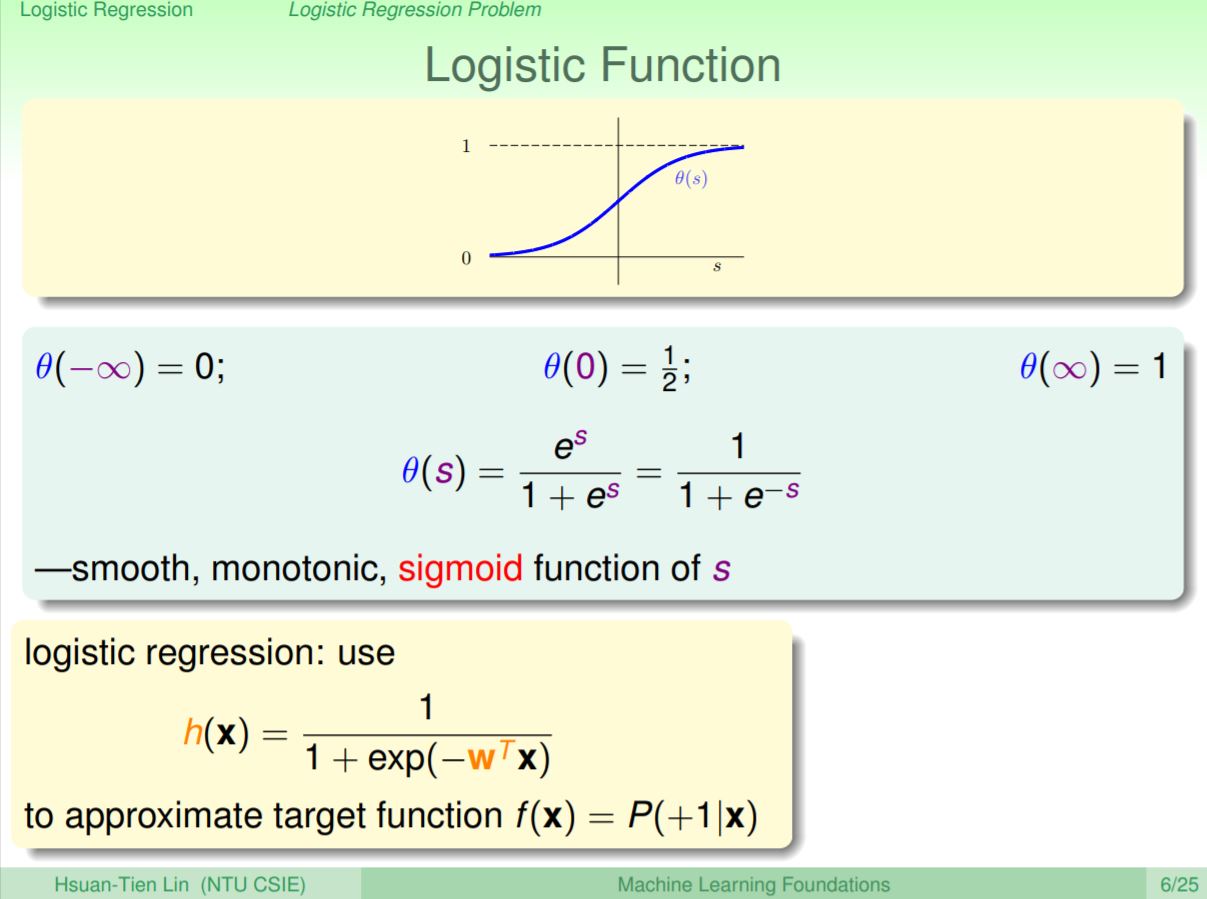
一般會使用sigmoid來把分數轉換成0到1的機率值,當分數越大會越接近1,分數越小會越接近0。再來就可以使用這個logistic hypothesis來達到我們的目標函式f(x)
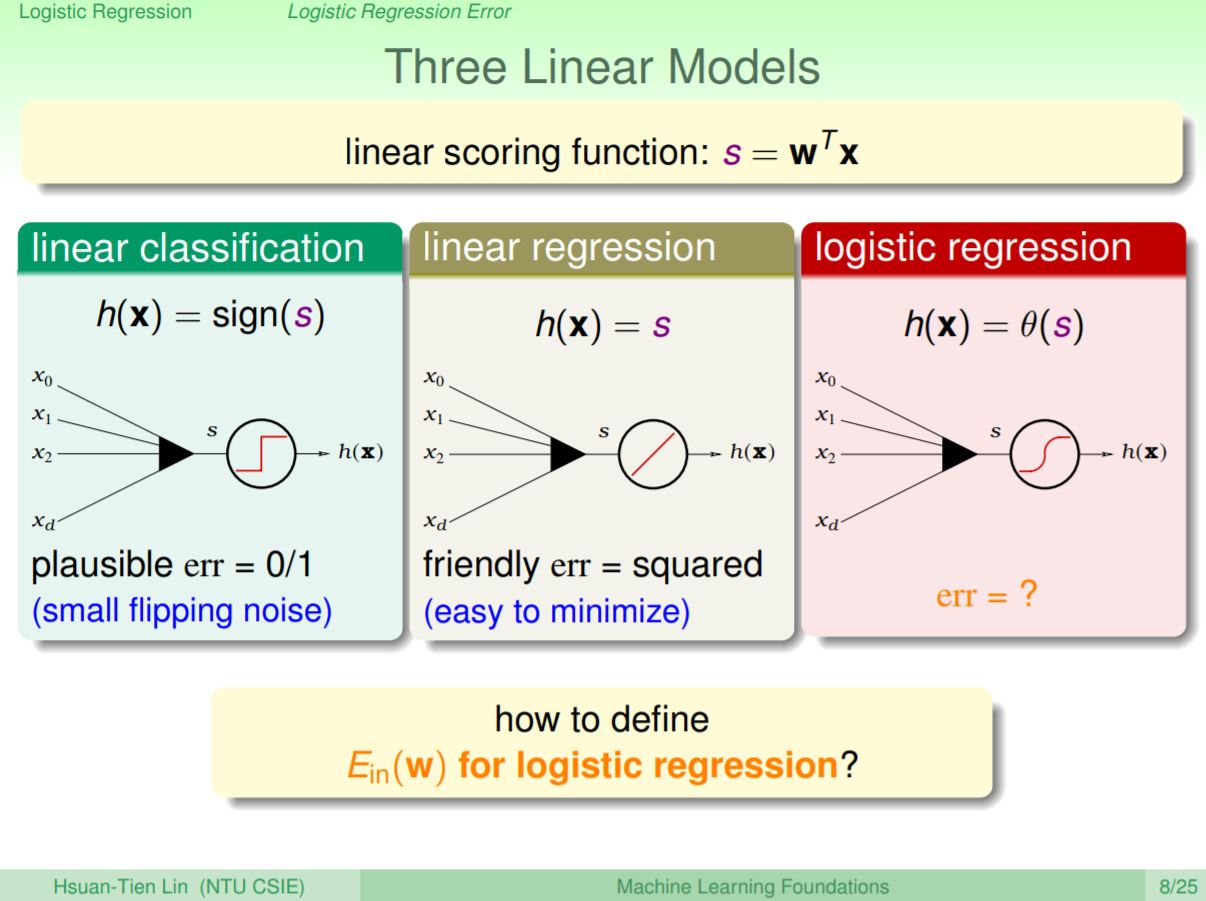
究竟logistic和之前學到的有什麼差別呢?
在linear classification算完分數會以0為臨界點來區分0/1類別,並使用0/1 err來判斷結果,在linear regression則會直接輸出分數,再使用squared err來評估結果;logistic regression會將算完的分數透過logistic function轉換,但該用什麼err來衡量呢?

首先可以先算出f(x)是怎麼產生一組資料D的,再來因為要使用hypothesis H來逼近f(x),所以可以把f取代成h,因為最好的狀況下,我們學習到的h和原本的f是會非常接近。而且如果資料D是由f產生的,那麼f算出來的機率值應該是很大的,所以若是可以在多個h裡面找到一個最大機率的h,就能找到一個最適合的hypothesis

在計算likeliood時,重點會放在hypothesis上,因為hypothesis決定了最後的機率,再來因為logistic function具有對稱性,所以最後可以整理成h(YnXn)的連乘

因為這個hypothesis是線性的,在線性裡面我們關注的是其中的權重w,所以再重新整理將h取代成w,把y取代成線性組合yn*w

之前最常處理的就是連加的問題,所以我們取log將連乘取代成連加,再來為了轉成求Ein,所以加上負號來取最小值。最後再將logistic function代進去,就可以得到最後要求的Ein,這裡的Ein又可以稱為cross-entropy error。

在推導出Ein後,再來就要找到一個權重w可以讓Ein最小,因為Ein最小就可以知道Eout也很小。前面的linear regression因為是convex所以可以透過梯度找到最小低,而logistic regression這個函式也是convex,所以也可以透過梯度來找到梯度為0的地方算出最好的權重w。

我們可以使用微分和鏈鎖率來找到梯度,如果今天要讓梯度等於0可以有一個假設,就是假設θ出來的值是0,但要讓θ出來的值是負無限大,就要讓y乘上w乘上x這一項是正的。其中w^T.x這個分數在以前可以被拿來作兩元分類,而乘上y如果大於0的話,代表是同號,即所有資料都可以分對,意義就是線性可分。之前在linear regression可以直接算出一個close-form的答案,但是現在logistic regression並非線性的,困難在於沒辦法直接算出close-form的解,那該怎麼辦呢?

這個時候就可以應用到之前的PLA方法,PLA在每次拜訪到的點如果分錯的話,就會逐步作調整來更新權重。

在整理後可以歸納出兩個部分,如果需要更新權重的話,第一個η是指走多大一步,之前在PLA可以視為1,後面第二部份則是算出要走的方向。像這種逐步循序的調整學習又稱為iterative optimization approach逐步最佳化方法。
那麼再來要如何找到logistic regression的最好權重值w呢?其實就是隨便找一個方向v,然後慢慢透過往下走到谷底就可以了,其中要走的步伐η會決定往下走的速度。

但是要怎麼找這個方向v呢?因為這個問題還是非線性,但是如果我們每次都看一小小段,就是一次只看一個線性問題,就可以比較容易而且轉成接近線性問題。其實這就是常使用的梯度下降法(Gradient Descent),即每一次走梯度逐步找到最佳,或是近似最佳解。
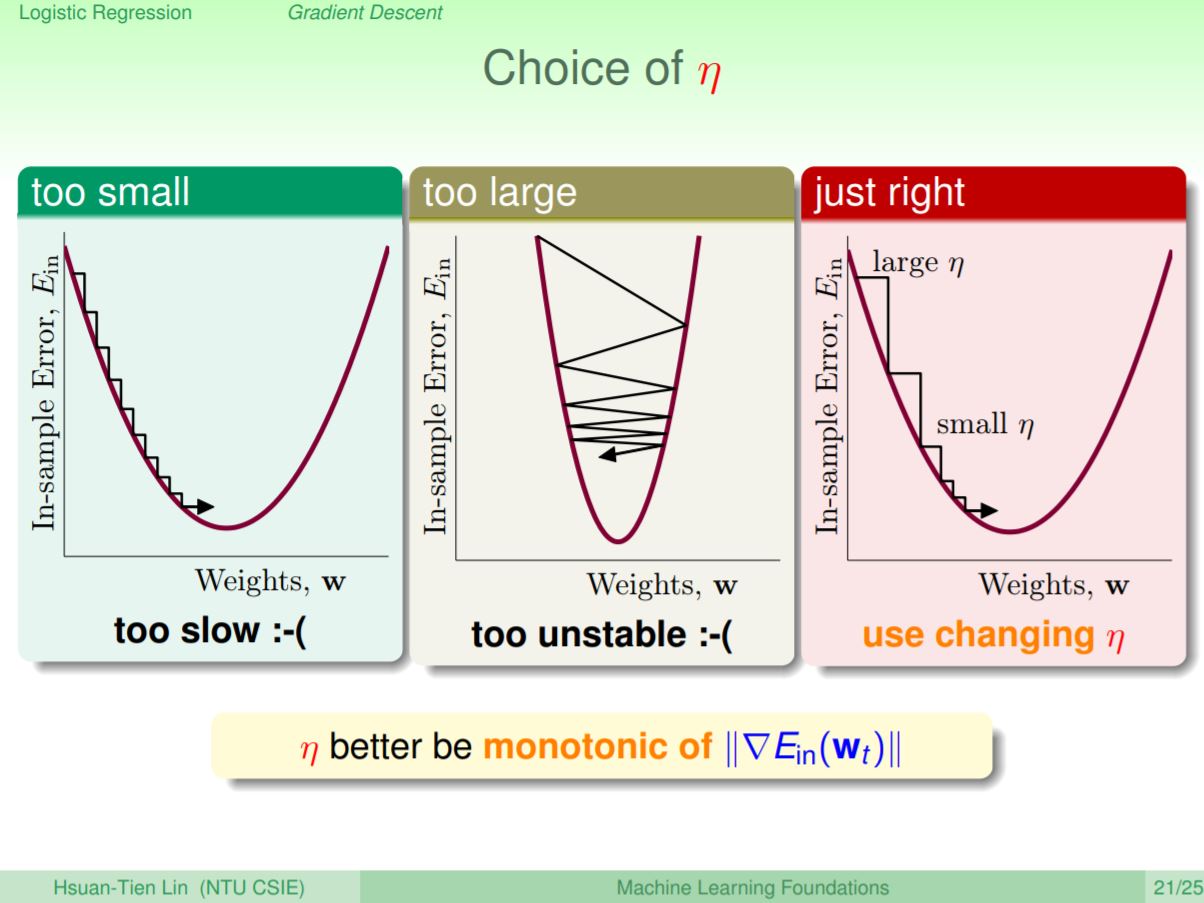
那麼η該怎麼決定呢?如果η太小的話,雖然遲早可以找到最佳值,但是速度會很慢;如果η太大的話,反而可以會跳過最小值,搞不好會跳來跳去找不到最佳值。有一個最好的方法,就是隨著坡度的大小來決定η要走的大小。

因為η會改變,所以可以採用一個不一樣的η來代表這個會變動的η,即他每一次的學習都是會變化的η乘上梯度,這就稱為fixed learning rate gradient descent。

最後我們可以逐步的作梯度下降,一直到找到最好的谷點,但是實際上可以找到接近谷底的值就可以了,所以最常用的就是設定一個iteration的次數,到達就停止。這個方法其實就很像之前學到的pocket方法,pocket方法是每次抓一個最好的值,得到更好的值就會更新。
因為之前有上過Andrew的Machine Learning課程,其實Andrew在教linear regression找最佳權重w時,就是直接教fixed learning rate的梯度下降法,我覺得在學習線性時用梯度下降還滿好理解的,對於後面到logistic regression很有幫助,建議沒有上過Andrew的Machine Learning課程可以考慮上看看!
參考資料:
Machine Learning Foundation 10
Andrew Ng - Machine Learning