在上一講中證明了如果存在break point,而且輸入點N夠大的情況下,Ein和Eout是會接近的。這一講會延續VC bound帶出VC Dimension。

前面有證明到,成長函式mH(N)會被上限函式B(N, k) bound住,然後上限函式又會被一個多項式N^k-1給bound住。所以我們可以直接使用N的k-1次方來表示成長函式。

再來把N的k-1次方取代原本的成長函式mH(N)並代回原本的Hoeffding不等式中,他告訴我們1. 只要成長函式存在break point,即表示是個好的hypothesis且2. 輸入的N夠大,即表示是個好的D的情況下,再來配合3. 一個好的演算法,那麼就可以保證機器可以有學習的效果。

VC dimension被定義為最大的非break point維度,所以當我們說在k點不能被shatter,那麼VC dimension就是k-1。

依據VC dimension的定義,在PLA是在4點不能shatter,所以VC dimension為3。以前我們說成長函式mH(N)是有限的就是好的,現在我們可以說如果VC dimension是有限也就是好的。

有了VC dimension再回來看2D的PLA該怎麼學習,PLA可以在線性可分的資料D中找到g讓Ein為0,而VC dimension為3且N夠大的情況下,能推論Ein和Eout會很接近,即Ein和Eout差距很大的機率會很小,又因為Ein為0,所以可以知道Eout也會很接近0,就代表機器真的可以學習了。
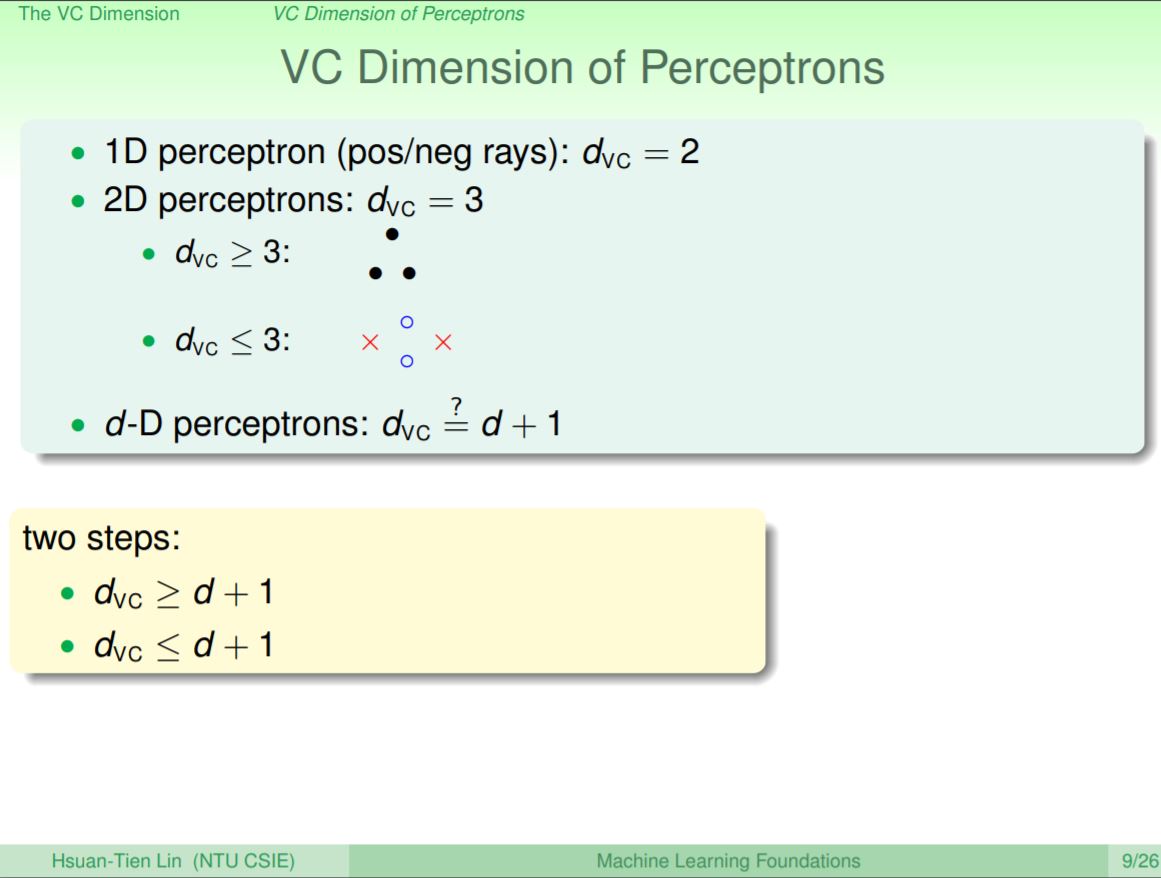
前面可以看到1維perceptron的VC dimension為2,2維的perceptron的VC dimension為3,這樣看起來似乎可以推論出d維度的VC dimension為d+1。當然這是正確的,因為後續可以證明出dVC >= d+1和dVC <= d+1
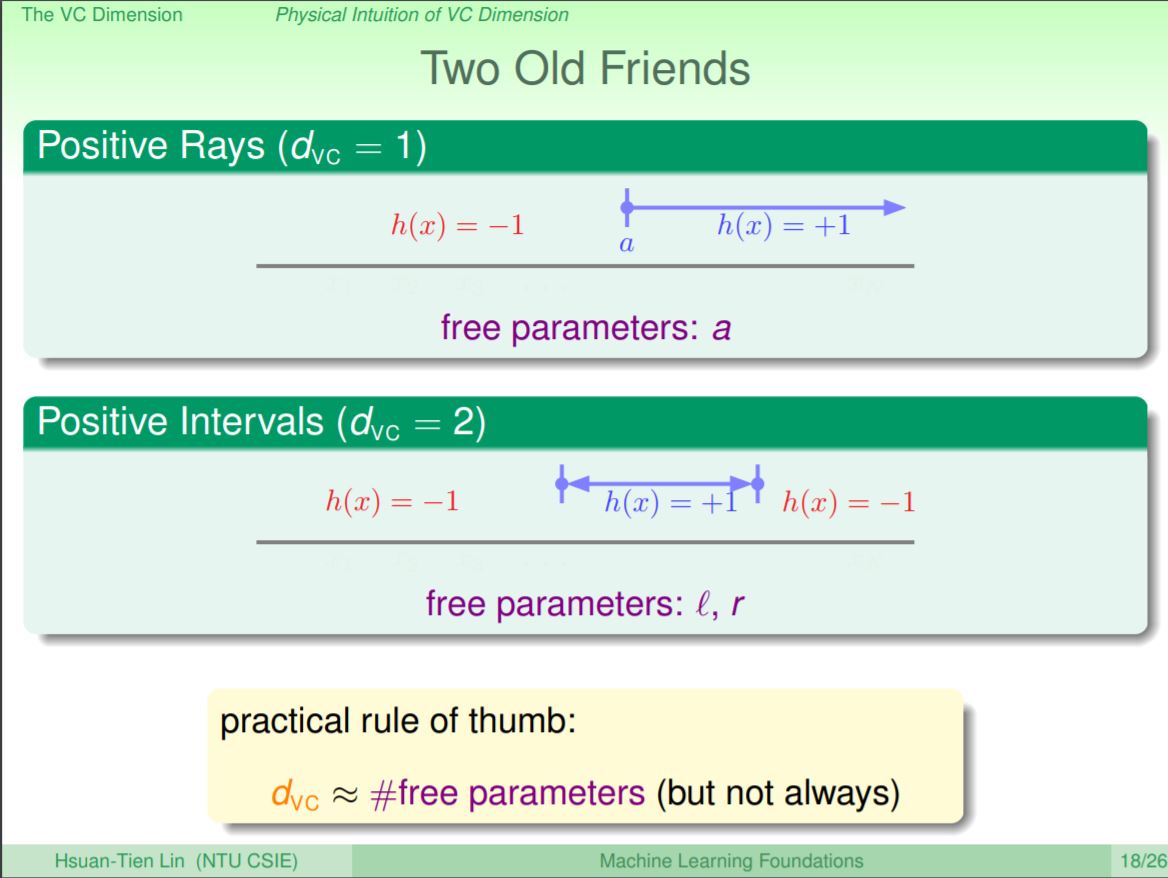
VC dimension的物理意義大致上可以說是hypothesis集合在要作二元分類的狀況下,到底有多少的自由度。前面提到的VC dimension的定義是說,VC dimension在k-1的時候可以產生最多的dichotomy,所以這個自由度也就告訴我們hypothesis集合到底可以產生多少的dicotomy組合。以positive ray的例子來看,其有1個可以調整的參數,positive interval的例子則有2個可以調整的參數

我們可以將VC bound的式子作一些調整轉換,其中把右邊壞事情發生的機率代換成δ,那麼好事情發生的機率就是1-δ,也就是Ein(g) - Eout(g) <= ε,再用右邊的部份可以導出ε。

好事情發生的機率,即Ein(g)和Eout(g)有多靠近,又可以稱為generalization eror,就是指舉一反三的效果好不好。衡量一個model的複雜度可以用Ω符號來表示,而VC dimension告訴我們的是,當model的複雜度越高的時候,就會產生penalty效應,有很高的機率Eout(g)會小於等於Ein(g)加上model的複雜度。
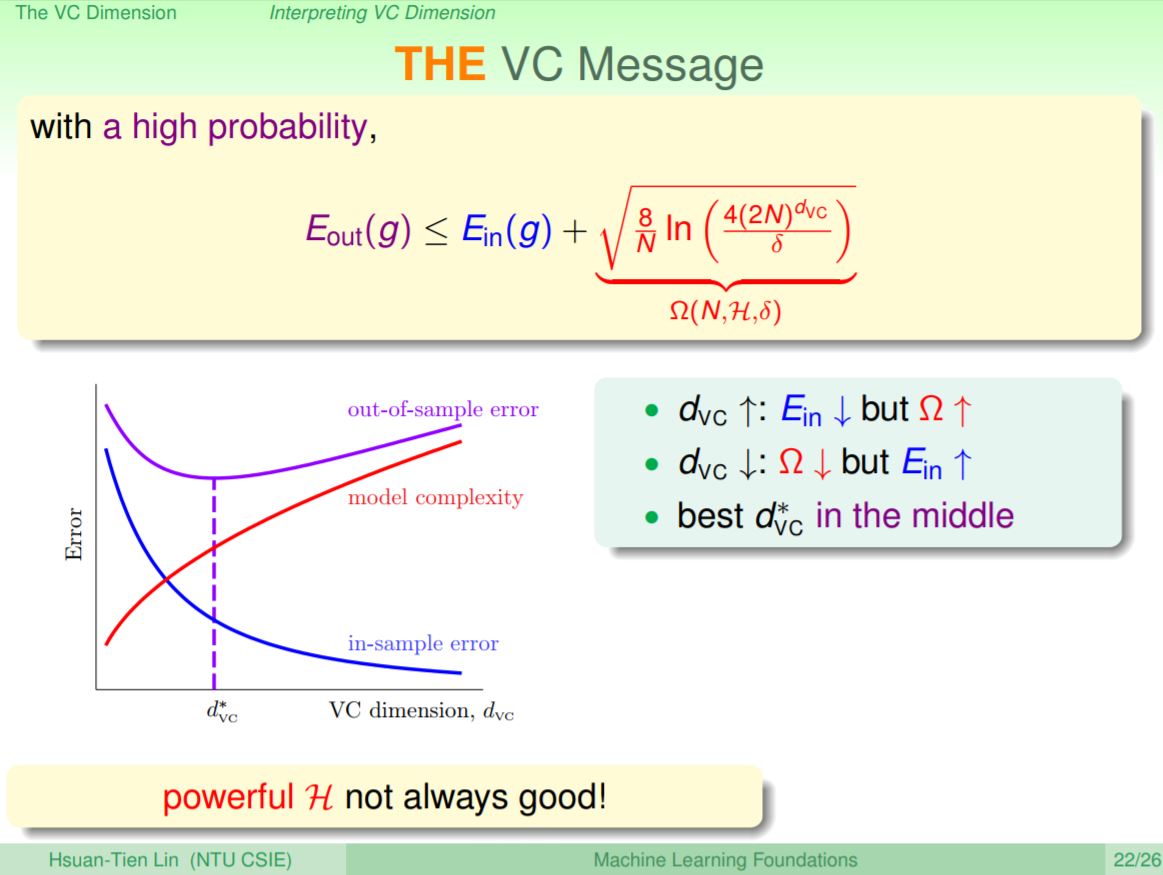
以圖示來看這個現象,其中model複雜度會隨著VC dimension越大而變大;而VC dimension越大時,排列組合也會比較多,就比較有可能找到一個更小的Ein,所以Ein會降低。但是因為model複雜度的penalty效應,Eout並不會隨著Ein持續下降,而且到達一個臨界點時轉折變成一個山谷型,所以最好的VC dimension就是中間轉折的地方。這在機器學習上的意義就是,當我們使用很強大的hypothesis或是model,也會伴隨著model複雜度提高帶來的壞處,也就是把Ein作到最好,但也可能因為model複雜度的penalty讓Eout沒辦法作到最好,在使用機器學習上都需要進行取捨的地方。

那麼到底需要多少的樣本資料,才能讓Ein和Eout很接近呢?假設今天要讓Ein和Eou相距ε為0.1而且δ壞事發生的機率為10%,如果是2D的perceptron其VC dimension為3,那需要有多少的資料才足夠呢?理論上可以推出29300筆可以滿足,大至上為10000 x dVC,但是實務上只需要10 x dVC的樣本數就足夠了。

總結這一講的內容,主要在介紹VC dimension定義為最大的non-break point,且percepron的VC dimension為d+1,VC dimension其實際意義為可自由調整的參數,且VC dimension會影響到模型和樣本的複雜度