這一講的學習重點主要是在如何討論學習到底是不是可行的,並進一步推導證明機器是真的可以「學習」的。

機器會不會其實是沒辦法學習的?我們可以先看講義上的圖形,上半部的圖形屬於-1,下半部的圖形屬於+1,那麼給了f上方右邊的圖,他究竟是屬於+1還是-1呢?如果我們用黑色區域是不是對稱來判斷,那麼這張圖會是+1;但如果我們用左上角的格子是否為黑色,那邊這張圖會是-1。這裡會發現如果我們用不同的規則就可能得到不同的答案,看起來好像真的沒辦法讓機器真的「學習」一個正確的答案。

用一個比較數學的例子來看,假設今天有一個函式f,輸入是3個bit,輸出是o或是x。再來我們透過機器學習演算法學到g函式,並確保這個g函式在5筆資料D都能和f得到一樣的答案(即f和g結果相同)。所以我們確保了g和f(甚至是講義上的8個f)在D得到相同答案,但是除了D之外剩下的3種答案,g只會有一種結果。這會有什麼的影響呢?比如說當g在剩下3筆得到XOX,那麼他會和f6相同,可是我們今天是要告訴你正確的f其實是除了f6以外的函式,那麼似乎g和f答案又錯了,看起來機器好像真的沒辦法「學習」到一個正確答案。這又稱為no free lunch,如果沒有對機器學習問題加上一些限制,即我們只是單純給機器資料學習,事實上是沒辦法讓機器學出一個正確的答案的。
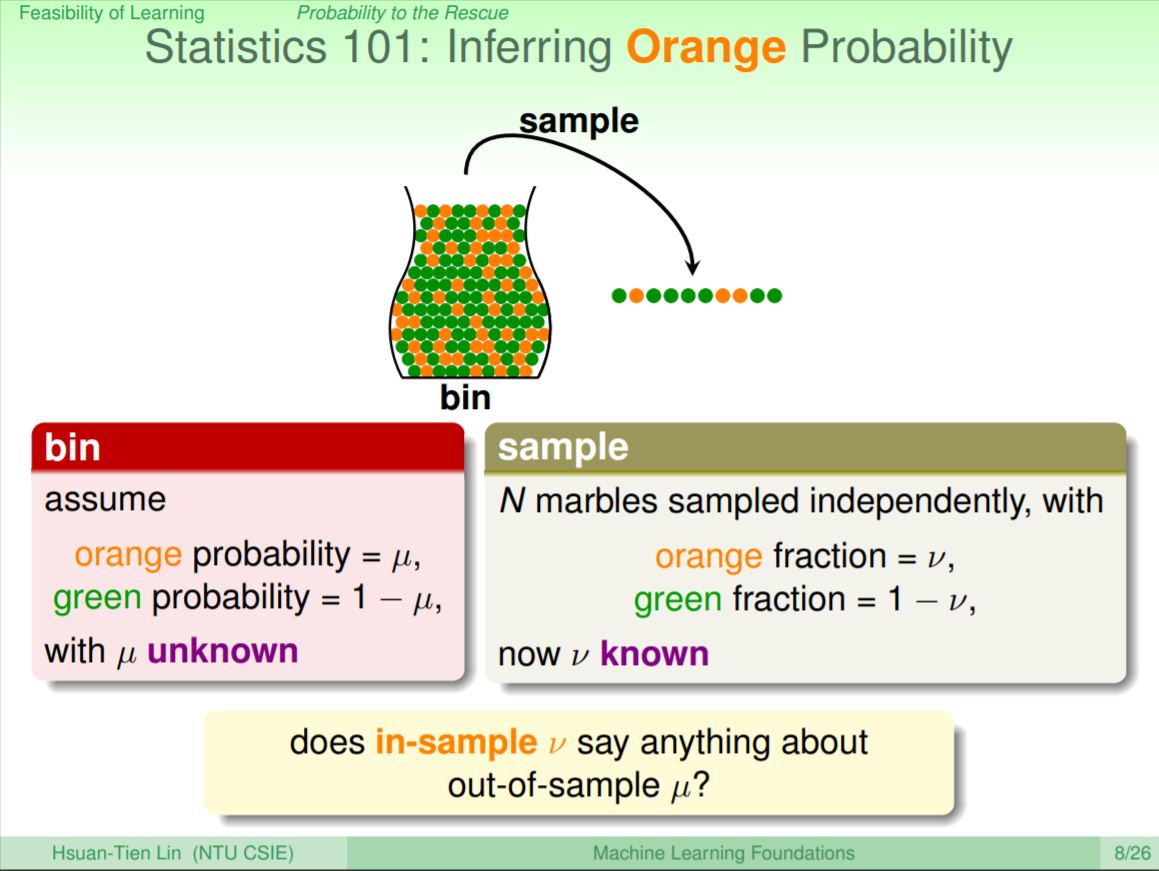
這裡舉一個推論未知的方法,比如說在一個瓶子中有綠色彈珠和橘色彈珠,如果今天沒有辦法完全數完瓶內所有的彈珠,那麼該如何去推論橘色彈珠的比例呢?我們可以透過統計手法利用取樣(樣本)的比例來推論瓶內橘色彈珠(母體)的比例。假設瓶內橘色彈珠的比例是μ,綠色是1-μ,取樣出橘色彈珠的比例是ν,綠色是1-ν,是否可以用這個ν來推論μ呢?照理說ν可能沒辦法完全的推論μ(明明有橘色彈珠,但是每一次運氣不好都抽到綠色),但是在一定的機率下,ν應該是有辦法推論μ的,在數學上可用Hoeffding’s Inequality來解釋

透過Hoeffding’s Inequality可以解釋,如果今天抽出彈珠(N)的數量越大的話,ν和μ之間差很遠的機率(ε)就會很小,也就是說如果可以取出數量夠大的樣本的話,就可以讓「壞事」(ν和μ差很多)發生的機率變小,我們可以說ν和μ大概差不多會是對的(即probably approximately correct, PAC)
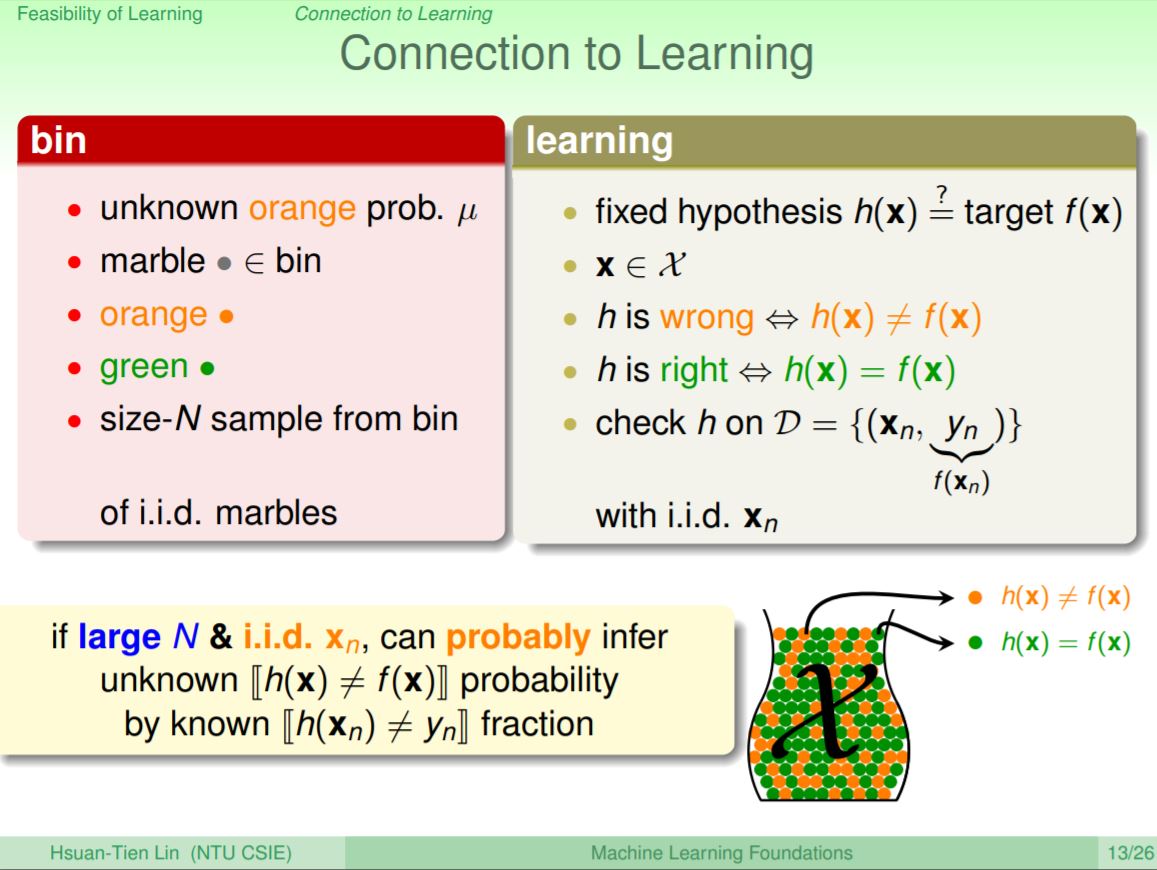
那用這個抽彈珠的例子到底和學習會有什麼關係?當把抽彈珠轉成學習的問題,未知橘色彈珠的機率μ可視為未知的f,所有抽出來的彈珠就是每筆的資料,其中橘色彈珠可視為h(x)≠f(x),即hypothesis h是錯的,綠色彈珠可視為h(x)=f(x),即hypothesis h是對的。所以如果我們在獨立的抽出彈珠時,就可知道來誰論h和f不一樣的機率到底是多少。
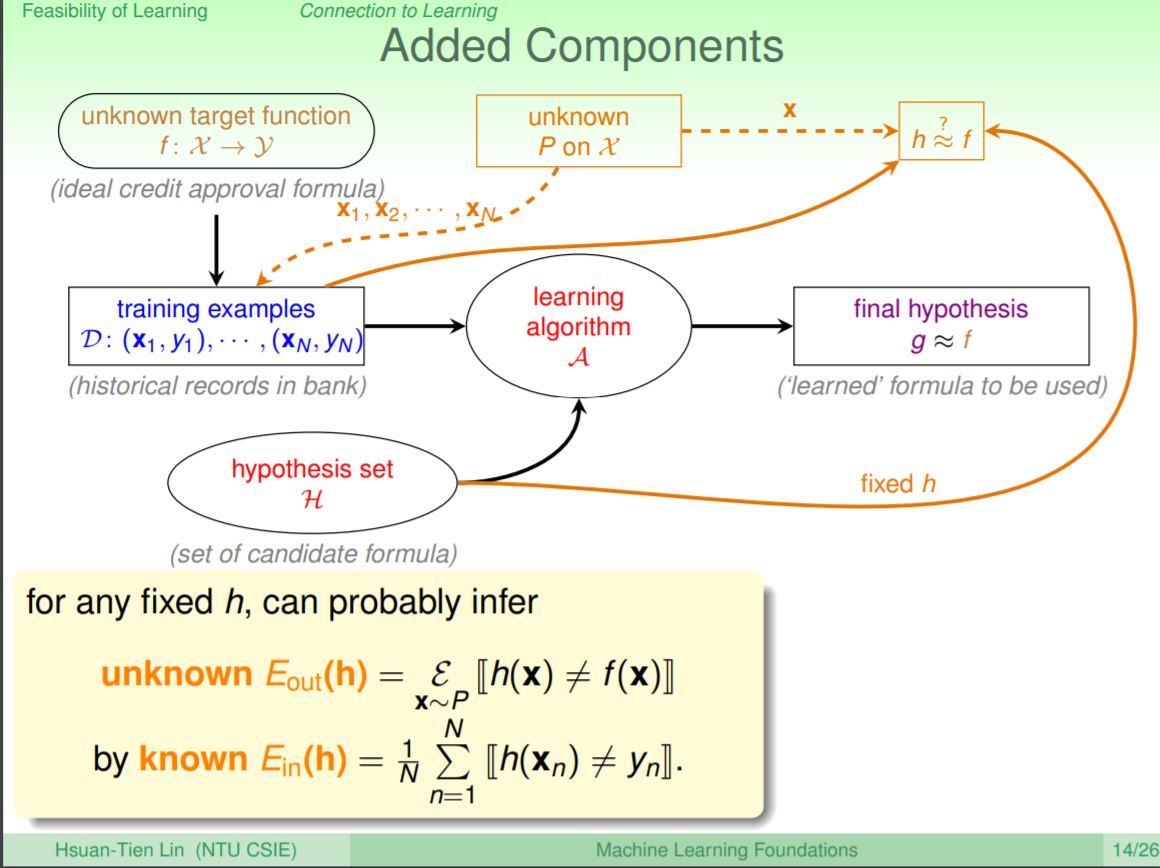
所以把前面錯誤推估的部份加入進去機器學習的流程中。首先我有一個機率在瓶子中取樣產生了資料D,在判斷h和f是不是一樣時,其中這個h就是Hypothesis集合中的其中一個

再來就可以透過手上確實知道的資料D來說h和f是否相同,也就是透過Ein(取樣的資料Error)來推論Eout(實際的瓶子的資料Error),使用Hoeffding’s Inequality就可以證明當N夠大時,Ein和Eout就會差不多是相同的。
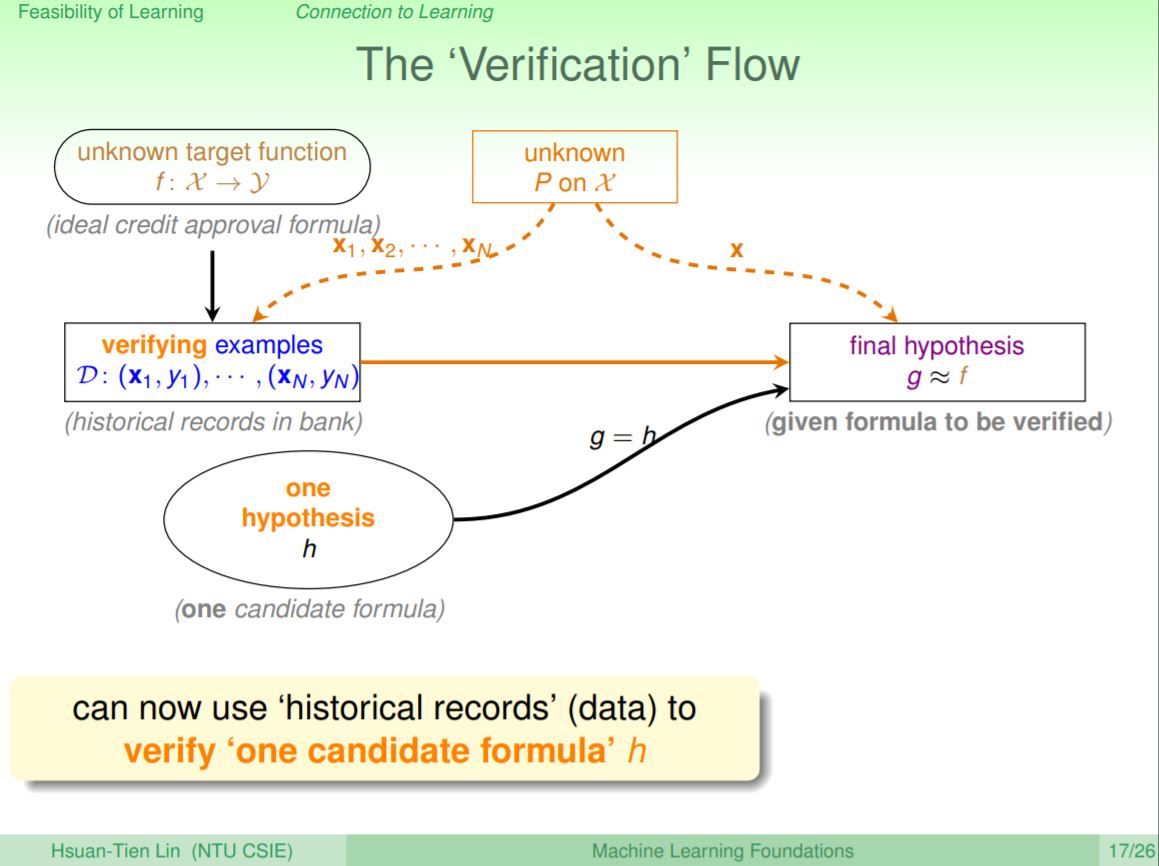
但這樣的證明充其量其能說是驗證而已,就是這個h目前還沒有辦法像是PLA一樣丟不同資料產生不同的h,但是我們可以證明這個h是不是使用資料D能夠有有用的推論f,即驗證選出h的表現是好的還是不好的。
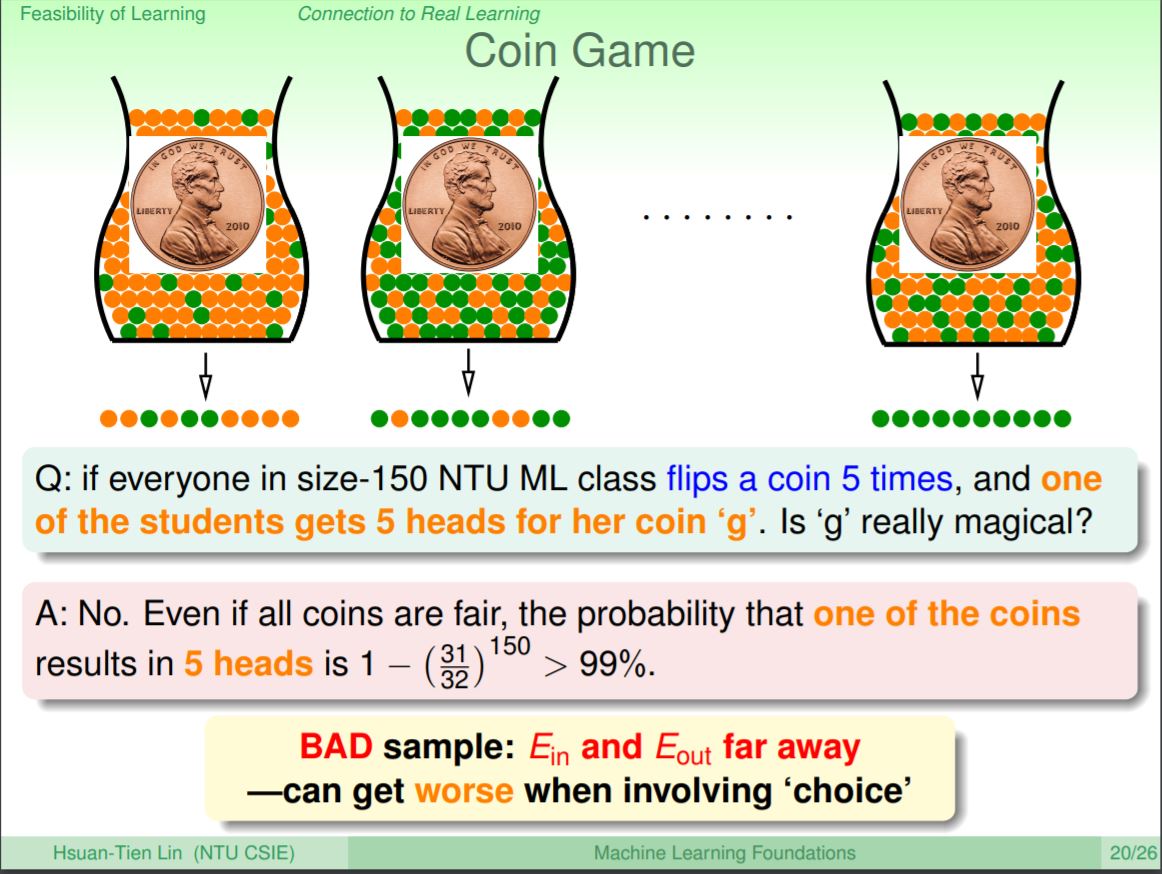
目前已經可以驗證相同h之下的表現好還是不好,但是今天當我們有了選擇時(即在多個h裡面作選擇),我們可能就會有偏見的選出一個瓶子都是綠色彈珠的結果,但事實上可能只是剛好這個瓶子都「碰巧」的抽出了綠色彈珠,就像擲銅板一樣,不論這枚銅板多麼公正,都會有可能出現每次都正面的情況。前面講到Hoeffding告訴我們的是ν和μ之間差異很大的這種「不好」的事情機率應該是很小的,但是當我們有選擇的時候,這種「不好」的取樣卻會造成Ein和Eout差距變大。
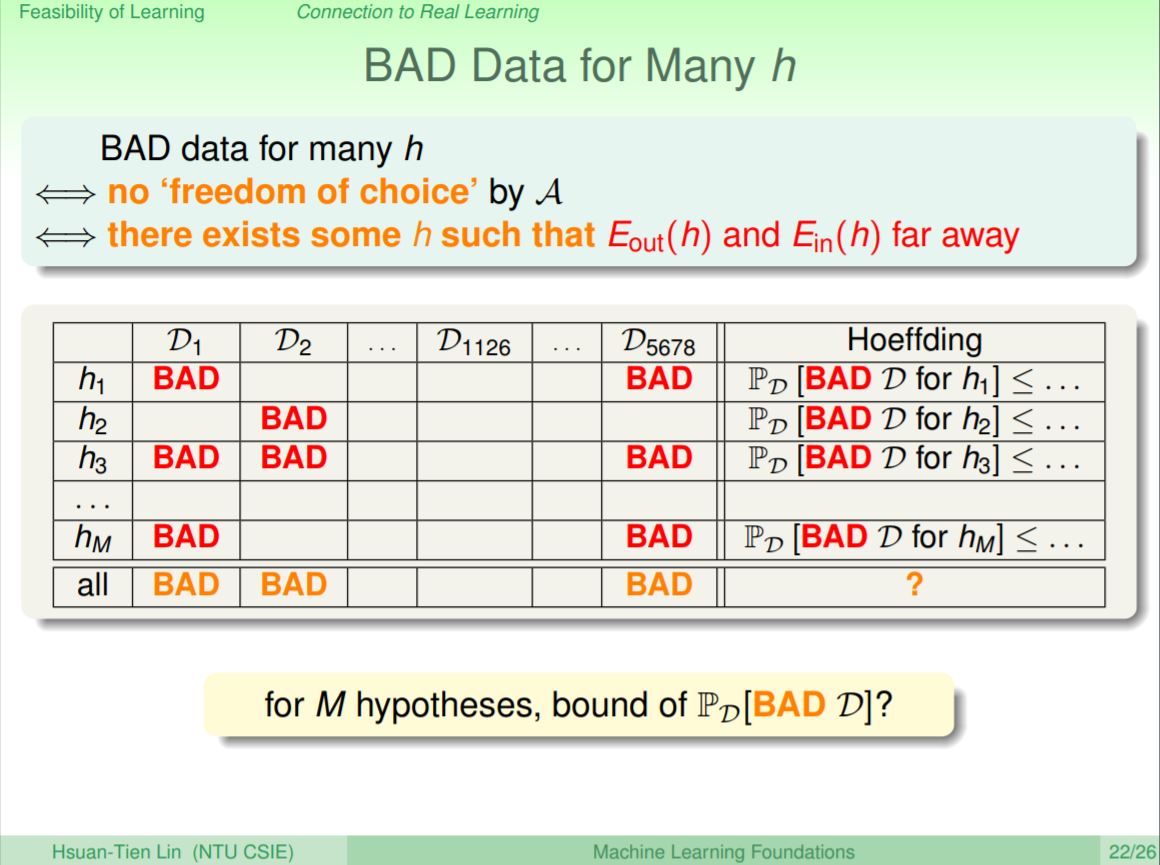
如果演算法遇到不好的資料(Ein和Eout差很遠),就會得到不好的結果。Hoeffding告訴我們的是每一個h不好的情況是很小的,但是在演算法有自由選擇h的情況下,那麼不好資料發生的機率是多少呢?

假設有M總不同的h,那麼不好資料發生的機率,就會等於每一個h發生不好機率的總合(Union Bound)。所以如果演算法有辦法選出一個最小的Ein(壞事發生的機率是最小的),就可以表示選出來的Eout會是最小的
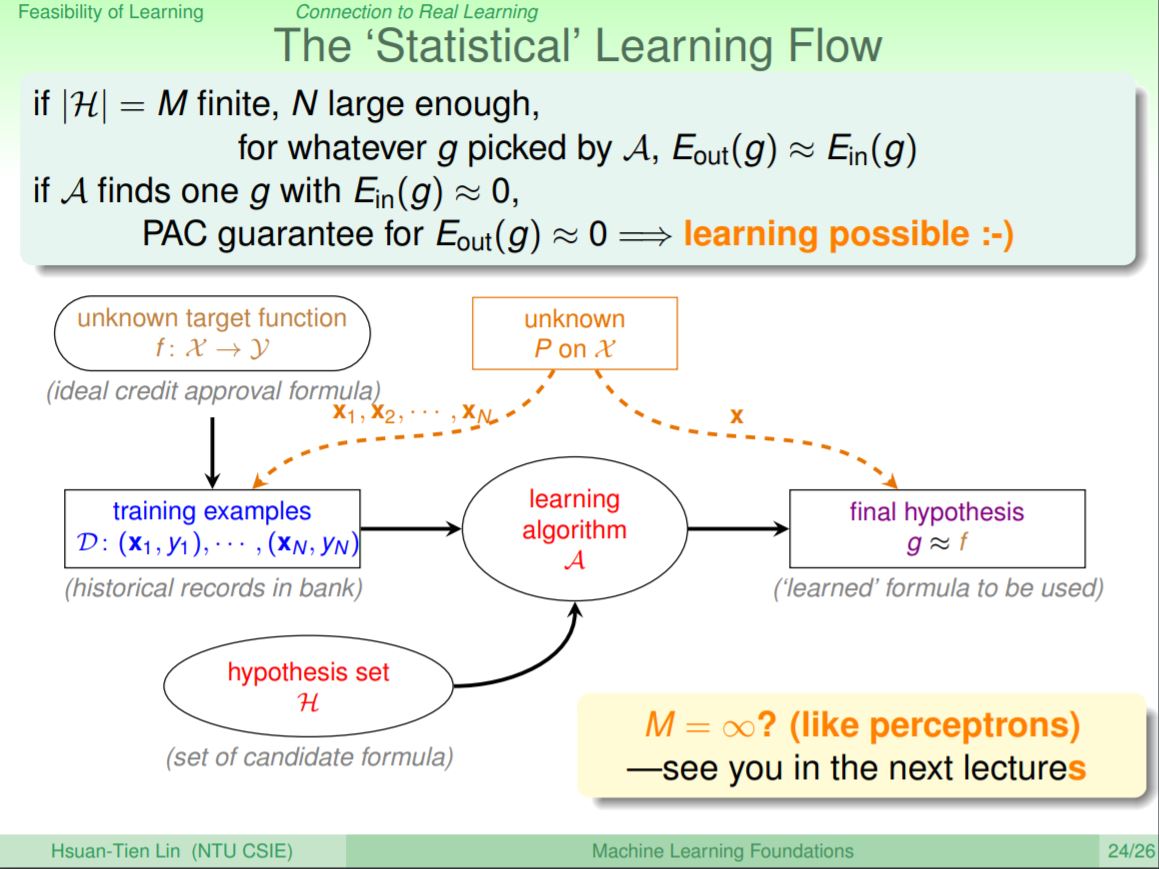
總結來說機器該如何能夠學習呢?只要滿足Hypothesis集合是有限的集合M,且樣本資料N是夠大的,對於任何被演算法選出來的g(其中一個假設h),就可以推論Eout和Ein是差不多相同的。就是剛提到的,演算法只要選出一個Ein是最小的,就可以保證Eout也是最小的。