
先來複習一下前面課程,從前面的課程可以得知,在有限的VC維度下,且有大的樣本N並且Ein是夠小的,滿足三個條件我們就可以讓機器可以學習。
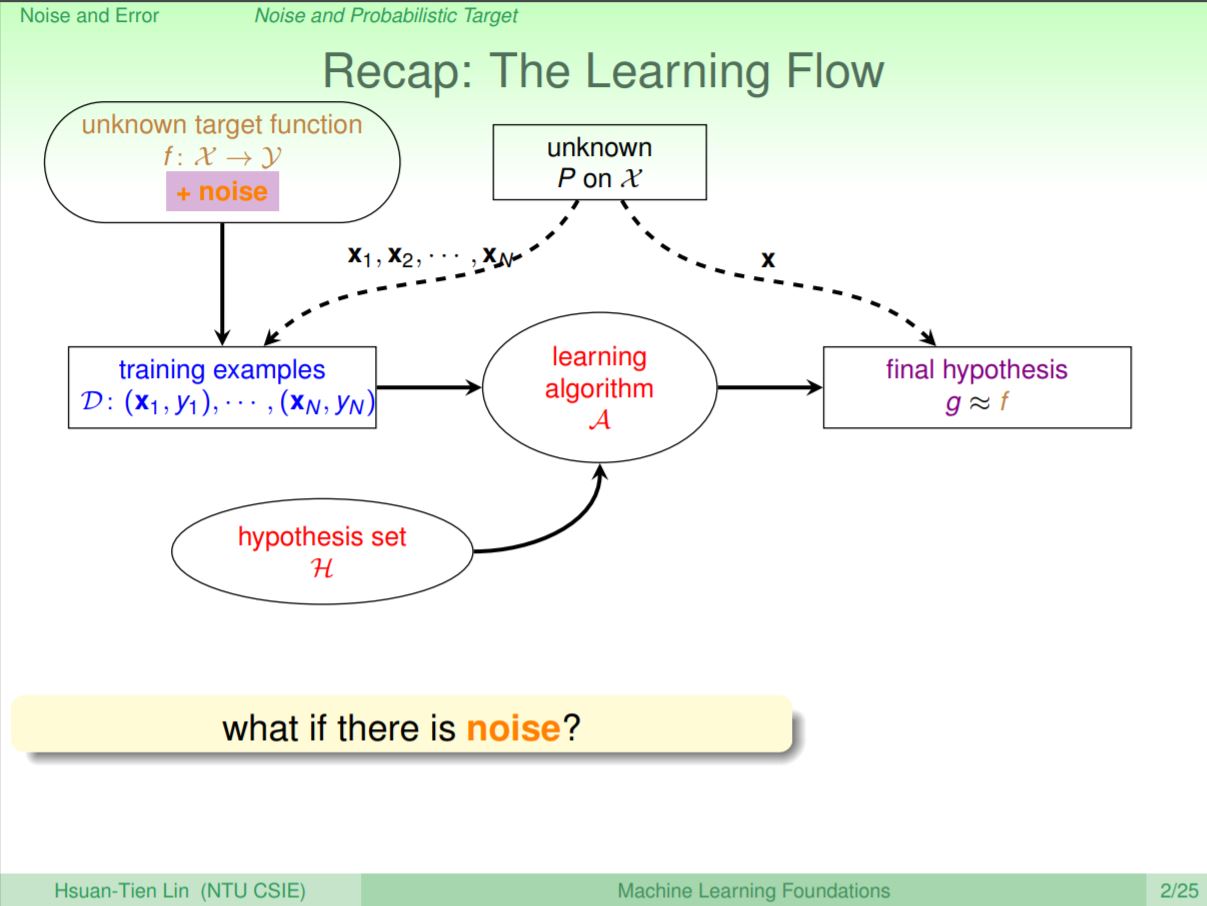
那如果今天在整個學習流程中,未知的目標函式在產生x時有雜訊發生,會發生什麼事呢?這堂課主要就是在說明,如果資料有雜訊,到底會不會對學習造成影響。
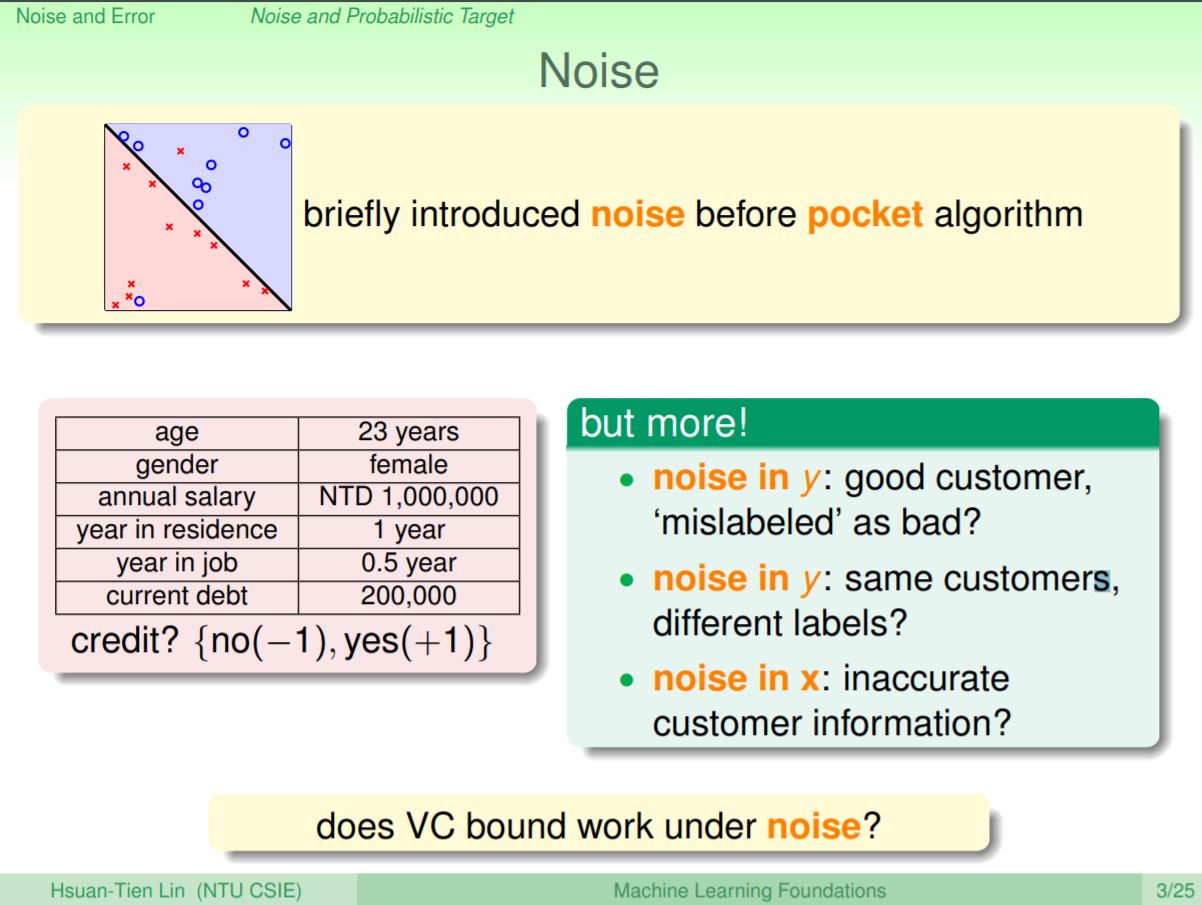
事實上雜訊是有可能發生的,比如說在審核信用卡的例子,可能在y產生雜訊,即發不發信用卡被錯誤標記;也可能在x產生雜訊,這就發生在蒐集資料時產生的錯誤。那麼究竟有雜訊會不會對VC維產生影響呢?
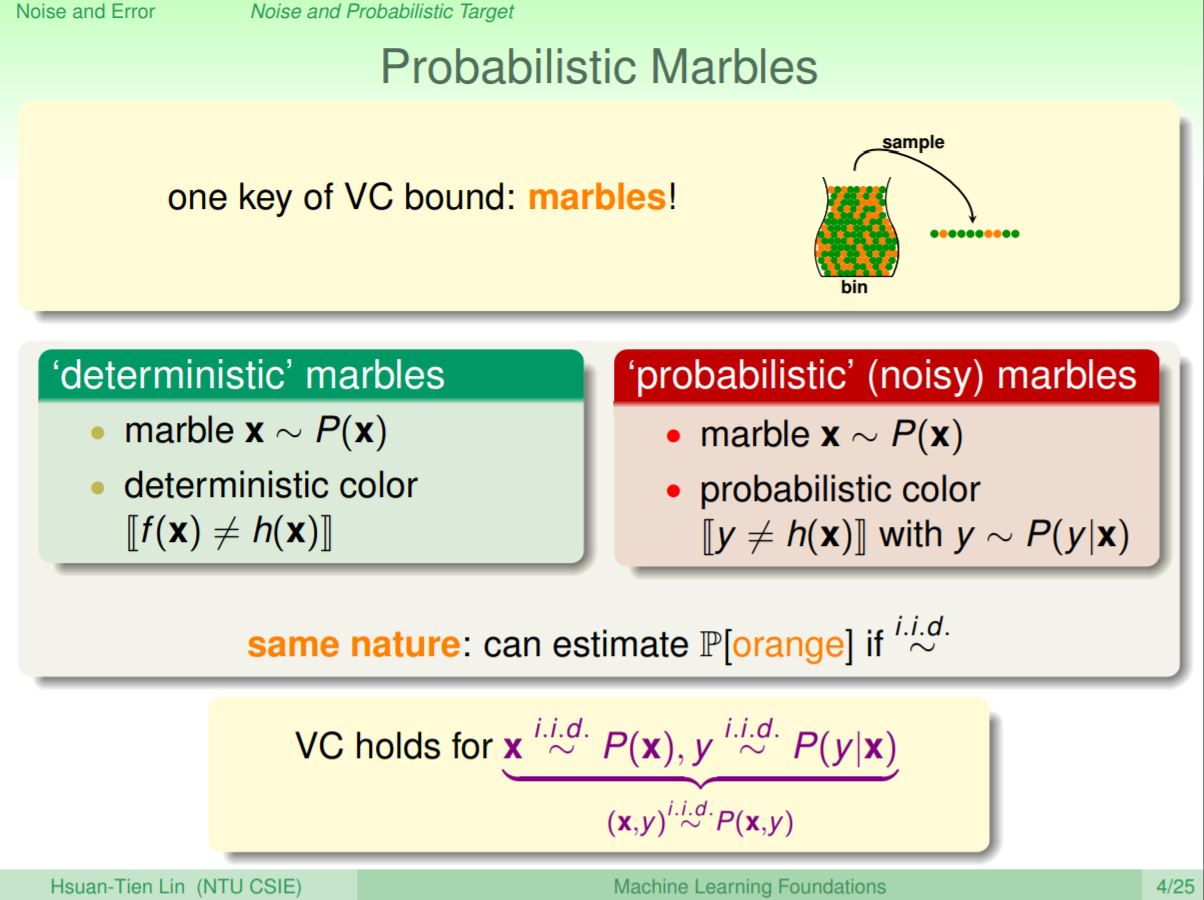
我們一樣從前面的抽彈珠例子來看,本來如果f(x)和h(x)相等時是綠色,不相等是橘色,今天如果有雜訊發生,代表y和f(x)會不相等(明明要核卡但沒有)。雜訊就可以假設成一種會變顏色的彈珠,有時是綠色有時是橘色,雖然會有這種雜訊的彈珠出現,但是因為雜訊變色彈珠是少數,我們仍然可以透過抽樣的方式來計算橘色和綠色彈珠的比率,所以VC維還是會work的。

這邊會帶出目標分配P(y|x),以二元分類o和x的例子來看,如果我們已知P(o|x)是70%,P(x|x)是30%,在這個情況下我們會選擇o,但是剩下的30%可以看成雜訊。即最好的預測是o,而雜訊發生的機率是30%。所以在這裡機器學習要作到的,就是在點x找到最理想的mini-target。
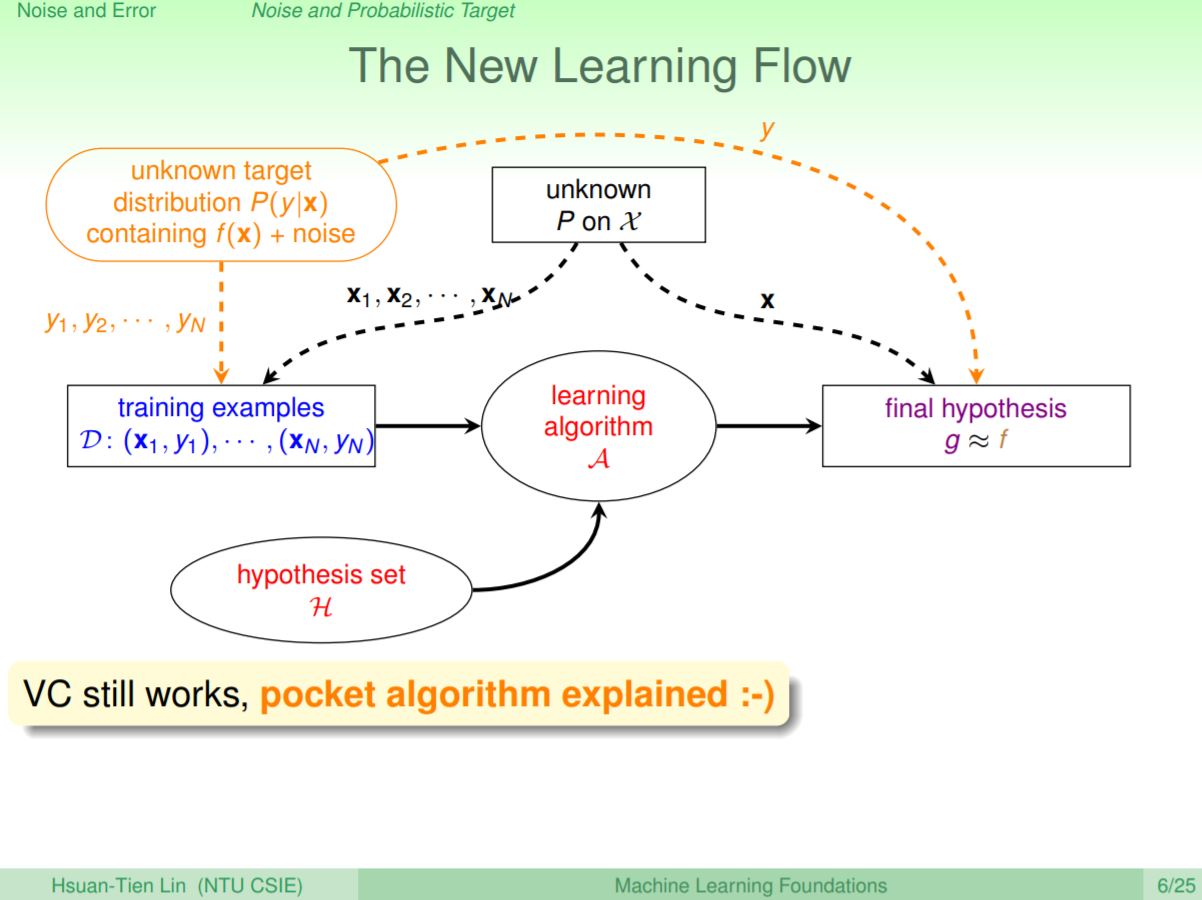
最後再把雜訊加進去後,可以把目標函式f(x)改變成mini-target P(y|x)加上雜訊,而這個y會用來在最後評估g和f是否接近。

之前談到的錯誤衡量方式為分類錯誤(又稱為0/1錯誤),就是直覺的判斷g(x)和f(x)是否相等,不管是Ein或是Eout都可以對每一個點各自作判斷(稱為pointwise)是否發生錯誤。

這種0/1錯誤衡量會用在分類問題上,除了分類錯誤外,另外常用的錯誤衡量方式為Squred Err,判斷每一個y到理想的y的距離,這種則常用在數值型的機器學習問題,像是迴歸分析。在不同的機器學習問題,會使用最適合的錯誤衡量方法。
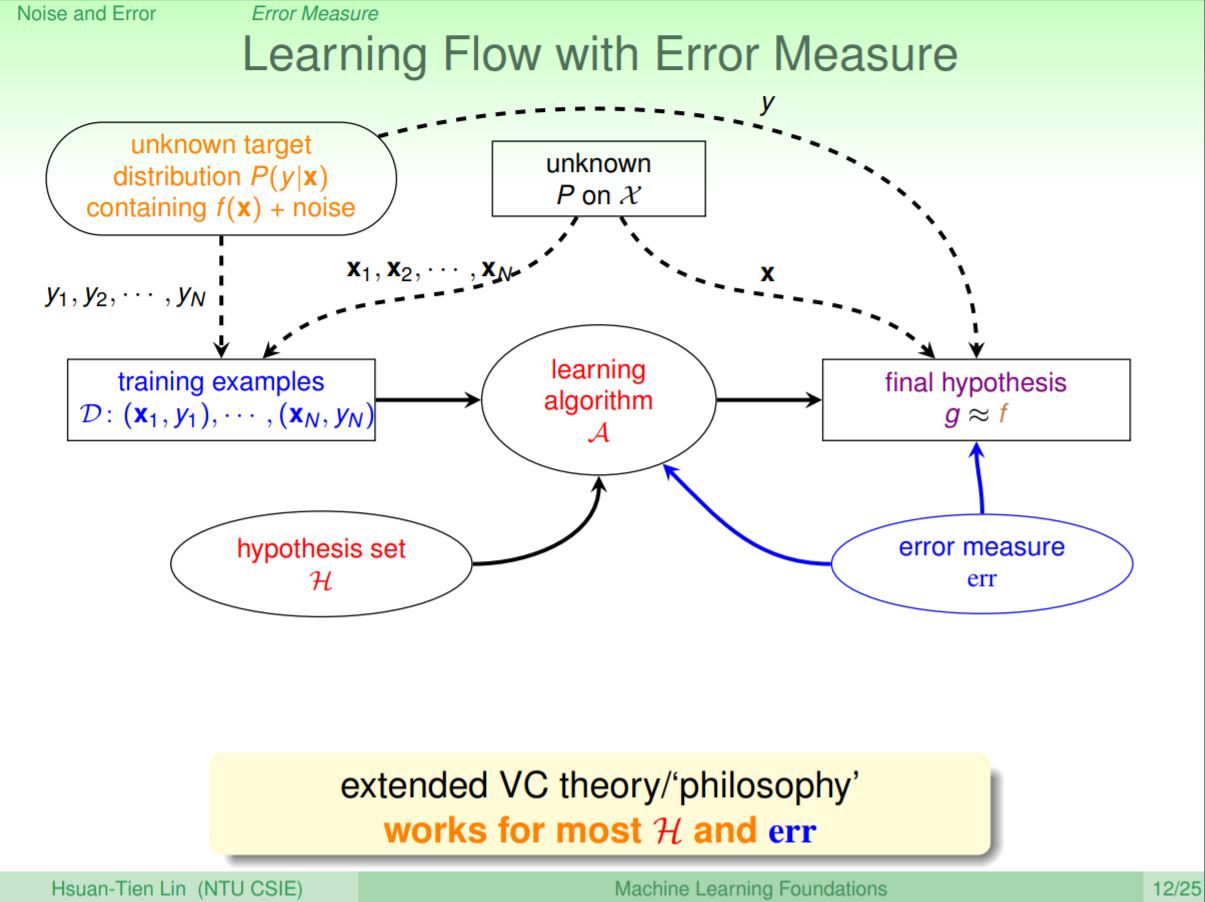
當我們把錯誤衡量加上去,這個選擇的錯誤衡量會用來評估g(x)和f(x)是否相等。
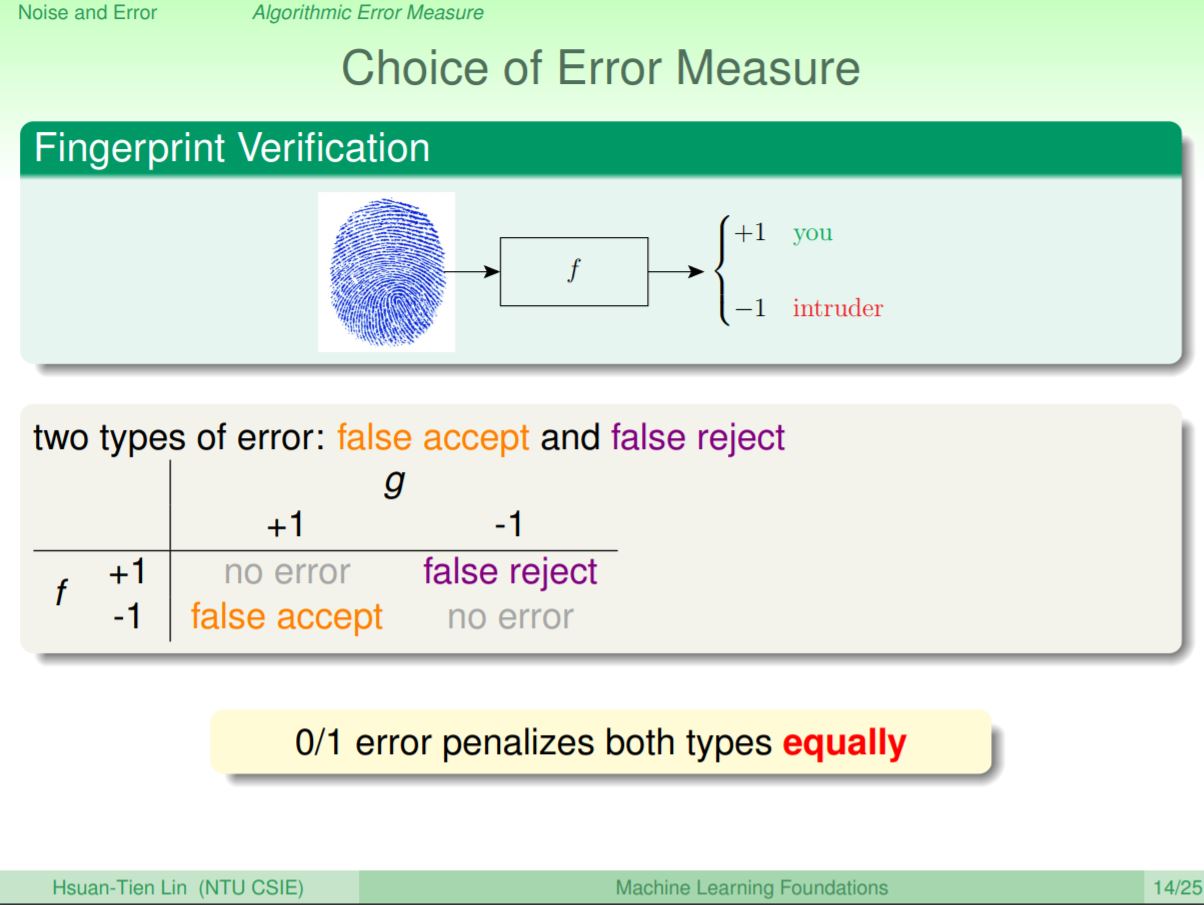
在0/1分類時,可能會有兩種分錯的情況,以指紋判斷正不正確來說明,一種為false reject,就是指原本是正確的,但是被判成錯誤;另一種為false accept,是指原本是錯誤的,但是被判成正確。看起來都是錯誤,但是這兩種錯誤會在不同的應用上有不同的重要性。

以超市的應用為例,如果超市透過指紋來判斷是不是要給折扣,今天判斷錯誤造成該給折扣卻沒給(false reject)讓顧客不開心,損失了這個客戶可能造成超市的損失;相比之下,如果是不該給折扣卻給了(false accept),頂多只是超市有一點損失而已沒什麼大不了。所以以超市來看,false reject的成本會比false accept高。
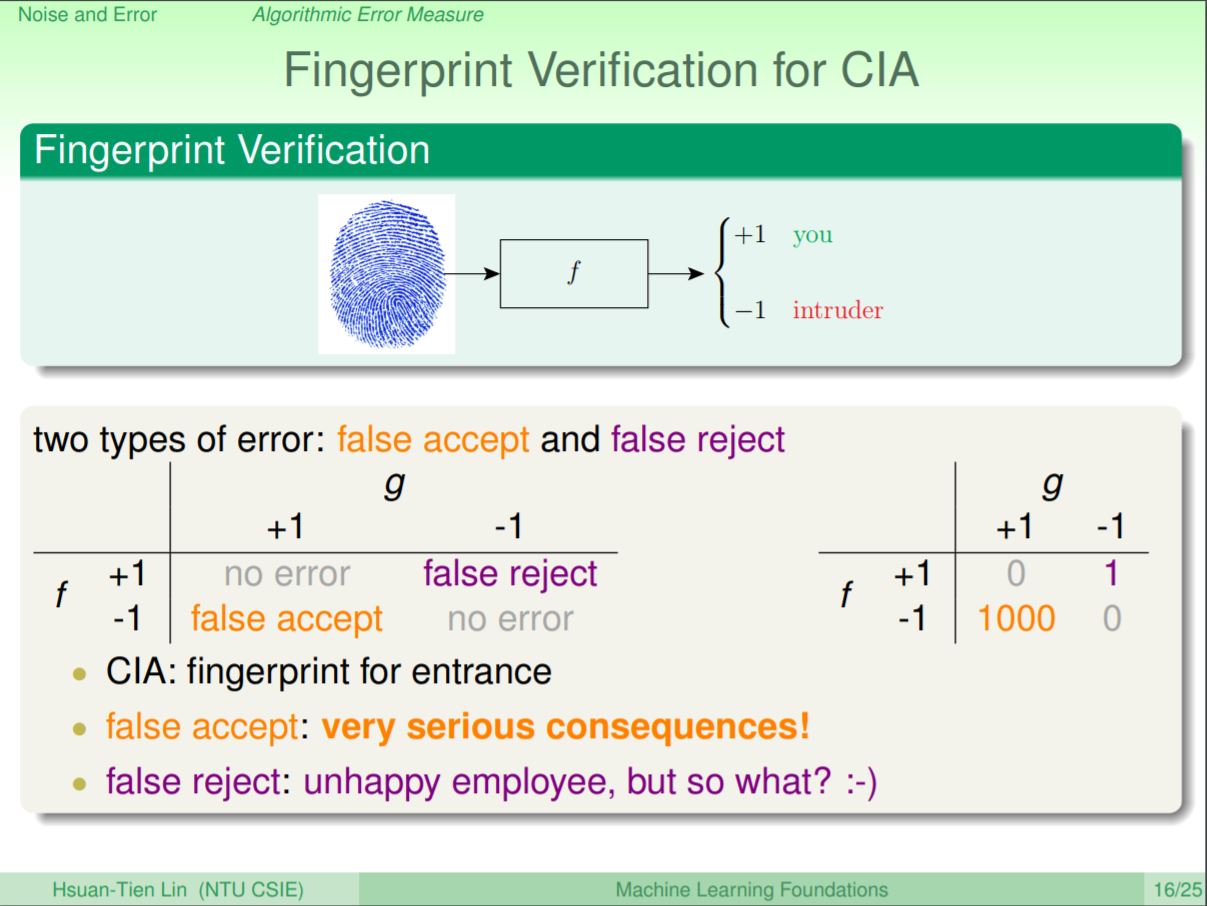
以CIA應用為例,今天如果有人沒有權限但是卻被判斷有權限可以看資料(false accept),這將是個很嚴重的錯誤;那如果是有權限但是被判斷成沒有權限(false reject),其實只的造成員工的不開心而已。和超市相比,他的false accept成本可能就會遠遠大於false reject。
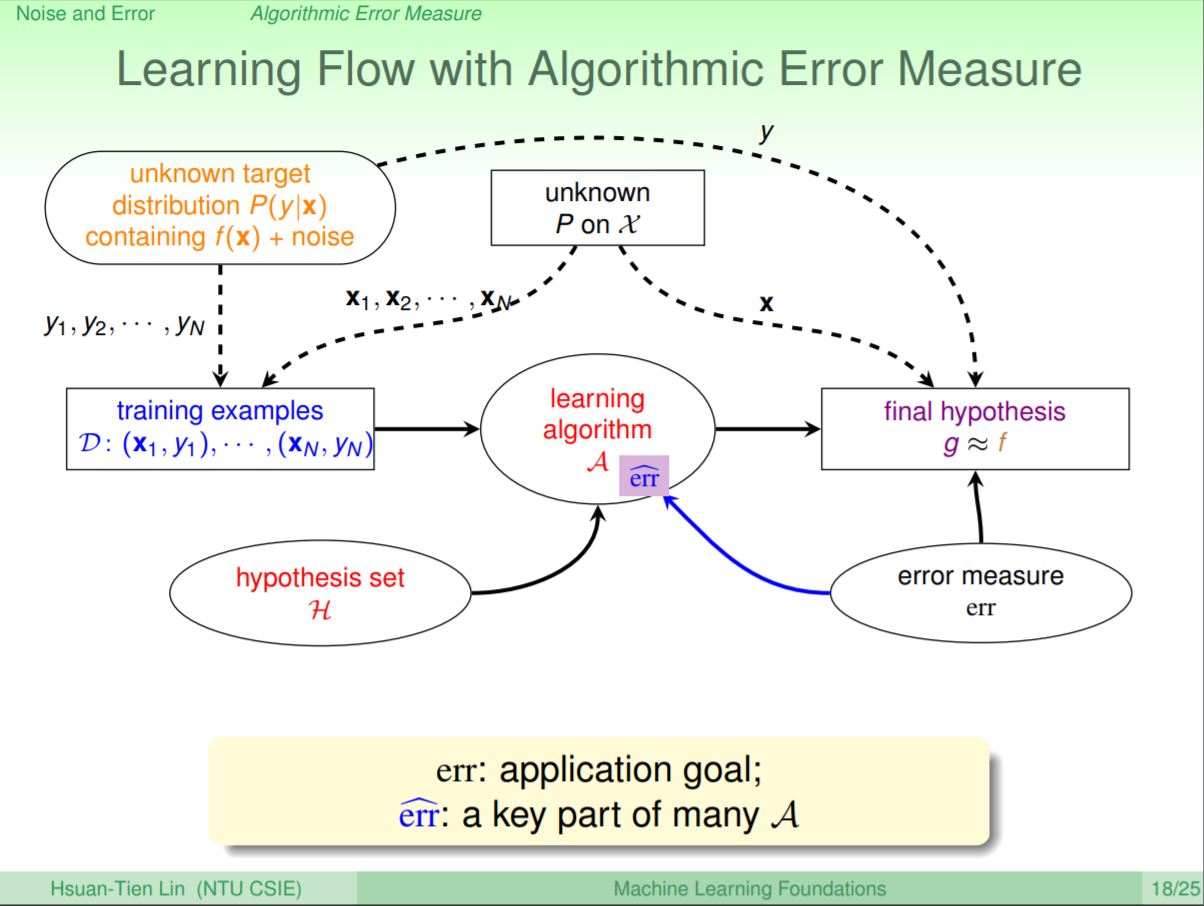
那麼到底該怎麼樣去衡量雜訊造成的實際應用錯誤呢?我們會透過設計友善的演算法來找到還可以接受的錯誤衡量方法。所以相比於實際的錯誤err,在設計演算法會透過計算一個另一個err hat,來試圖讓錯誤衡量可以更多的方便。

前面講到的又稱為有權重的分類問題(weight classification),不同的例子會有不同的重要性。因為已經證明在有雜訊的情況下VC維仍然是可行的,所以我們只要確保Ein是最小的,就可以保證Eout是最小的。我們總共學過兩個讓Ein最小化的方法,第一個是PLA,PLA就會等所有的資料都分對就結束,即Ein為0;如果PLA跑不完的話,可以用另外的Pocket演算法,Pocket演算法可以把加權錯誤比較好的放入pocket。
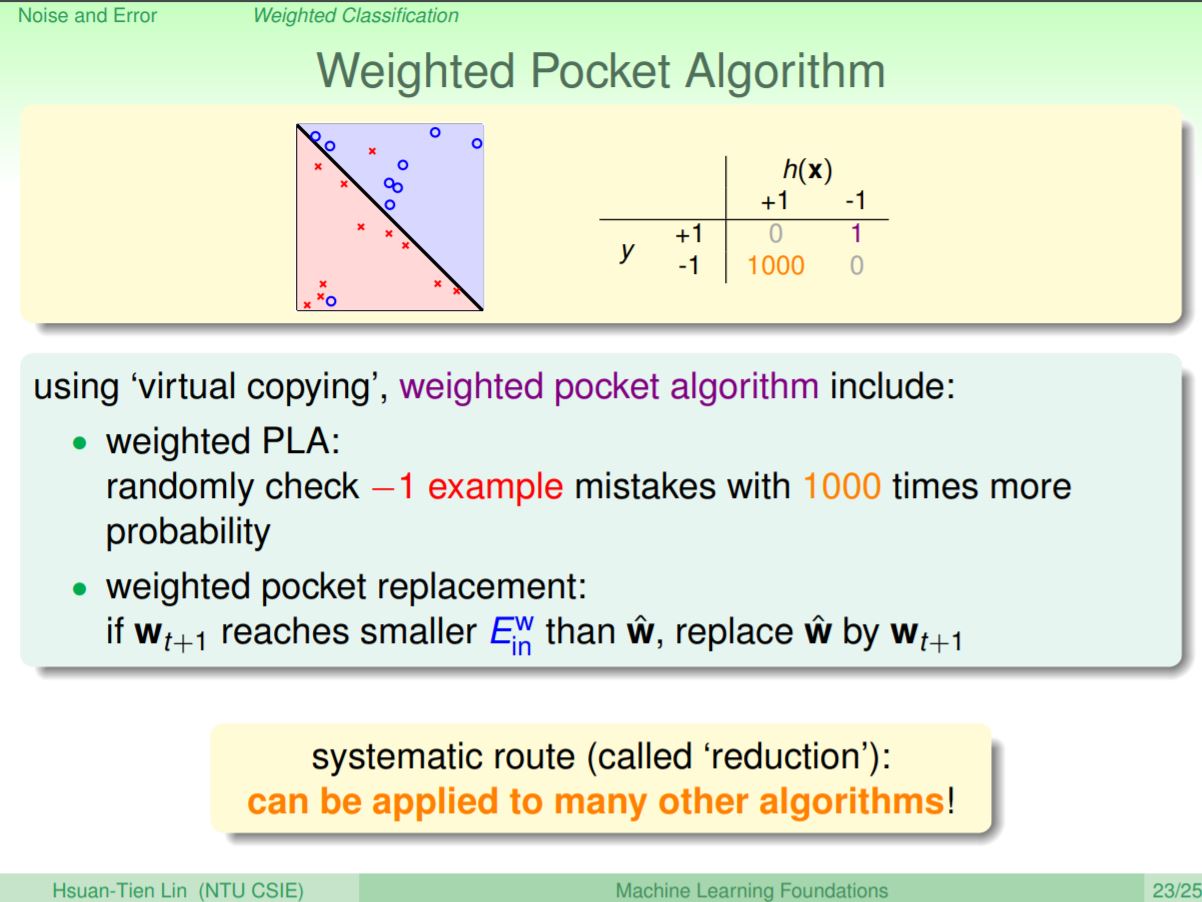
如果我們要把0/1分類問題加上權重,其實可以簡單的把-1的資料複製成1000次,就會很像他有帶權重1000。實際並不的真的複製,原本的pocket會輪流拜訪每一個點,當我們這種-1的點讓他有1000倍的機率更容易被拜訪到,其實就可以達到類似的效果。

總結來說,這堂課首先說明了有雜訊的情況下,會使用一個機率函式P(y|x)來取代f(x),再來會使用適合的錯誤衡量方法來作評估,但是錯誤衡量方法有時並不容易給,所以會透過比較友善的演算法設計來達成。最後說到兩種不同的錯誤會有不同的權重,且這個權重可以透過虛擬複製的方法達成。