這一講主要在延續前一講的推導,說明無限多個hypothesis到底發生什麼事情。
前面有是到如果要讓訓練是可行的,則必需要加上一些假設,首先原本訓練的資料和測試hypothesis的資料都是來自於相同的分配(Distribution),那麼當hypothesis集合是有限的,且資料數量N夠大的情況下,不論演算法A挑出哪一個函式g,Ein和Eout都會是接近的。在這個情況下,只要挑出趨近於0的Ein,就可以保證Eout也趨近於0,即代表學習是可能的。

再複習一下到目前的學習內容。證明機器學習的過程中,首先會希望得到一個函式g而且和f會很接近,也就是希望Eout(g)會接近於0。但是我們不知道該怎麼去證明Eout會接近於0,於是我們從取樣下手來證明Ein如果趨近於0的話,且Ein和Eout會很接近,那麼Eout也會趨近於0。那麼要讓機器學習可能,其中一個很大的重點是有限的hypothesis集合M,究竟這個M扮演了什麼角色?

這時我們會談到M的trade-off,所謂選擇M的trade-off就是當我們選了比較小的M才能符合Hoeffiding不等式讓壞事發生的機率降低,但這代表可以選擇的hypothesis比較少,也許這樣可能就無法選到一個好的hypothesis來讓Ein可以趨近於0。相反的,如果M越大,雖然選擇的hypothesis變多,但是壞事發生的機率也會上升。所以選擇一個正確而且適當的M對於學習問題是很重要的。

前面提到如果M是有限的集合,那麼學習才有可能發生,如果是M是無限大的話,壞事發生的機率也就是無限大,機器就沒辦法學到一個好的結果,因為其中的壞事發生的機率,就是M種發生壞事的機率相加。雖然看起來M會無限大,但事實上發生不同壞事資料D可能是一樣的。以PLA為例說明,假設選了兩條非常接近的線(即兩個hypothesis),其實這兩條線可能對於同一組資料D分出來的結果是一樣的,所以不同的壞事發生可能會有重疊的情況,所以看起來M應該是有限的。

假設平面上只有一個點,每條線都是一個hypothesis,看起來你確實可以在平面上切出無限多條線,可是事實上不管怎麼切都只會有兩種情況,即這個點不是O就是X,所以只要任何長的像H1的切線都是O,任何長的像H2的切線都是X
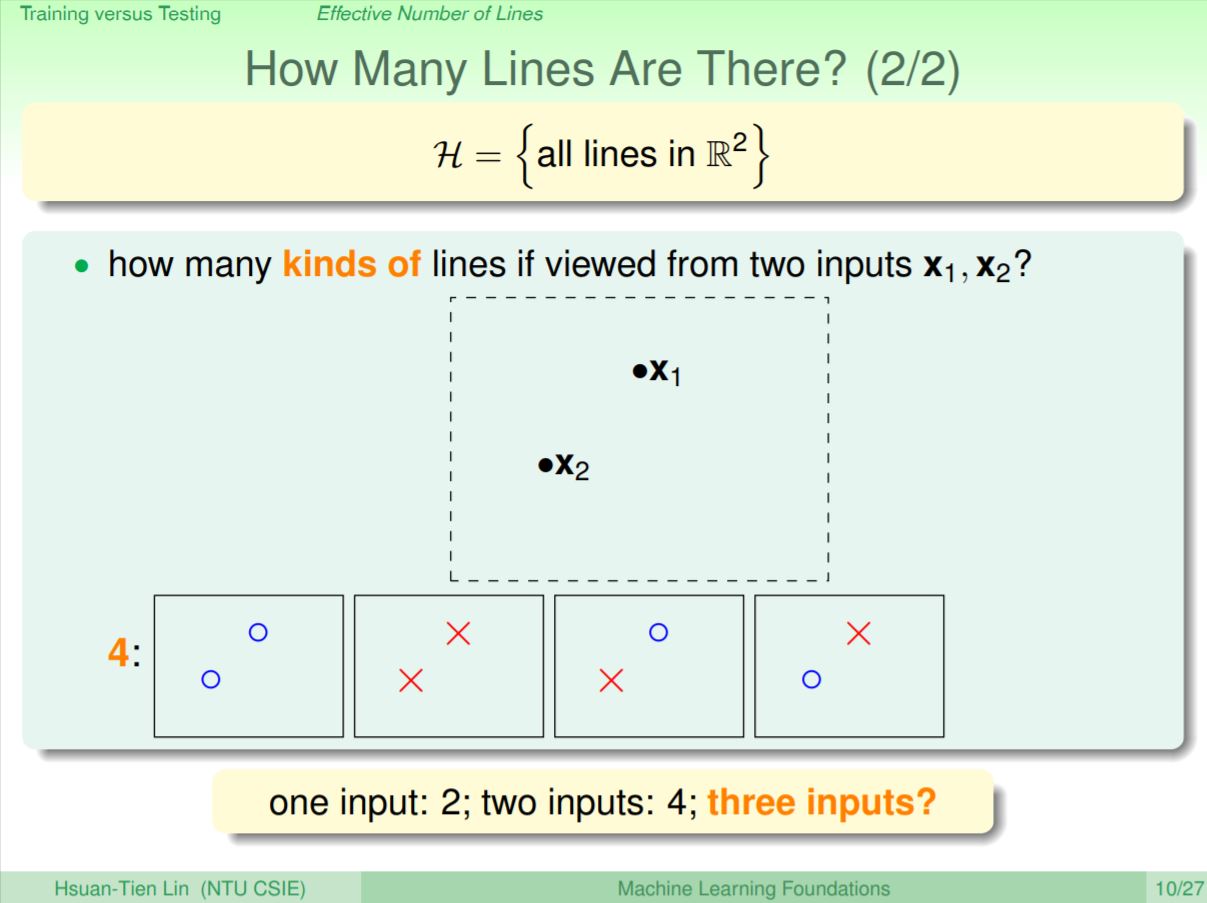
如果是兩個輸入的話,總共會有4種切線,
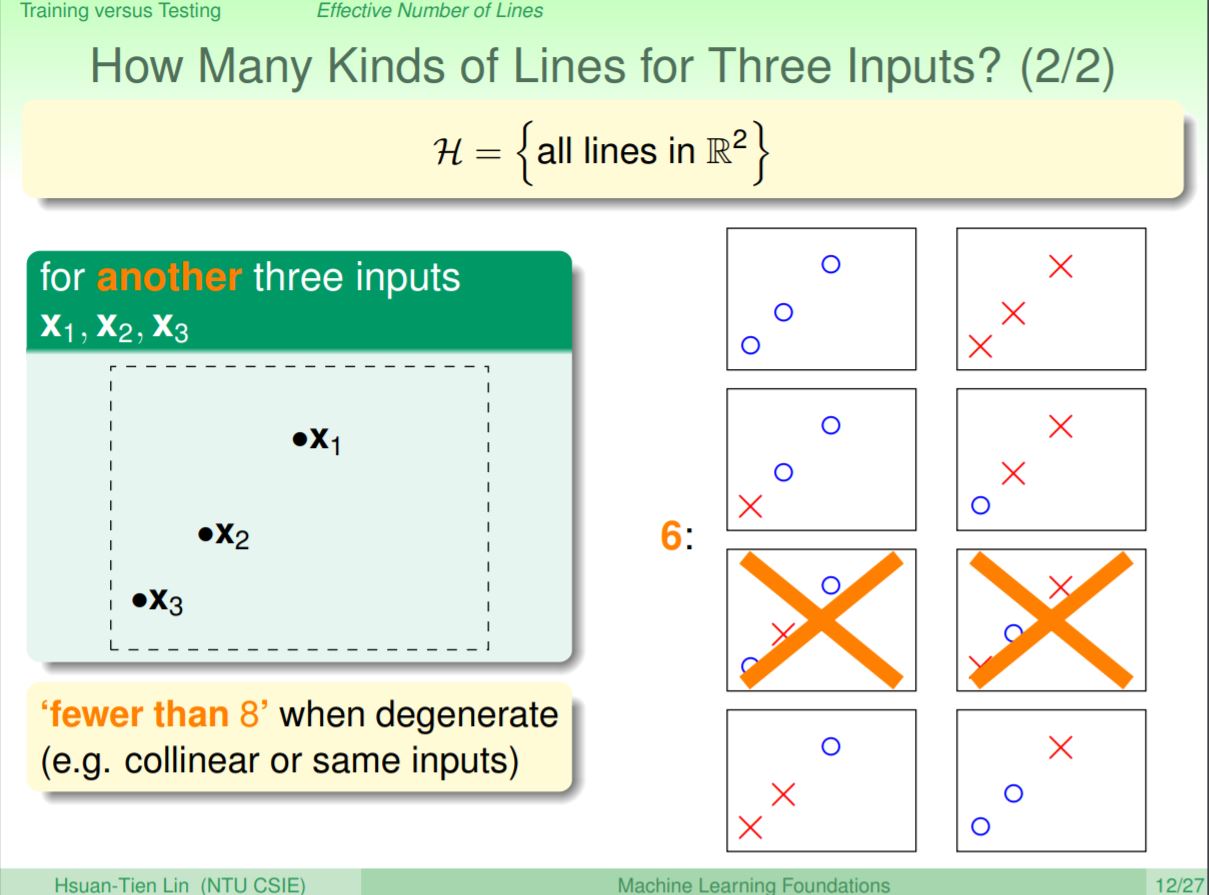
如果是3個輸入呢?看起來總共會有8種總合,但是事實上其中會有2種組合沒辦法使用直線切出來(OXO和XOX),所以實際上只會有6種切線。

這又稱為Effect Number of Lines,從表格可以發現每個輸入最多只會有2^N種組合,但是能夠有效的切出兩種分類會從3個輸入開始變少,所以我們可以把M取代成effect(N)。也就是說無論今天的M再多大,都可以找到一個有限的切線數量effect(N),而且這個effect(N)可以比2^N小很多,這樣就能夠保證學習能夠發生。

這裡講到Dichotomy的概念,所謂Dichotomy就是兩分的意思(分成O和X為一例),Dichotomy和原本的hypothesis的差別在於Dichotomy是有限的組合,而Hypothesis是平面上無限條線的任一條,接下來會把原本的M取代成有限的Dichotomy數量。

接著會透過計算成長函式(Growth Function)來找到有限的Dichotomy上限數量,取代M讓學習可以發生。

以一個最簡單的Postive Ray來說明,資料點N分佈在一維線上,當我們取一個threshold可以找到不同的Postive Ray,那麼所有可能的Dichotomy組合總共會是N+1個(就是能在點之間切線的數量),在這個問題下Dichotomy的組合大大的小於2^N種。

課程舉了四種不同的成長函數,其中PLA的Dichotomy數量mH(N)會小於2^N,但是對於Hoeffding不等式中,如果mH(N)是指數型成長,則無法確保不等式成立,所以我們需要證明mH(N)是一個多項式的成長。

這個部份提到了Break Point的概念,所謂的Break Point就是當某一個輸入開始,Dichotomy數量不再是指數成長(即2^N),像是positive ray在2個輸入時發生,postive interval在3個輸入時發生,2D perceptrons在4個輸入時發生。在這裡看到神奇的地方在於本來的沒有break point的情況下mH(N)會是指數成長,但是當有了break point後,mH(N)會是一個多項式,下一講就會開始證明是如何轉變成多項式的。